 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersonaTree: Structured Lifecycle Memory for Person Understanding in LLM Agents
Jun 03, 2026Persistent LLM agents require memory representations that make the formation of person understanding explicit across long term interaction. Existing agent memory methods emphasize information retention and retrieval, yet give limited account of how accumulated interaction evidence is abstracted into person understanding. We view this process as schema formation, where situated evidence is abstracted into reusable patterns and stable person level claims. We introduce PersonaTree, a structured lifecycle memory framework that realizes this view as a three level persona tree with explicit support paths from evidence to claims. PersonaTree maintains the tree through conservative writing, confidence guided consolidation, and query conditioned path retrieval, returning only the evidence depth required by each query. Across six person understanding and persistent memory benchmarks with three answer backbones, PersonaTree ranks first in 12 of 18 compact scores and reaches the top two in 16 settings. Ablations show that hierarchy improves abstract person understanding on KnowMe, while support path retrieval improves RealPref alignment under a comparable context budget.
Align Attention Heads Before Merging Them: An Effective Way for Converting MHA to GQA
Dec 30, 2024Large language models have been shown to perform well on a variety of natural language processing problems. However, as the model size and the input sequence's length increase, the rapid increase of KV Cache significantly slows down inference speed. Therefore GQA model, as an alternative to MHA model, has been widely introduced into LLMs. In this work, we propose a low-cost method for pruning MHA models into GQA models with any compression ratio of key-value heads. Our method is based on $\mathit{L_0}$ masks to gradually remove redundant parameters. In addition, we apply orthogonal transformations to attention heads without changing the model to increase similarity between attention heads before pruning training, in order to further improve performance of the model. Our method can be compatible with rotary position embedding (RoPE), which means the model after training can be fully adapted to the mainstream standard GQA framework. Experiments demonstrate that our strategy can compress up to 87.5% of key-value heads of the LLaMA2-7B model without too much performance degradation, just achieved through supervised fine-tuning.
Integrating MedCLIP and Cross-Modal Fusion for Automatic Radiology Report Generation
Dec 10, 2024Automating radiology report generation can significantly reduce the workload of radiologists and enhance the accuracy, consistency, and efficiency of clinical documentation.We propose a novel cross-modal framework that uses MedCLIP as both a vision extractor and a retrieval mechanism to improve the process of medical report generation.By extracting retrieved report features and image features through an attention-based extract module, and integrating them with a fusion module, our method improves the coherence and clinical relevance of generated reports.Experimental results on the widely used IU-Xray dataset demonstrate the effectiveness of our approach, showing improvements over commonly used methods in both report quality and relevance.Additionally, ablation studies provide further validation of the framework, highlighting the importance of accurate report retrieval and feature integration in generating comprehensive medical reports.
