 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeC-MOP: Integrating Momentum and Boundary-Aware Clustering for Enhanced Prompt Evolution
Feb 11, 2026Automatic prompt optimization is a promising direction to boost the performance of Large Language Models (LLMs). However, existing methods often suffer from noisy and conflicting update signals. In this research, we propose C-MOP (Cluster-based Momentum Optimized Prompting), a framework that stabilizes optimization via Boundary-Aware Contrastive Sampling (BACS) and Momentum-Guided Semantic Clustering (MGSC). Specifically, BACS utilizes batch-level information to mine tripartite features--Hard Negatives, Anchors, and Boundary Pairs--to precisely characterize the typical representation and decision boundaries of positive and negative prompt samples. To resolve semantic conflicts, MGSC introduces a textual momentum mechanism with temporal decay that distills persistent consensus from fluctuating gradients across iterations. Extensive experiments demonstrate that C-MOP consistently outperforms SOTA baselines like PromptWizard and ProTeGi, yielding average gains of 1.58% and 3.35%. Notably, C-MOP enables a general LLM with 3B activated parameters to surpass a 70B domain-specific dense LLM, highlighting its effectiveness in driving precise prompt evolution. The code is available at https://github.com/huawei-noah/noah-research/tree/master/C-MOP.
Towards Lossless Ultimate Vision Token Compression for VLMs
Dec 09, 2025Visual language models encounter challenges in computational efficiency and latency, primarily due to the substantial redundancy in the token representations of high-resolution images and videos. Current attention/similarity-based compression algorithms suffer from either position bias or class imbalance, leading to significant accuracy degradation. They also fail to generalize to shallow LLM layers, which exhibit weaker cross-modal interactions. To address this, we extend token compression to the visual encoder through an effective iterative merging scheme that is orthogonal in spatial axes to accelerate the computation across the entire VLM. Furthermoer, we integrate a spectrum pruning unit into LLM through an attention/similarity-free low-pass filter, which gradually prunes redundant visual tokens and is fully compatible to modern FlashAttention. On this basis, we propose Lossless Ultimate Vision tokens Compression (LUVC) framework. LUVC systematically compresses visual tokens until complete elimination at the final layer of LLM, so that the high-dimensional visual features are gradually fused into the multimodal queries. The experiments show that LUVC achieves a 2 speedup inference in language model with negligible accuracy degradation, and the training-free characteristic enables immediate deployment across multiple VLMs.
Positional Preservation Embedding for Multimodal Large Language Models
Oct 27, 2025Multimodal large language models (MLLMs) have achieved strong performance on vision-language tasks, yet often suffer from inefficiencies due to redundant visual tokens. Existing token merging methods reduce sequence length but frequently disrupt spatial layouts and temporal continuity by disregarding positional relationships. In this work, we propose a novel encoding operator dubbed as \textbf{P}ositional \textbf{P}reservation \textbf{E}mbedding (\textbf{PPE}), which has the main hallmark of preservation of spatiotemporal structure during visual token compression. PPE explicitly introduces the disentangled encoding of 3D positions in the token dimension, enabling each compressed token to encapsulate different positions from multiple original tokens. Furthermore, we show that PPE can effectively support cascade clustering -- a progressive token compression strategy that leads to better performance retention. PPE is a parameter-free and generic operator that can be seamlessly integrated into existing token merging methods without any adjustments. Applied to state-of-the-art token merging framework, PPE achieves consistent improvements of $2\%\sim5\%$ across multiple vision-language benchmarks, including MMBench (general vision understanding), TextVQA (layout understanding) and VideoMME (temporal understanding). These results demonstrate that preserving positional cues is critical for efficient and effective MLLM reasoning.
