 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiJiang: Efficient Large Language Models through Compact Kernelization
Apr 01, 2024



In an effort to reduce the computational load of Transformers, research on linear attention has gained significant momentum. However, the improvement strategies for attention mechanisms typically necessitate extensive retraining, which is impractical for large language models with a vast array of parameters. In this paper, we present DiJiang, a novel Frequency Domain Kernelization approach that enables the transformation of a pre-trained vanilla Transformer into a linear complexity model with little training costs. By employing a weighted Quasi-Monte Carlo method for sampling, the proposed approach theoretically offers superior approximation efficiency. To further reduce the training computational complexity, our kernelization is based on Discrete Cosine Transform (DCT) operations. Extensive experiments demonstrate that the proposed method achieves comparable performance to the original Transformer, but with significantly reduced training costs and much faster inference speeds. Our DiJiang-7B achieves comparable performance with LLaMA2-7B on various benchmark while requires only about 1/50 training cost. Code is available at https://github.com/YuchuanTian/DiJiang.
PanGu-$π$: Enhancing Language Model Architectures via Nonlinearity Compensation
Dec 27, 2023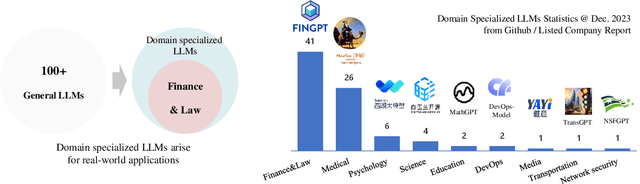

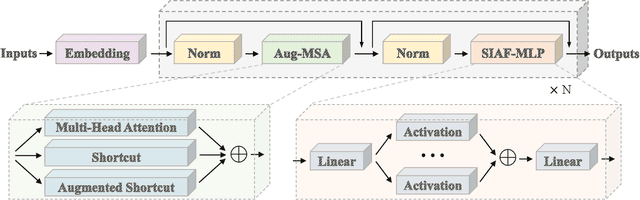

The recent trend of large language models (LLMs) is to increase the scale of both model size (\aka the number of parameters) and dataset to achieve better generative ability, which is definitely proved by a lot of work such as the famous GPT and Llama. However, large models often involve massive computational costs, and practical applications cannot afford such high prices. However, the method of constructing a strong model architecture for LLMs is rarely discussed. We first analyze the state-of-the-art language model architectures and observe the feature collapse problem. Based on the theoretical analysis, we propose that the nonlinearity is also very important for language models, which is usually studied in convolutional neural networks for vision tasks. The series informed activation function is then introduced with tiny calculations that can be ignored, and an augmented shortcut is further used to enhance the model nonlinearity. We then demonstrate that the proposed approach is significantly effective for enhancing the model nonlinearity through carefully designed ablations; thus, we present a new efficient model architecture for establishing modern, namely, PanGu-$\pi$. Experiments are then conducted using the same dataset and training strategy to compare PanGu-$\pi$ with state-of-the-art LLMs. The results show that PanGu-$\pi$-7B can achieve a comparable performance to that of benchmarks with about 10\% inference speed-up, and PanGu-$\pi$-1B can achieve state-of-the-art performance in terms of accuracy and efficiency. In addition, we have deployed PanGu-$\pi$-7B in the high-value domains of finance and law, developing an LLM named YunShan for practical application. The results show that YunShan can surpass other models with similar scales on benchmarks.
Multiscale Positive-Unlabeled Detection of AI-Generated Texts
Jun 02, 2023
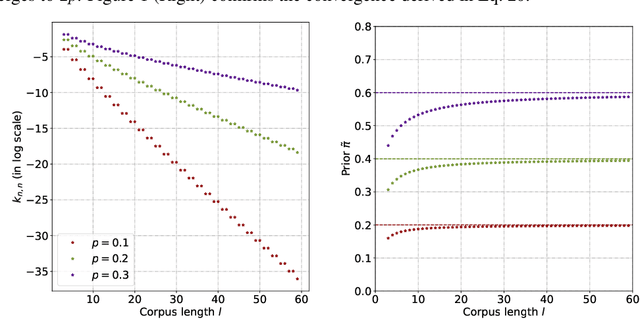


Recent releases of Large Language Models (LLMs), e.g. ChatGPT, are astonishing at generating human-like texts, but they may get misused for fake scholarly texts, fake news, fake tweets, et cetera. Previous works have proposed methods to detect these multiscale AI-generated texts, including simple ML classifiers, pretrained-model-based training-agnostic methods, and finetuned language classification models. However, mainstream detectors are formulated without considering the factor of corpus length: shorter corpuses are harder to detect compared with longer ones for shortage of informative features. In this paper, a Multiscale Positive-Unlabeled (MPU) training framework is proposed to address the challenge of multiscale text detection. Firstly, we acknowledge the human-resemblance property of short machine texts, and rephrase text classification as a Positive-Unlabeled (PU) problem by marking these short machine texts as "unlabeled" during training. In this PU context, we propose the length-sensitive Multiscale PU Loss, where we use a recurrent model in abstraction to estimate positive priors of scale-variant corpuses. Additionally, we introduce a Text Multiscaling module to enrich training corpuses. Experiments show that our MPU method augments detection performance on long AI-generated text, and significantly improves short-corpus detection of language model detectors. Language Models trained with MPU could outcompete existing detectors by large margins on multiscale AI-generated texts. The codes are available at https://github.com/mindspore-lab/mindone/tree/master/examples/detect_chatgpt and https://github.com/YuchuanTian/AIGC_text_detector.