 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking 1-bit Optimization Leveraging Pre-trained Large Language Models
Aug 09, 2025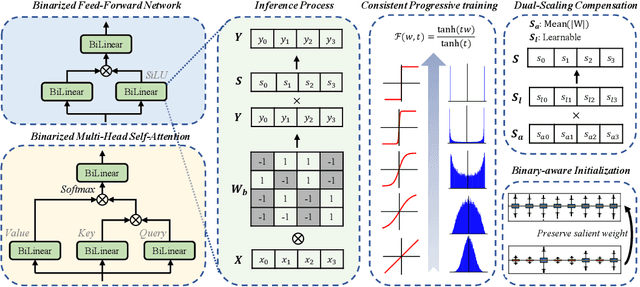

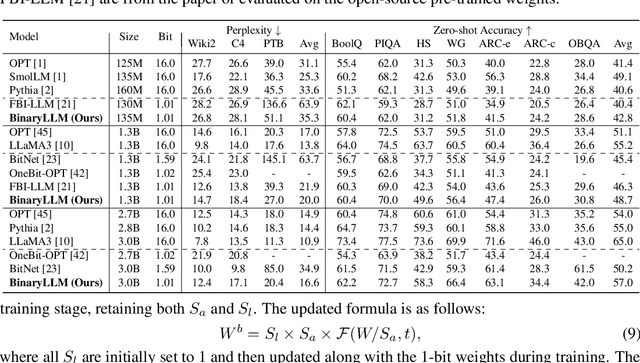
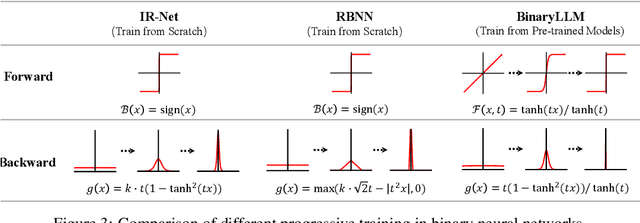
1-bit LLM quantization offers significant advantages in reducing storage and computational costs. However, existing methods typically train 1-bit LLMs from scratch, failing to fully leverage pre-trained models. This results in high training costs and notable accuracy degradation. We identify that the large gap between full precision and 1-bit representations makes direct adaptation difficult. In this paper, we introduce a consistent progressive training for both forward and backward, smoothly converting the floating-point weights into the binarized ones. Additionally, we incorporate binary-aware initialization and dual-scaling compensation to reduce the difficulty of progressive training and improve the performance. Experimental results on LLMs of various sizes demonstrate that our method outperforms existing approaches. Our results show that high-performance 1-bit LLMs can be achieved using pre-trained models, eliminating the need for expensive training from scratch.
Eve: Efficient Multimodal Vision Language Models with Elastic Visual Experts
Jan 08, 2025



Multimodal vision language models (VLMs) have made significant progress with the support of continuously increasing model sizes and data volumes. Running VLMs on edge devices has become a challenge for their widespread application. There are several efficient VLM efforts, but they often sacrifice linguistic capabilities to enhance multimodal abilities, or require extensive training. To address this quandary,we introduce the innovative framework of Efficient Vision Language Models with Elastic Visual Experts (Eve). By strategically incorporating adaptable visual expertise at multiple stages of training, Eve strikes a balance between preserving linguistic abilities and augmenting multimodal capabilities. This balanced approach results in a versatile model with only 1.8B parameters that delivers significant improvements in both multimodal and linguistic tasks. Notably, in configurations below 3B parameters, Eve distinctly outperforms in language benchmarks and achieves state-of-the-art results 68.87% in VLM Benchmarks. Additionally, its multimodal accuracy outstrips that of the larger 7B LLaVA-1.5 model.