Pangu Embedded: An Efficient Dual-system LLM Reasoner with Metacognition
May 29, 2025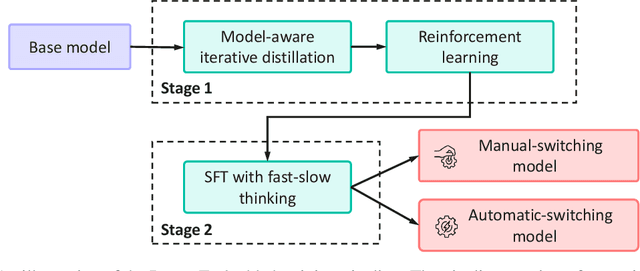

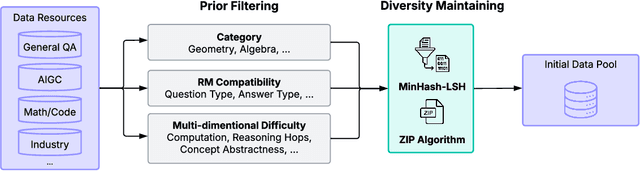
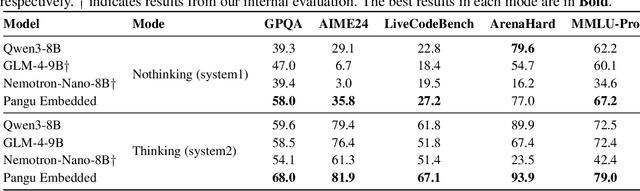
This work presents Pangu Embedded, an efficient Large Language Model (LLM) reasoner developed on Ascend Neural Processing Units (NPUs), featuring flexible fast and slow thinking capabilities. Pangu Embedded addresses the significant computational costs and inference latency challenges prevalent in existing reasoning-optimized LLMs. We propose a two-stage training framework for its construction. In Stage 1, the model is finetuned via an iterative distillation process, incorporating inter-iteration model merging to effectively aggregate complementary knowledge. This is followed by reinforcement learning on Ascend clusters, optimized by a latency-tolerant scheduler that combines stale synchronous parallelism with prioritized data queues. The RL process is guided by a Multi-source Adaptive Reward System (MARS), which generates dynamic, task-specific reward signals using deterministic metrics and lightweight LLM evaluators for mathematics, coding, and general problem-solving tasks. Stage 2 introduces a dual-system framework, endowing Pangu Embedded with a "fast" mode for routine queries and a deeper "slow" mode for complex inference. This framework offers both manual mode switching for user control and an automatic, complexity-aware mode selection mechanism that dynamically allocates computational resources to balance latency and reasoning depth. Experimental results on benchmarks including AIME 2024, GPQA, and LiveCodeBench demonstrate that Pangu Embedded with 7B parameters, outperforms similar-size models like Qwen3-8B and GLM4-9B. It delivers rapid responses and state-of-the-art reasoning quality within a single, unified model architecture, highlighting a promising direction for developing powerful yet practically deployable LLM reasoners.
Single Domain Generalization for Few-Shot Counting via Universal Representation Matching
May 22, 2025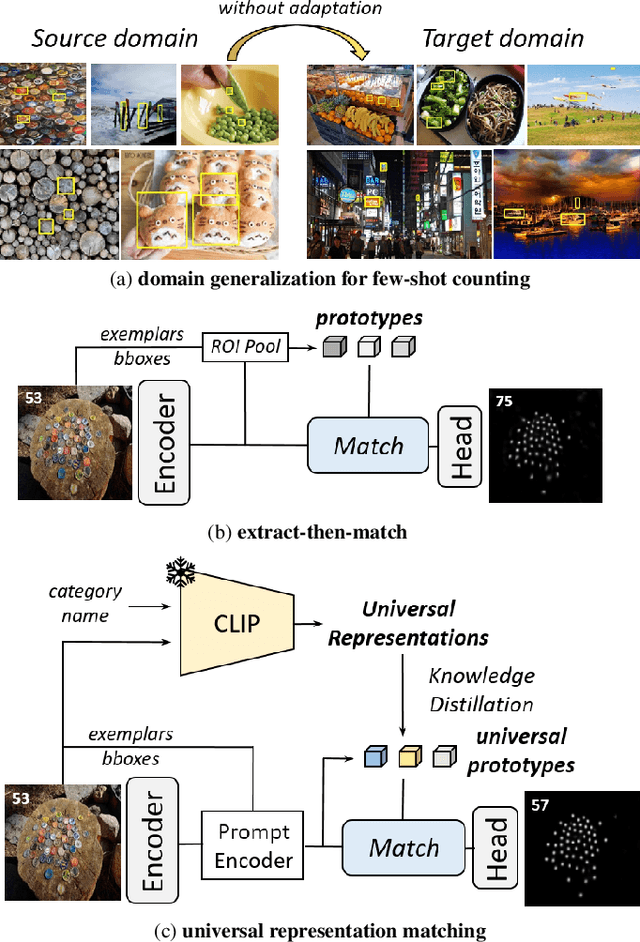
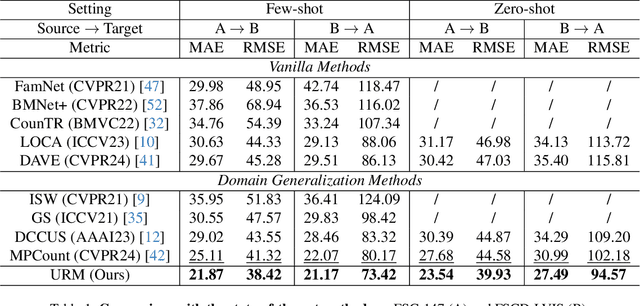

Few-shot counting estimates the number of target objects in an image using only a few annotated exemplars. However, domain shift severely hinders existing methods to generalize to unseen scenarios. This falls into the realm of single domain generalization that remains unexplored in few-shot counting. To solve this problem, we begin by analyzing the main limitations of current methods, which typically follow a standard pipeline that extract the object prototypes from exemplars and then match them with image feature to construct the correlation map. We argue that existing methods overlook the significance of learning highly generalized prototypes. Building on this insight, we propose the first single domain generalization few-shot counting model, Universal Representation Matching, termed URM. Our primary contribution is the discovery that incorporating universal vision-language representations distilled from a large scale pretrained vision-language model into the correlation construction process substantially improves robustness to domain shifts without compromising in domain performance. As a result, URM achieves state-of-the-art performance on both in domain and the newly introduced domain generalization setting.
