 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevealing the Power of Post-Training for Small Language Models via Knowledge Distillation
Sep 30, 2025The rapid advancement of large language models (LLMs) has significantly advanced the capabilities of artificial intelligence across various domains. However, their massive scale and high computational costs render them unsuitable for direct deployment in resource-constrained edge environments. This creates a critical need for high-performance small models that can operate efficiently at the edge. Yet, after pre-training alone, these smaller models often fail to meet the performance requirements of complex tasks. To bridge this gap, we introduce a systematic post-training pipeline that efficiently enhances small model accuracy. Our post training pipeline consists of curriculum-based supervised fine-tuning (SFT) and offline on-policy knowledge distillation. The resulting instruction-tuned model achieves state-of-the-art performance among billion-parameter models, demonstrating strong generalization under strict hardware constraints while maintaining competitive accuracy across a variety of tasks. This work provides a practical and efficient solution for developing high-performance language models on Ascend edge devices.
Pangu Embedded: An Efficient Dual-system LLM Reasoner with Metacognition
May 29, 2025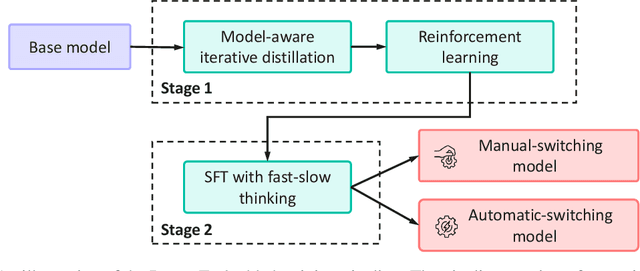

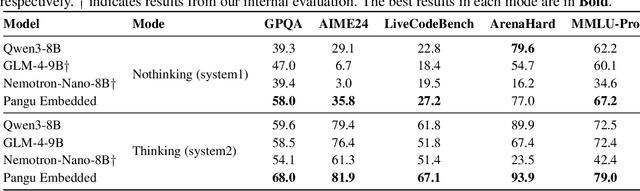
This work presents Pangu Embedded, an efficient Large Language Model (LLM) reasoner developed on Ascend Neural Processing Units (NPUs), featuring flexible fast and slow thinking capabilities. Pangu Embedded addresses the significant computational costs and inference latency challenges prevalent in existing reasoning-optimized LLMs. We propose a two-stage training framework for its construction. In Stage 1, the model is finetuned via an iterative distillation process, incorporating inter-iteration model merging to effectively aggregate complementary knowledge. This is followed by reinforcement learning on Ascend clusters, optimized by a latency-tolerant scheduler that combines stale synchronous parallelism with prioritized data queues. The RL process is guided by a Multi-source Adaptive Reward System (MARS), which generates dynamic, task-specific reward signals using deterministic metrics and lightweight LLM evaluators for mathematics, coding, and general problem-solving tasks. Stage 2 introduces a dual-system framework, endowing Pangu Embedded with a "fast" mode for routine queries and a deeper "slow" mode for complex inference. This framework offers both manual mode switching for user control and an automatic, complexity-aware mode selection mechanism that dynamically allocates computational resources to balance latency and reasoning depth. Experimental results on benchmarks including AIME 2024, GPQA, and LiveCodeBench demonstrate that Pangu Embedded with 7B parameters, outperforms similar-size models like Qwen3-8B and GLM4-9B. It delivers rapid responses and state-of-the-art reasoning quality within a single, unified model architecture, highlighting a promising direction for developing powerful yet practically deployable LLM reasoners.
Eve: Efficient Multimodal Vision Language Models with Elastic Visual Experts
Jan 08, 2025



Multimodal vision language models (VLMs) have made significant progress with the support of continuously increasing model sizes and data volumes. Running VLMs on edge devices has become a challenge for their widespread application. There are several efficient VLM efforts, but they often sacrifice linguistic capabilities to enhance multimodal abilities, or require extensive training. To address this quandary,we introduce the innovative framework of Efficient Vision Language Models with Elastic Visual Experts (Eve). By strategically incorporating adaptable visual expertise at multiple stages of training, Eve strikes a balance between preserving linguistic abilities and augmenting multimodal capabilities. This balanced approach results in a versatile model with only 1.8B parameters that delivers significant improvements in both multimodal and linguistic tasks. Notably, in configurations below 3B parameters, Eve distinctly outperforms in language benchmarks and achieves state-of-the-art results 68.87% in VLM Benchmarks. Additionally, its multimodal accuracy outstrips that of the larger 7B LLaVA-1.5 model.
Forest-of-Thought: Scaling Test-Time Compute for Enhancing LLM Reasoning
Dec 12, 2024



Large Language Models (LLMs) have shown remarkable abilities across various language tasks, but solving complex reasoning problems remains a challenge. While existing methods like Chain-of-Thought (CoT) and Tree-of-Thought (ToT) enhance reasoning by decomposing problems or structuring prompts, they typically perform a single pass of reasoning and may fail to revisit flawed paths, compromising accuracy. To address this, we propose a novel reasoning framework called Forest-of-Thought (FoT), which integrates multiple reasoning trees to leverage collective decision-making for solving complex logical problems. FoT utilizes sparse activation strategies to select the most relevant reasoning paths, improving both efficiency and accuracy. Additionally, we introduce a dynamic self-correction strategy that enables real-time error correction and learning from past mistakes, as well as consensus-guided decision making strategies to optimize correctness and computational resources. Experimental results demonstrate that the FoT framework, combined with these strategies, significantly enhances the reasoning capabilities of LLMs, enabling them to solve complex tasks with greater precision and efficiency.
Large OCR Model:An Empirical Study of Scaling Law for OCR
Jan 02, 2024The laws of model size, data volume, computation and model performance have been extensively studied in the field of Natural Language Processing (NLP). However, the scaling laws in Optical Character Recognition (OCR) have not yet been investigated. To address this, we conducted comprehensive studies that involved examining the correlation between performance and the scale of models, data volume and computation in the field of text recognition.Conclusively, the study demonstrates smooth power laws between performance and model size, as well as training data volume, when other influencing factors are held constant. Additionally, we have constructed a large-scale dataset called REBU-Syn, which comprises 6 million real samples and 18 million synthetic samples. Based on our scaling law and new dataset, we have successfully trained a scene text recognition model, achieving a new state-ofthe-art on 6 common test benchmarks with a top-1 average accuracy of 97.42%.