Forest-of-Thought: Scaling Test-Time Compute for Enhancing LLM Reasoning
Dec 12, 2024



Large Language Models (LLMs) have shown remarkable abilities across various language tasks, but solving complex reasoning problems remains a challenge. While existing methods like Chain-of-Thought (CoT) and Tree-of-Thought (ToT) enhance reasoning by decomposing problems or structuring prompts, they typically perform a single pass of reasoning and may fail to revisit flawed paths, compromising accuracy. To address this, we propose a novel reasoning framework called Forest-of-Thought (FoT), which integrates multiple reasoning trees to leverage collective decision-making for solving complex logical problems. FoT utilizes sparse activation strategies to select the most relevant reasoning paths, improving both efficiency and accuracy. Additionally, we introduce a dynamic self-correction strategy that enables real-time error correction and learning from past mistakes, as well as consensus-guided decision making strategies to optimize correctness and computational resources. Experimental results demonstrate that the FoT framework, combined with these strategies, significantly enhances the reasoning capabilities of LLMs, enabling them to solve complex tasks with greater precision and efficiency.
EMS-SD: Efficient Multi-sample Speculative Decoding for Accelerating Large Language Models
May 13, 2024Speculative decoding emerges as a pivotal technique for enhancing the inference speed of Large Language Models (LLMs). Despite recent research aiming to improve prediction efficiency, multi-sample speculative decoding has been overlooked due to varying numbers of accepted tokens within a batch in the verification phase. Vanilla method adds padding tokens in order to ensure that the number of new tokens remains consistent across samples. However, this increases the computational and memory access overhead, thereby reducing the speedup ratio. We propose a novel method that can resolve the issue of inconsistent tokens accepted by different samples without necessitating an increase in memory or computing overhead. Furthermore, our proposed method can handle the situation where the prediction tokens of different samples are inconsistent without the need to add padding tokens. Sufficient experiments demonstrate the efficacy of our method. Our code is available at https://github.com/niyunsheng/EMS-SD.
Large OCR Model:An Empirical Study of Scaling Law for OCR
Jan 02, 2024The laws of model size, data volume, computation and model performance have been extensively studied in the field of Natural Language Processing (NLP). However, the scaling laws in Optical Character Recognition (OCR) have not yet been investigated. To address this, we conducted comprehensive studies that involved examining the correlation between performance and the scale of models, data volume and computation in the field of text recognition.Conclusively, the study demonstrates smooth power laws between performance and model size, as well as training data volume, when other influencing factors are held constant. Additionally, we have constructed a large-scale dataset called REBU-Syn, which comprises 6 million real samples and 18 million synthetic samples. Based on our scaling law and new dataset, we have successfully trained a scene text recognition model, achieving a new state-ofthe-art on 6 common test benchmarks with a top-1 average accuracy of 97.42%.
Gold-YOLO: Efficient Object Detector via Gather-and-Distribute Mechanism
Sep 25, 2023
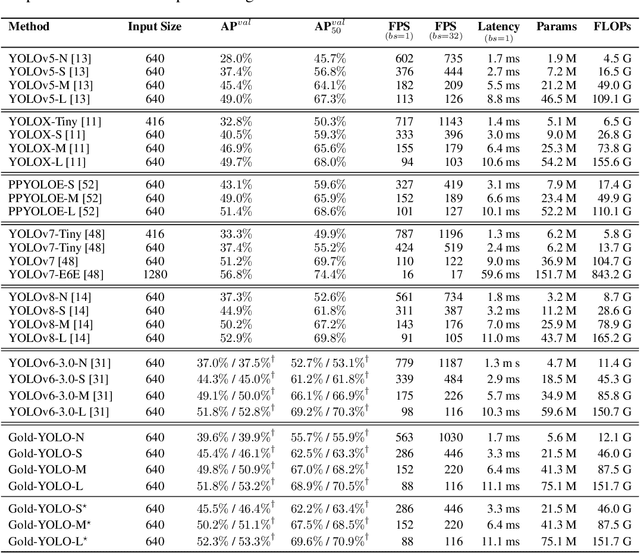


In the past years, YOLO-series models have emerged as the leading approaches in the area of real-time object detection. Many studies pushed up the baseline to a higher level by modifying the architecture, augmenting data and designing new losses. However, we find previous models still suffer from information fusion problem, although Feature Pyramid Network (FPN) and Path Aggregation Network (PANet) have alleviated this. Therefore, this study provides an advanced Gatherand-Distribute mechanism (GD) mechanism, which is realized with convolution and self-attention operations. This new designed model named as Gold-YOLO, which boosts the multi-scale feature fusion capabilities and achieves an ideal balance between latency and accuracy across all model scales. Additionally, we implement MAE-style pretraining in the YOLO-series for the first time, allowing YOLOseries models could be to benefit from unsupervised pretraining. Gold-YOLO-N attains an outstanding 39.9% AP on the COCO val2017 datasets and 1030 FPS on a T4 GPU, which outperforms the previous SOTA model YOLOv6-3.0-N with similar FPS by +2.4%. The PyTorch code is available at https://github.com/huawei-noah/Efficient-Computing/tree/master/Detection/Gold-YOLO, and the MindSpore code is available at https://gitee.com/mindspore/models/tree/master/research/cv/Gold_YOLO.
