 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSciEvalKit: An Open-source Evaluation Toolkit for Scientific General Intelligence
Dec 30, 2025We introduce SciEvalKit, a unified benchmarking toolkit designed to evaluate AI models for science across a broad range of scientific disciplines and task capabilities. Unlike general-purpose evaluation platforms, SciEvalKit focuses on the core competencies of scientific intelligence, including Scientific Multimodal Perception, Scientific Multimodal Reasoning, Scientific Multimodal Understanding, Scientific Symbolic Reasoning, Scientific Code Generation, Science Hypothesis Generation and Scientific Knowledge Understanding. It supports six major scientific domains, spanning from physics and chemistry to astronomy and materials science. SciEvalKit builds a foundation of expert-grade scientific benchmarks, curated from real-world, domain-specific datasets, ensuring that tasks reflect authentic scientific challenges. The toolkit features a flexible, extensible evaluation pipeline that enables batch evaluation across models and datasets, supports custom model and dataset integration, and provides transparent, reproducible, and comparable results. By bridging capability-based evaluation and disciplinary diversity, SciEvalKit offers a standardized yet customizable infrastructure to benchmark the next generation of scientific foundation models and intelligent agents. The toolkit is open-sourced and actively maintained to foster community-driven development and progress in AI4Science.
GSDNet: Revisiting Incomplete Multimodal-Diffusion from Graph Spectrum Perspective for Conversation Emotion Recognition
Jun 14, 2025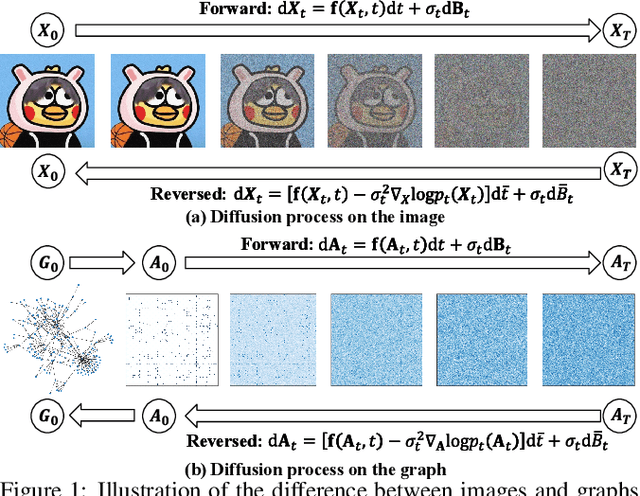
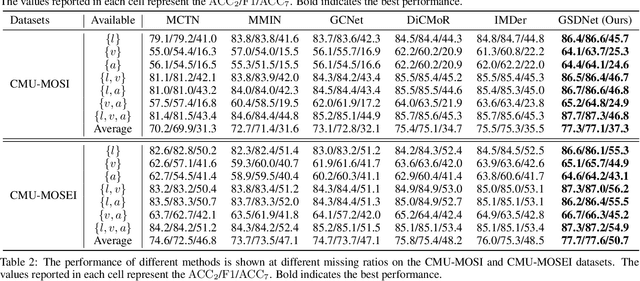
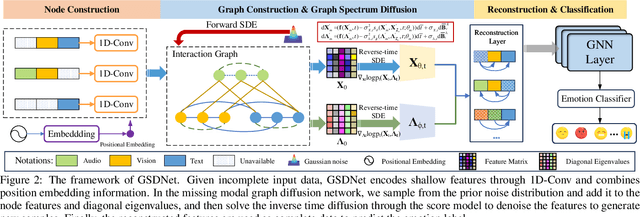
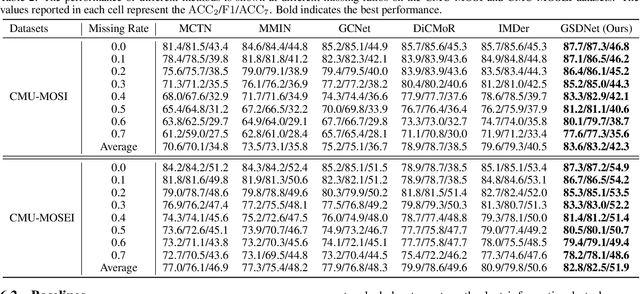
Multimodal emotion recognition in conversations (MERC) aims to infer the speaker's emotional state by analyzing utterance information from multiple sources (i.e., video, audio, and text). Compared with unimodality, a more robust utterance representation can be obtained by fusing complementary semantic information from different modalities. However, the modality missing problem severely limits the performance of MERC in practical scenarios. Recent work has achieved impressive performance on modality completion using graph neural networks and diffusion models, respectively. This inspires us to combine these two dimensions through the graph diffusion model to obtain more powerful modal recovery capabilities. Unfortunately, existing graph diffusion models may destroy the connectivity and local structure of the graph by directly adding Gaussian noise to the adjacency matrix, resulting in the generated graph data being unable to retain the semantic and topological information of the original graph. To this end, we propose a novel Graph Spectral Diffusion Network (GSDNet), which maps Gaussian noise to the graph spectral space of missing modalities and recovers the missing data according to its original distribution. Compared with previous graph diffusion methods, GSDNet only affects the eigenvalues of the adjacency matrix instead of destroying the adjacency matrix directly, which can maintain the global topological information and important spectral features during the diffusion process. Extensive experiments have demonstrated that GSDNet achieves state-of-the-art emotion recognition performance in various modality loss scenarios.