EAM: Enhancing Anything with Diffusion Transformers for Blind Super-Resolution
May 08, 2025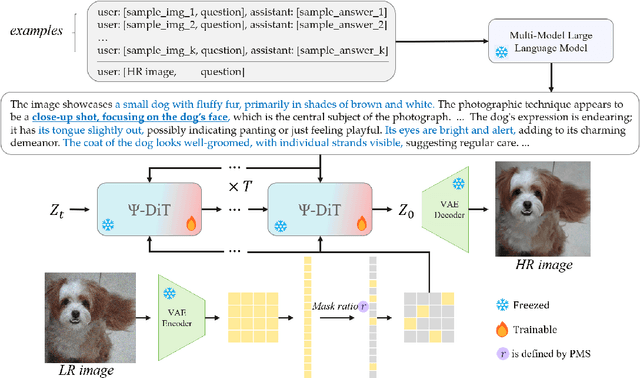
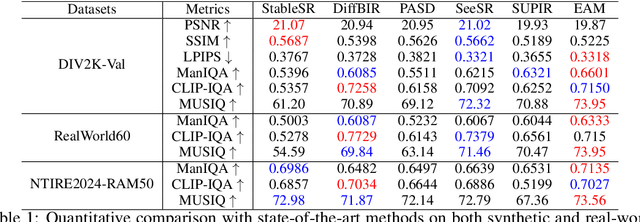
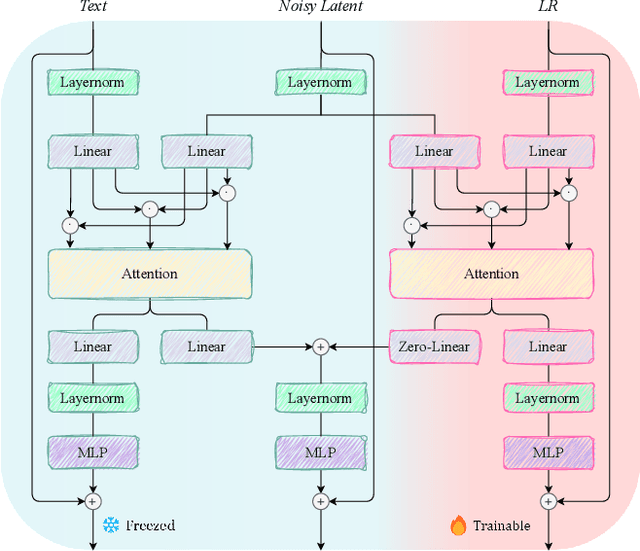

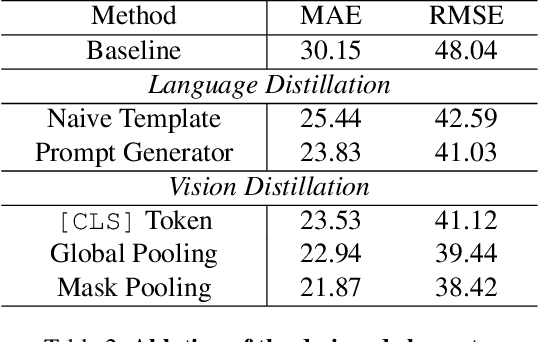
Utilizing pre-trained Text-to-Image (T2I) diffusion models to guide Blind Super-Resolution (BSR) has become a predominant approach in the field. While T2I models have traditionally relied on U-Net architectures, recent advancements have demonstrated that Diffusion Transformers (DiT) achieve significantly higher performance in this domain. In this work, we introduce Enhancing Anything Model (EAM), a novel BSR method that leverages DiT and outperforms previous U-Net-based approaches. We introduce a novel block, $\Psi$-DiT, which effectively guides the DiT to enhance image restoration. This block employs a low-resolution latent as a separable flow injection control, forming a triple-flow architecture that effectively leverages the prior knowledge embedded in the pre-trained DiT. To fully exploit the prior guidance capabilities of T2I models and enhance their generalization in BSR, we introduce a progressive Masked Image Modeling strategy, which also reduces training costs. Additionally, we propose a subject-aware prompt generation strategy that employs a robust multi-modal model in an in-context learning framework. This strategy automatically identifies key image areas, provides detailed descriptions, and optimizes the utilization of T2I diffusion priors. Our experiments demonstrate that EAM achieves state-of-the-art results across multiple datasets, outperforming existing methods in both quantitative metrics and visual quality.