Boosting Semantic Segmentation from the Perspective of Explicit Class Embeddings
Aug 24, 2023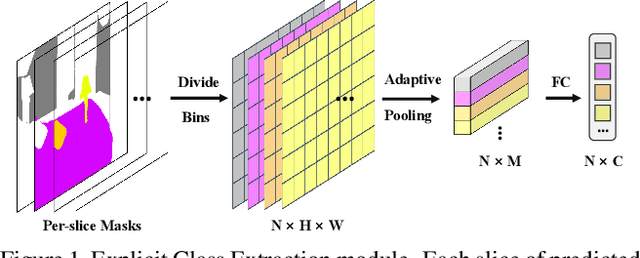
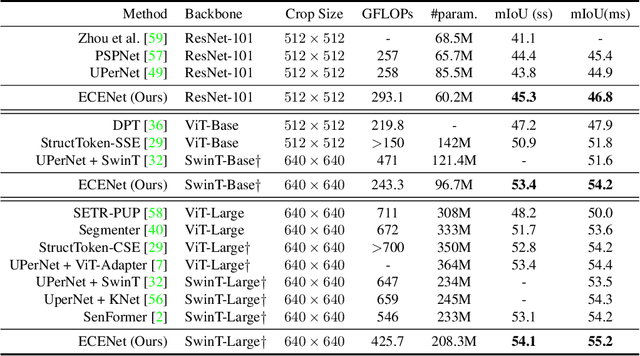
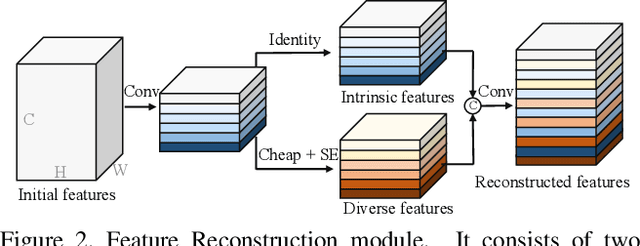
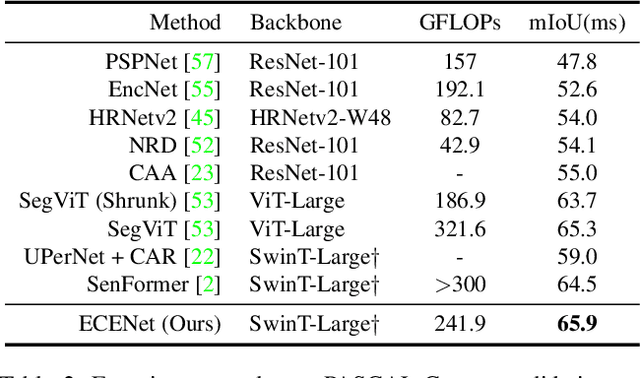
Semantic segmentation is a computer vision task that associates a label with each pixel in an image. Modern approaches tend to introduce class embeddings into semantic segmentation for deeply utilizing category semantics, and regard supervised class masks as final predictions. In this paper, we explore the mechanism of class embeddings and have an insight that more explicit and meaningful class embeddings can be generated based on class masks purposely. Following this observation, we propose ECENet, a new segmentation paradigm, in which class embeddings are obtained and enhanced explicitly during interacting with multi-stage image features. Based on this, we revisit the traditional decoding process and explore inverted information flow between segmentation masks and class embeddings. Furthermore, to ensure the discriminability and informativity of features from backbone, we propose a Feature Reconstruction module, which combines intrinsic and diverse branches together to ensure the concurrence of diversity and redundancy in features. Experiments show that our ECENet outperforms its counterparts on the ADE20K dataset with much less computational cost and achieves new state-of-the-art results on PASCAL-Context dataset. The code will be released at https://gitee.com/mindspore/models and https://github.com/Carol-lyh/ECENet.