ScalingNote: Scaling up Retrievers with Large Language Models for Real-World Dense Retrieval
Nov 24, 2024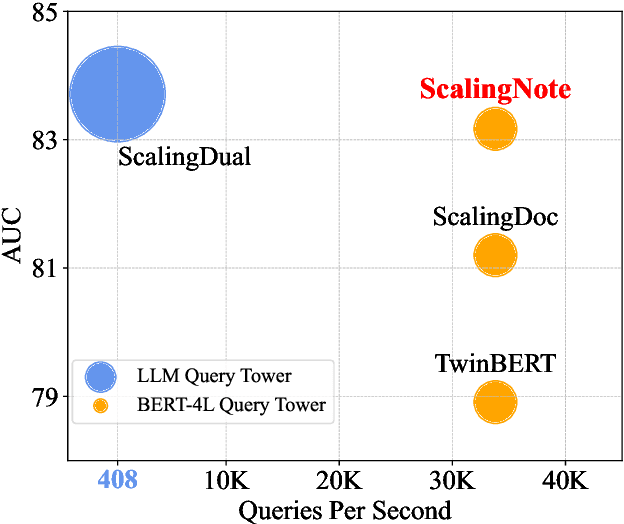
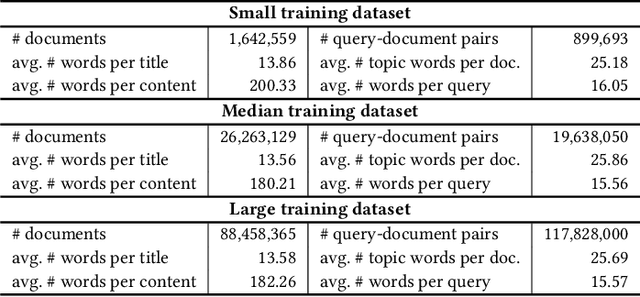
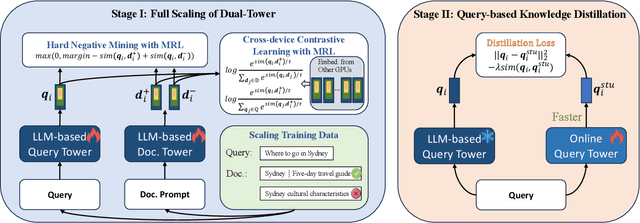
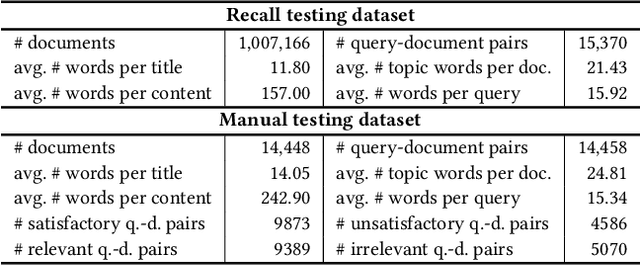
Dense retrieval in most industries employs dual-tower architectures to retrieve query-relevant documents. Due to online deployment requirements, existing real-world dense retrieval systems mainly enhance performance by designing negative sampling strategies, overlooking the advantages of scaling up. Recently, Large Language Models (LLMs) have exhibited superior performance that can be leveraged for scaling up dense retrieval. However, scaling up retrieval models significantly increases online query latency. To address this challenge, we propose ScalingNote, a two-stage method to exploit the scaling potential of LLMs for retrieval while maintaining online query latency. The first stage is training dual towers, both initialized from the same LLM, to unlock the potential of LLMs for dense retrieval. Then, we distill only the query tower using mean squared error loss and cosine similarity to reduce online costs. Through theoretical analysis and comprehensive offline and online experiments, we show the effectiveness and efficiency of ScalingNote. Our two-stage scaling method outperforms end-to-end models and verifies the scaling law of dense retrieval with LLMs in industrial scenarios, enabling cost-effective scaling of dense retrieval systems. Our online method incorporating ScalingNote significantly enhances the relevance between retrieved documents and queries.
SyntheT2C: Generating Synthetic Data for Fine-Tuning Large Language Models on the Text2Cypher Task
Jun 15, 2024



Integrating Large Language Models (LLMs) with existing Knowledge Graph (KG) databases presents a promising avenue for enhancing LLMs' efficacy and mitigating their "hallucinations". Given that most KGs reside in graph databases accessible solely through specialized query languages (e.g., Cypher), there exists a critical need to bridge the divide between LLMs and KG databases by automating the translation of natural language into Cypher queries (commonly termed the "Text2Cypher" task). Prior efforts tried to bolster LLMs' proficiency in Cypher generation through Supervised Fine-Tuning. However, these explorations are hindered by the lack of annotated datasets of Query-Cypher pairs, resulting from the labor-intensive and domain-specific nature of annotating such datasets. In this study, we propose SyntheT2C, a methodology for constructing a synthetic Query-Cypher pair dataset, comprising two distinct pipelines: (1) LLM-based prompting and (2) template-filling. SyntheT2C facilitates the generation of extensive Query-Cypher pairs with values sampled from an underlying Neo4j graph database. Subsequently, SyntheT2C is applied to two medical databases, culminating in the creation of a synthetic dataset, MedT2C. Comprehensive experiments demonstrate that the MedT2C dataset effectively enhances the performance of backbone LLMs on the Text2Cypher task. Both the SyntheT2C codebase and the MedT2C dataset will be released soon.