Transferable text data distillation by trajectory matching
Apr 14, 2025
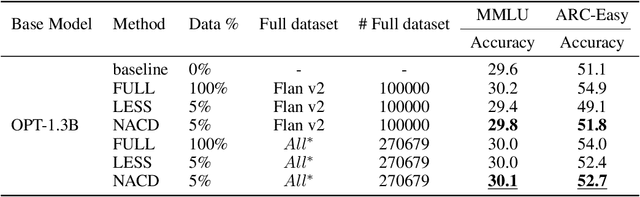
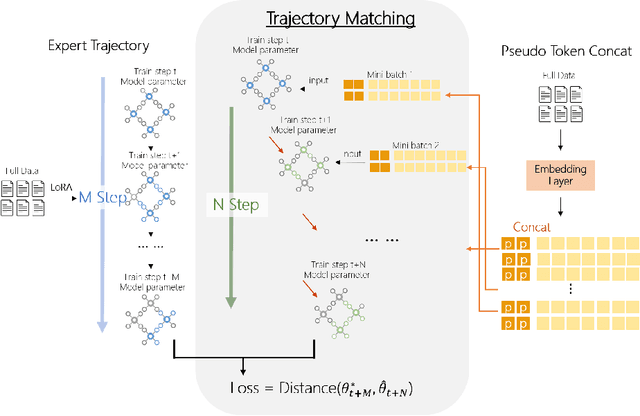
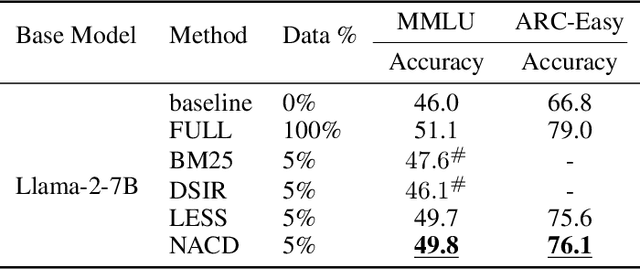
In the realm of large language model (LLM), as the size of large models increases, it also brings higher training costs. There is a urgent need to minimize the data size in LLM training. Compared with data selection method, the data distillation method aims to synthesize a small number of data samples to achieve the training effect of the full data set and has better flexibility. Despite its successes in computer vision, the discreteness of text data has hitherto stymied its exploration in natural language processing (NLP). In this work, we proposed a method that involves learning pseudo prompt data based on trajectory matching and finding its nearest neighbor ID to achieve cross-architecture transfer. During the distillation process, we introduce a regularization loss to improve the robustness of our distilled data. To our best knowledge, this is the first data distillation work suitable for text generation tasks such as instruction tuning. Evaluations on two benchmarks, including ARC-Easy and MMLU instruction tuning datasets, established the superiority of our distillation approach over the SOTA data selection method LESS. Furthermore, our method demonstrates a good transferability over LLM structures (i.e., OPT to Llama).