Category Feature Transformer for Semantic Segmentation
Aug 10, 2023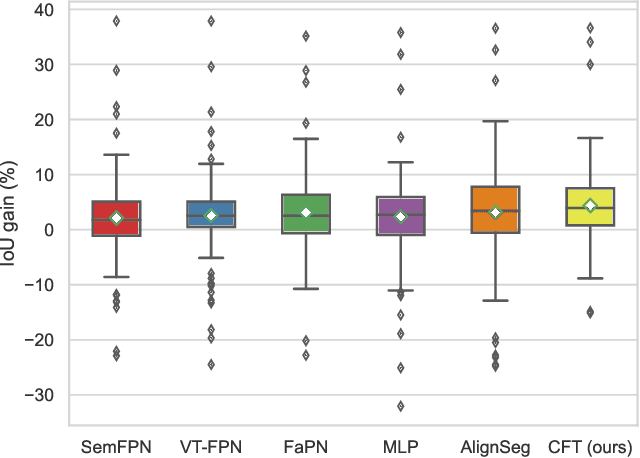
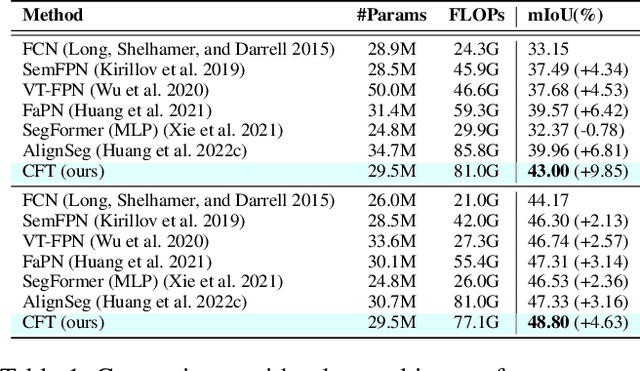
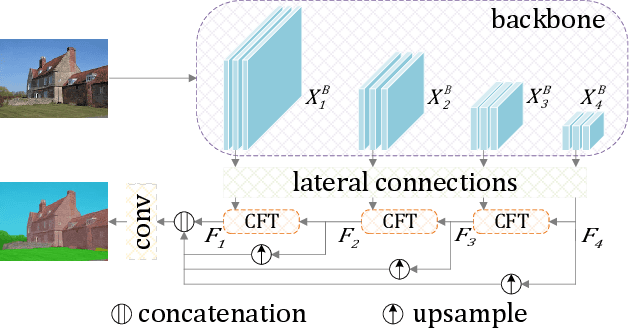
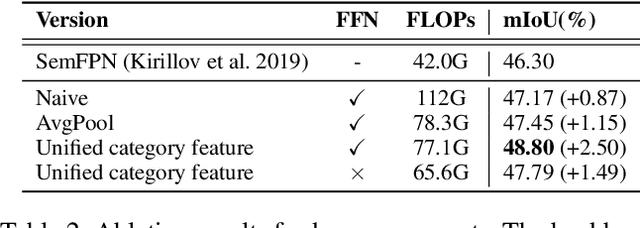
Aggregation of multi-stage features has been revealed to play a significant role in semantic segmentation. Unlike previous methods employing point-wise summation or concatenation for feature aggregation, this study proposes the Category Feature Transformer (CFT) that explores the flow of category embedding and transformation among multi-stage features through the prevalent multi-head attention mechanism. CFT learns unified feature embeddings for individual semantic categories from high-level features during each aggregation process and dynamically broadcasts them to high-resolution features. Integrating the proposed CFT into a typical feature pyramid structure exhibits superior performance over a broad range of backbone networks. We conduct extensive experiments on popular semantic segmentation benchmarks. Specifically, the proposed CFT obtains a compelling 55.1% mIoU with greatly reduced model parameters and computations on the challenging ADE20K dataset.