Large Language Models Orchestrating Structured Reasoning Achieve Kaggle Grandmaster Level
Nov 05, 2024



We introduce Agent K v1.0, an end-to-end autonomous data science agent designed to automate, optimise, and generalise across diverse data science tasks. Fully automated, Agent K v1.0 manages the entire data science life cycle by learning from experience. It leverages a highly flexible structured reasoning framework to enable it to dynamically process memory in a nested structure, effectively learning from accumulated experience stored to handle complex reasoning tasks. It optimises long- and short-term memory by selectively storing and retrieving key information, guiding future decisions based on environmental rewards. This iterative approach allows it to refine decisions without fine-tuning or backpropagation, achieving continuous improvement through experiential learning. We evaluate our agent's apabilities using Kaggle competitions as a case study. Following a fully automated protocol, Agent K v1.0 systematically addresses complex and multimodal data science tasks, employing Bayesian optimisation for hyperparameter tuning and feature engineering. Our new evaluation framework rigorously assesses Agent K v1.0's end-to-end capabilities to generate and send submissions starting from a Kaggle competition URL. Results demonstrate that Agent K v1.0 achieves a 92.5\% success rate across tasks, spanning tabular, computer vision, NLP, and multimodal domains. When benchmarking against 5,856 human Kaggle competitors by calculating Elo-MMR scores for each, Agent K v1.0 ranks in the top 38\%, demonstrating an overall skill level comparable to Expert-level users. Notably, its Elo-MMR score falls between the first and third quartiles of scores achieved by human Grandmasters. Furthermore, our results indicate that Agent K v1.0 has reached a performance level equivalent to Kaggle Grandmaster, with a record of 6 gold, 3 silver, and 7 bronze medals, as defined by Kaggle's progression system.
FastAttention: Extend FlashAttention2 to NPUs and Low-resource GPUs
Oct 22, 2024



FlashAttention series has been widely applied in the inference of large language models (LLMs). However, FlashAttention series only supports the high-level GPU architectures, e.g., Ampere and Hopper. At present, FlashAttention series is not easily transferrable to NPUs and low-resource GPUs. Moreover, FlashAttention series is inefficient for multi- NPUs or GPUs inference scenarios. In this work, we propose FastAttention which pioneers the adaptation of FlashAttention series for NPUs and low-resource GPUs to boost LLM inference efficiency. Specifically, we take Ascend NPUs and Volta-based GPUs as representatives for designing our FastAttention. We migrate FlashAttention series to Ascend NPUs by proposing a novel two-level tiling strategy for runtime speedup, tiling-mask strategy for memory saving and the tiling-AllReduce strategy for reducing communication overhead, respectively. Besides, we adapt FlashAttention for Volta-based GPUs by redesigning the operands layout in shared memory and introducing a simple yet effective CPU-GPU cooperative strategy for efficient memory utilization. On Ascend NPUs, our FastAttention can achieve a 10.7$\times$ speedup compared to the standard attention implementation. Llama-7B within FastAttention reaches up to 5.16$\times$ higher throughput than within the standard attention. On Volta architecture GPUs, FastAttention yields 1.43$\times$ speedup compared to its equivalents in \texttt{xformers}. Pangu-38B within FastAttention brings 1.46$\times$ end-to-end speedup using FasterTransformer. Coupled with the propose CPU-GPU cooperative strategy, FastAttention supports a maximal input length of 256K on 8 V100 GPUs. All the codes will be made available soon.