Saliency-driven Dynamic Token Pruning for Large Language Models
Apr 09, 2025
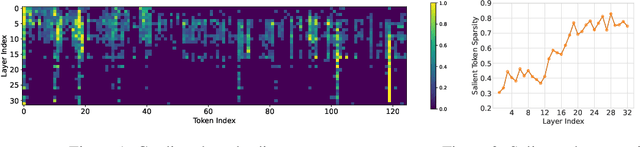
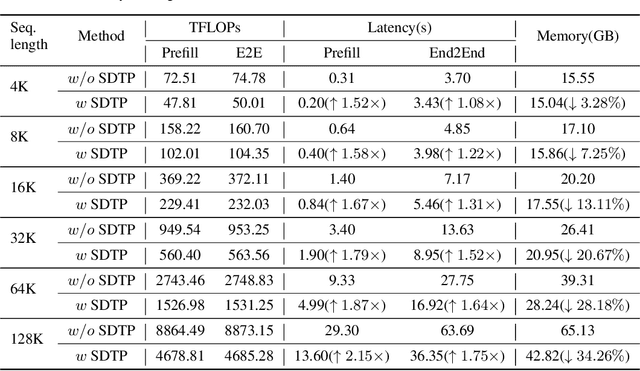
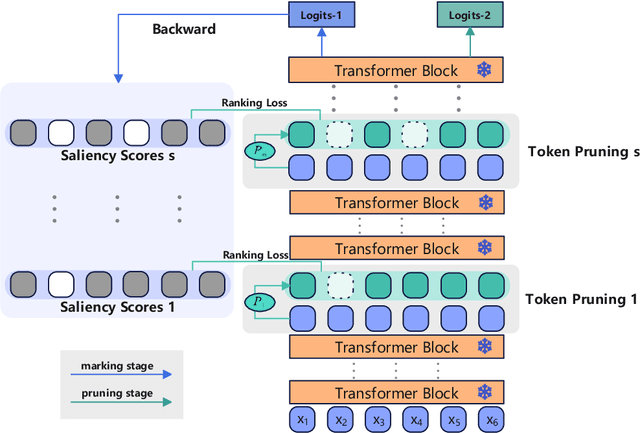
Despite the recent success of large language models (LLMs), LLMs are particularly challenging in long-sequence inference scenarios due to the quadratic computational complexity of the attention mechanism. Inspired by the interpretability theory of feature attribution in neural network models, we observe that not all tokens have the same contribution. Based on this observation, we propose a novel token pruning framework, namely Saliency-driven Dynamic Token Pruning (SDTP), to gradually and dynamically prune redundant tokens based on the input context. Specifically, a lightweight saliency-driven prediction module is designed to estimate the importance score of each token with its hidden state, which is added to different layers of the LLM to hierarchically prune redundant tokens. Furthermore, a ranking-based optimization strategy is proposed to minimize the ranking divergence of the saliency score and the predicted importance score. Extensive experiments have shown that our framework is generalizable to various models and datasets. By hierarchically pruning 65\% of the input tokens, our method greatly reduces 33\% $\sim$ 47\% FLOPs and achieves speedup up to 1.75$\times$ during inference, while maintaining comparable performance. We further demonstrate that SDTP can be combined with KV cache compression method for further compression.
GenVidBench: A Challenging Benchmark for Detecting AI-Generated Video
Jan 20, 2025



The rapid advancement of video generation models has made it increasingly challenging to distinguish AI-generated videos from real ones. This issue underscores the urgent need for effective AI-generated video detectors to prevent the dissemination of false information through such videos. However, the development of high-performance generative video detectors is currently impeded by the lack of large-scale, high-quality datasets specifically designed for generative video detection. To this end, we introduce GenVidBench, a challenging AI-generated video detection dataset with several key advantages: 1) Cross Source and Cross Generator: The cross-generation source mitigates the interference of video content on the detection. The cross-generator ensures diversity in video attributes between the training and test sets, preventing them from being overly similar. 2) State-of-the-Art Video Generators: The dataset includes videos from 8 state-of-the-art AI video generators, ensuring that it covers the latest advancements in the field of video generation. 3) Rich Semantics: The videos in GenVidBench are analyzed from multiple dimensions and classified into various semantic categories based on their content. This classification ensures that the dataset is not only large but also diverse, aiding in the development of more generalized and effective detection models. We conduct a comprehensive evaluation of different advanced video generators and present a challenging setting. Additionally, we present rich experimental results including advanced video classification models as baselines. With the GenVidBench, researchers can efficiently develop and evaluate AI-generated video detection models. Datasets and code are available at https://genvidbench.github.io.
Omni-Dimensional Frequency Learner for General Time Series Analysis
Jul 15, 2024



Frequency domain representation of time series feature offers a concise representation for handling real-world time series data with inherent complexity and dynamic nature. However, current frequency-based methods with complex operations still fall short of state-of-the-art time domain methods for general time series analysis. In this work, we present Omni-Dimensional Frequency Learner (ODFL) model based on a in depth analysis among all the three aspects of the spectrum feature: channel redundancy property among the frequency dimension, the sparse and un-salient frequency energy distribution among the frequency dimension, and the semantic diversity among the variable dimension. Technically, our method is composed of a semantic-adaptive global filter with attention to the un-salient frequency bands and partial operation among the channel dimension. Empirical results show that ODFL achieves consistent state-of-the-art in five mainstream time series analysis tasks, including short- and long-term forecasting, imputation, classification, and anomaly detection, offering a promising foundation for time series analysis.