Bi-ViT: Pushing the Limit of Vision Transformer Quantization
May 21, 2023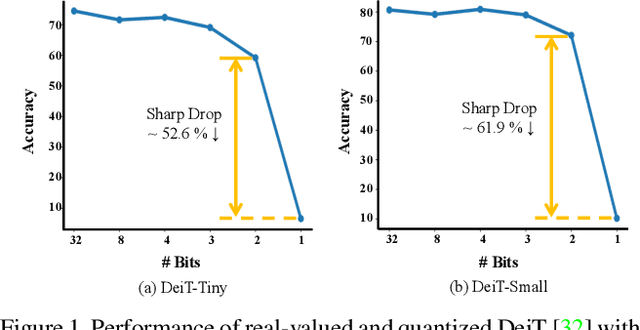

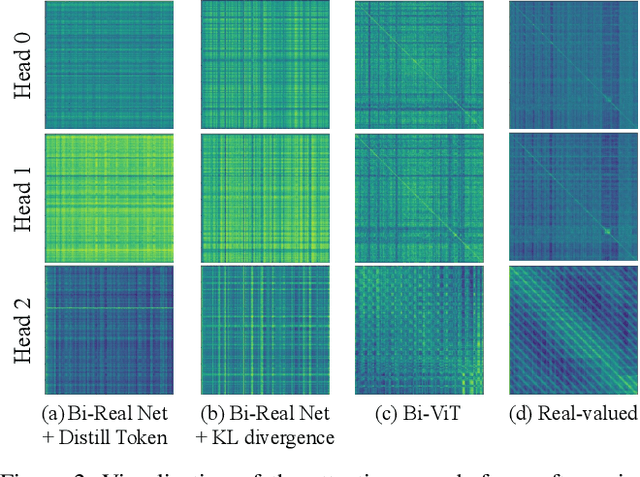
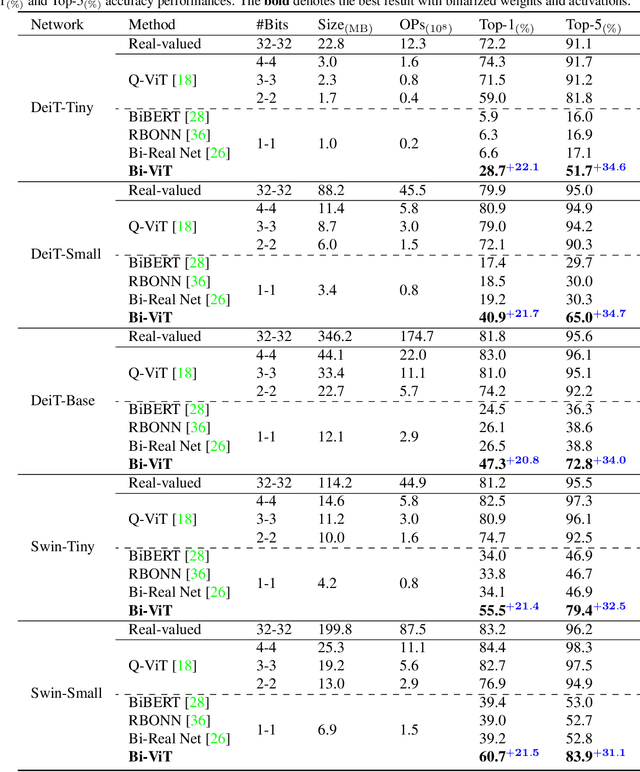
Vision transformers (ViTs) quantization offers a promising prospect to facilitate deploying large pre-trained networks on resource-limited devices. Fully-binarized ViTs (Bi-ViT) that pushes the quantization of ViTs to its limit remain largely unexplored and a very challenging task yet, due to their unacceptable performance. Through extensive empirical analyses, we identify the severe drop in ViT binarization is caused by attention distortion in self-attention, which technically stems from the gradient vanishing and ranking disorder. To address these issues, we first introduce a learnable scaling factor to reactivate the vanished gradients and illustrate its effectiveness through theoretical and experimental analyses. We then propose a ranking-aware distillation method to rectify the disordered ranking in a teacher-student framework. Bi-ViT achieves significant improvements over popular DeiT and Swin backbones in terms of Top-1 accuracy and FLOPs. For example, with DeiT-Tiny and Swin-Tiny, our method significantly outperforms baselines by 22.1% and 21.4% respectively, while 61.5x and 56.1x theoretical acceleration in terms of FLOPs compared with real-valued counterparts on ImageNet.