FlatQuant: Flatness Matters for LLM Quantization
Oct 12, 2024



Recently, quantization has been widely used for the compression and acceleration of large language models~(LLMs). Due to the outliers in LLMs, it is crucial to flatten weights and activations to minimize quantization error with the equally spaced quantization points. Prior research explores various pre-quantization transformations to suppress outliers, such as per-channel scaling and Hadamard transformation. However, we observe that these transformed weights and activations can still remain steep and outspread. In this paper, we propose FlatQuant (Fast and Learnable Affine Transformation), a new post-training quantization approach to enhance flatness of weights and activations. Our approach identifies optimal affine transformations tailored to each linear layer, calibrated in hours via a lightweight objective. To reduce runtime overhead, we apply Kronecker decomposition to the transformation matrices, and fuse all operations in FlatQuant into a single kernel. Extensive experiments show that FlatQuant sets up a new state-of-the-art quantization benchmark. For instance, it achieves less than $\textbf{1}\%$ accuracy drop for W4A4 quantization on the LLaMA-3-70B model, surpassing SpinQuant by $\textbf{7.5}\%$. For inference latency, FlatQuant reduces the slowdown induced by pre-quantization transformation from 0.26x of QuaRot to merely $\textbf{0.07x}$, bringing up to $\textbf{2.3x}$ speedup for prefill and $\textbf{1.7x}$ speedup for decoding, respectively. Code is available at: \url{https://github.com/ruikangliu/FlatQuant}.
Facial Affect Recognition based on Multi Architecture Encoder and Feature Fusion for the ABAW7 Challenge
Jul 17, 2024

In this paper, we present our approach to addressing the challenges of the 7th ABAW competition. The competition comprises three sub-challenges: Valence Arousal (VA) estimation, Expression (Expr) classification, and Action Unit (AU) detection. To tackle these challenges, we employ state-of-the-art models to extract powerful visual features. Subsequently, a Transformer Encoder is utilized to integrate these features for the VA, Expr, and AU sub-challenges. To mitigate the impact of varying feature dimensions, we introduce an affine module to align the features to a common dimension. Overall, our results significantly outperform the baselines.
IntactKV: Improving Large Language Model Quantization by Keeping Pivot Tokens Intact
Mar 02, 2024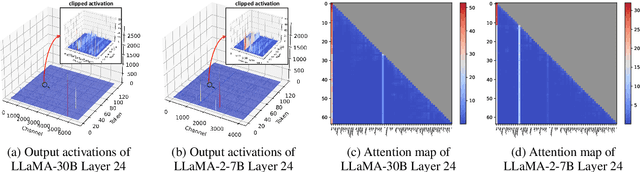
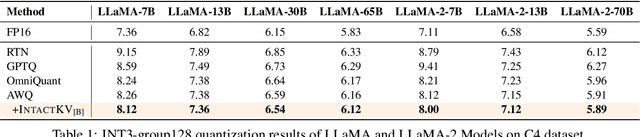

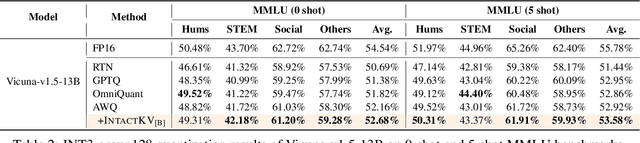
Large language models (LLMs) excel in natural language processing but demand intensive computation. To mitigate this, various quantization methods have been explored, yet they compromise LLM performance. This paper unveils a previously overlooked type of outlier in LLMs. Such outliers are found to allocate most of the attention scores on initial tokens of input, termed as pivot tokens, which is crucial to the performance of quantized LLMs. Given that, we propose IntactKV to generate the KV cache of pivot tokens losslessly from the full-precision model. The approach is simple and easy to combine with existing quantization solutions. Besides, IntactKV can be calibrated as additional LLM parameters to boost the quantized LLMs further. Mathematical analysis also proves that IntactKV effectively reduces the upper bound of quantization error. Empirical results show that IntactKV brings consistent improvement and achieves lossless weight-only INT4 quantization on various downstream tasks, leading to the new state-of-the-art for LLM quantization.