Redistribution of Weights and Activations for AdderNet Quantization
Dec 20, 2022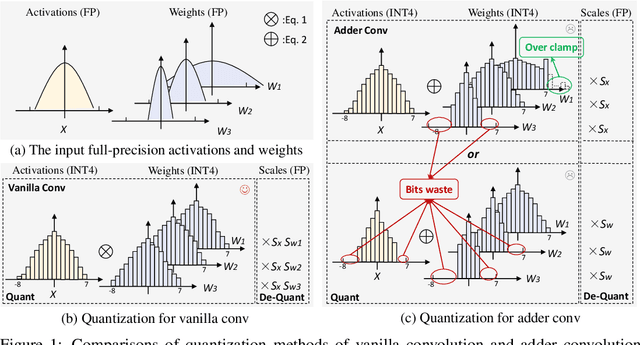


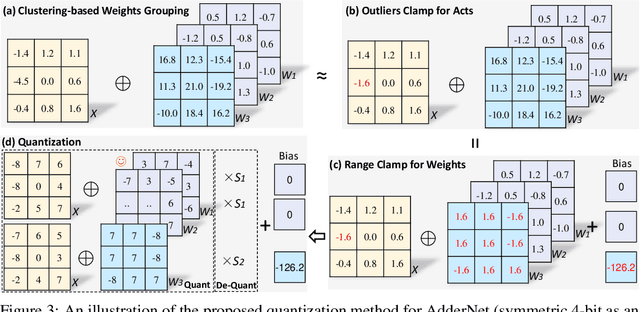
Adder Neural Network (AdderNet) provides a new way for developing energy-efficient neural networks by replacing the expensive multiplications in convolution with cheaper additions (i.e.l1-norm). To achieve higher hardware efficiency, it is necessary to further study the low-bit quantization of AdderNet. Due to the limitation that the commutative law in multiplication does not hold in l1-norm, the well-established quantization methods on convolutional networks cannot be applied on AdderNets. Thus, the existing AdderNet quantization techniques propose to use only one shared scale to quantize both the weights and activations simultaneously. Admittedly, such an approach can keep the commutative law in the l1-norm quantization process, while the accuracy drop after low-bit quantization cannot be ignored. To this end, we first thoroughly analyze the difference on distributions of weights and activations in AdderNet and then propose a new quantization algorithm by redistributing the weights and the activations. Specifically, the pre-trained full-precision weights in different kernels are clustered into different groups, then the intra-group sharing and inter-group independent scales can be adopted. To further compensate the accuracy drop caused by the distribution difference, we then develop a lossless range clamp scheme for weights and a simple yet effective outliers clamp strategy for activations. Thus, the functionality of full-precision weights and the representation ability of full-precision activations can be fully preserved. The effectiveness of the proposed quantization method for AdderNet is well verified on several benchmarks, e.g., our 4-bit post-training quantized adder ResNet-18 achieves an 66.5% top-1 accuracy on the ImageNet with comparable energy efficiency, which is about 8.5% higher than that of the previous AdderNet quantization methods.