Machine Learning Insides OptVerse AI Solver: Design Principles and Applications
Jan 17, 2024
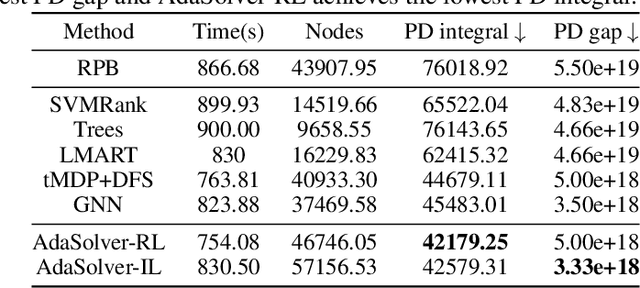

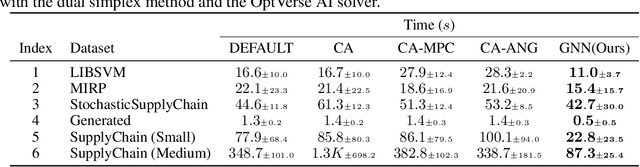
In an era of digital ubiquity, efficient resource management and decision-making are paramount across numerous industries. To this end, we present a comprehensive study on the integration of machine learning (ML) techniques into Huawei Cloud's OptVerse AI Solver, which aims to mitigate the scarcity of real-world mathematical programming instances, and to surpass the capabilities of traditional optimization techniques. We showcase our methods for generating complex SAT and MILP instances utilizing generative models that mirror multifaceted structures of real-world problem. Furthermore, we introduce a training framework leveraging augmentation policies to maintain solvers' utility in dynamic environments. Besides the data generation and augmentation, our proposed approaches also include novel ML-driven policies for personalized solver strategies, with an emphasis on applications like graph convolutional networks for initial basis selection and reinforcement learning for advanced presolving and cut selection. Additionally, we detail the incorporation of state-of-the-art parameter tuning algorithms which markedly elevate solver performance. Compared with traditional solvers such as Cplex and SCIP, our ML-augmented OptVerse AI Solver demonstrates superior speed and precision across both established benchmarks and real-world scenarios, reinforcing the practical imperative and effectiveness of machine learning techniques in mathematical programming solvers.
PanGu-$π$: Enhancing Language Model Architectures via Nonlinearity Compensation
Dec 27, 2023

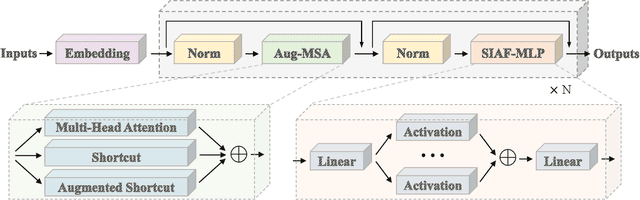

The recent trend of large language models (LLMs) is to increase the scale of both model size (\aka the number of parameters) and dataset to achieve better generative ability, which is definitely proved by a lot of work such as the famous GPT and Llama. However, large models often involve massive computational costs, and practical applications cannot afford such high prices. However, the method of constructing a strong model architecture for LLMs is rarely discussed. We first analyze the state-of-the-art language model architectures and observe the feature collapse problem. Based on the theoretical analysis, we propose that the nonlinearity is also very important for language models, which is usually studied in convolutional neural networks for vision tasks. The series informed activation function is then introduced with tiny calculations that can be ignored, and an augmented shortcut is further used to enhance the model nonlinearity. We then demonstrate that the proposed approach is significantly effective for enhancing the model nonlinearity through carefully designed ablations; thus, we present a new efficient model architecture for establishing modern, namely, PanGu-$\pi$. Experiments are then conducted using the same dataset and training strategy to compare PanGu-$\pi$ with state-of-the-art LLMs. The results show that PanGu-$\pi$-7B can achieve a comparable performance to that of benchmarks with about 10\% inference speed-up, and PanGu-$\pi$-1B can achieve state-of-the-art performance in terms of accuracy and efficiency. In addition, we have deployed PanGu-$\pi$-7B in the high-value domains of finance and law, developing an LLM named YunShan for practical application. The results show that YunShan can surpass other models with similar scales on benchmarks.
Road Genome: A Topology Reasoning Benchmark for Scene Understanding in Autonomous Driving
Apr 20, 2023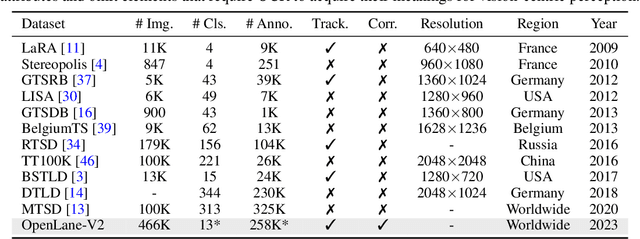
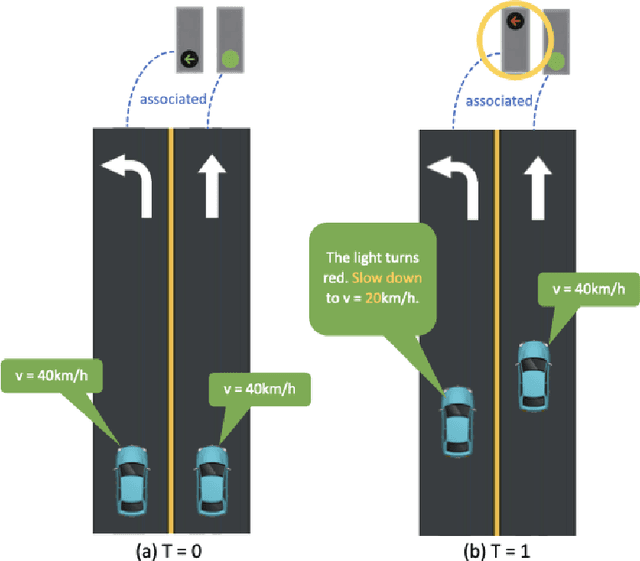
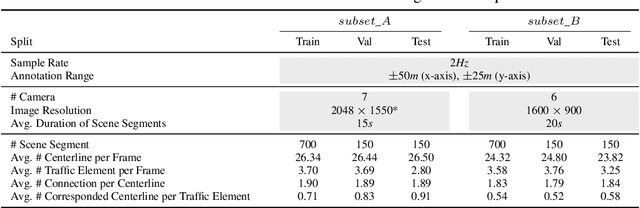
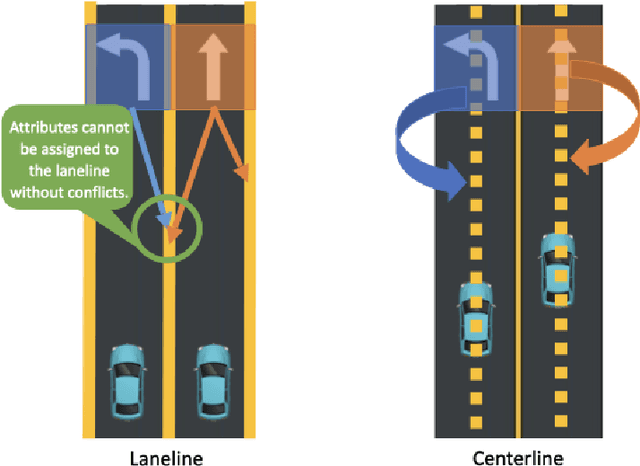
Understanding the complex traffic environment is crucial for self-driving vehicles. Existing benchmarks in autonomous driving mainly cast scene understanding as perception problems, e.g., perceiving lanelines with vanilla detection or segmentation methods. As such, we argue that the perception pipeline provides limited information for autonomous vehicles to drive in the right way, especially without the aid of high-definition (HD) map. For instance, following the wrong traffic signal at a complicated crossroad would lead to a catastrophic incident. By introducing Road Genome (OpenLane-V2), we intend to shift the community's attention and take a step further beyond perception - to the task of topology reasoning for scene structure. The goal of Road Genome is to understand the scene structure by investigating the relationship of perceived entities among traffic elements and lanes. Built on top of prevailing datasets, the newly minted benchmark comprises 2,000 sequences of multi-view images captured from diverse real-world scenarios. We annotate data with high-quality manual checks in the loop. Three subtasks compromise the gist of Road Genome, including the 3D lane detection inherited from OpenLane. We have/will host Challenges in the upcoming future at top-tiered venues.