Mix-of-Granularity: Optimize the Chunking Granularity for Retrieval-Augmented Generation
Jun 01, 2024



Integrating information from different reference data sources is a major challenge for Retrieval-Augmented Generation (RAG) systems because each knowledge source adopts a unique data structure and follows different conventions. Retrieving from multiple knowledge sources with one fixed strategy usually leads to under-exploitation of information. To mitigate this drawback, inspired by Mix-of-Expert, we introduce Mix-of-Granularity (MoG), a method that dynamically determines the optimal granularity of a knowledge database based on input queries using a router. The router is efficiently trained with a newly proposed loss function employing soft labels. We further extend MoG to Mix-of-Granularity-Graph (MoGG), where reference documents are pre-processed into graphs, enabling the retrieval of relevant information from distantly situated chunks. Extensive experiments demonstrate that both MoG and MoGG effectively predict optimal granularity levels, significantly enhancing the performance of the RAG system in downstream tasks. The code of both MoG and MoGG will be made public.
From Image to Video, what do we need in multimodal LLMs?
Apr 18, 2024Multimodal Large Language Models (MLLMs) have demonstrated profound capabilities in understanding multimodal information, covering from Image LLMs to the more complex Video LLMs. Numerous studies have illustrated their exceptional cross-modal comprehension. Recently, integrating video foundation models with large language models to build a comprehensive video understanding system has been proposed to overcome the limitations of specific pre-defined vision tasks. However, the current advancements in Video LLMs tend to overlook the foundational contributions of Image LLMs, often opting for more complicated structures and a wide variety of multimodal data for pre-training. This approach significantly increases the costs associated with these methods.In response to these challenges, this work introduces an efficient method that strategically leverages the priors of Image LLMs, facilitating a resource-efficient transition from Image to Video LLMs. We propose RED-VILLM, a Resource-Efficient Development pipeline for Video LLMs from Image LLMs, which utilizes a temporal adaptation plug-and-play structure within the image fusion module of Image LLMs. This adaptation extends their understanding capabilities to include temporal information, enabling the development of Video LLMs that not only surpass baseline performances but also do so with minimal instructional data and training resources. Our approach highlights the potential for a more cost-effective and scalable advancement in multimodal models, effectively building upon the foundational work of Image LLMs.
LogicalDefender: Discovering, Extracting, and Utilizing Common-Sense Knowledge
Mar 18, 2024



Large text-to-image models have achieved astonishing performance in synthesizing diverse and high-quality images guided by texts. With detail-oriented conditioning control, even finer-grained spatial control can be achieved. However, some generated images still appear unreasonable, even with plentiful object features and a harmonious style. In this paper, we delve into the underlying causes and find that deep-level logical information, serving as common-sense knowledge, plays a significant role in understanding and processing images. Nonetheless, almost all models have neglected the importance of logical relations in images, resulting in poor performance in this aspect. Following this observation, we propose LogicalDefender, which combines images with the logical knowledge already summarized by humans in text. This encourages models to learn logical knowledge faster and better, and concurrently, extracts the widely applicable logical knowledge from both images and human knowledge. Experiments show that our model has achieved better logical performance, and the extracted logical knowledge can be effectively applied to other scenarios.
CADReN: Contextual Anchor-Driven Relational Network for Controllable Cross-Graphs Node Importance Estimation
Feb 06, 2024Node Importance Estimation (NIE) is crucial for integrating external information into Large Language Models through Retriever-Augmented Generation. Traditional methods, focusing on static, single-graph characteristics, lack adaptability to new graphs and user-specific requirements. CADReN, our proposed method, addresses these limitations by introducing a Contextual Anchor (CA) mechanism. This approach enables the network to assess node importance relative to the CA, considering both structural and semantic features within Knowledge Graphs (KGs). Extensive experiments show that CADReN achieves better performance in cross-graph NIE task, with zero-shot prediction ability. CADReN is also proven to match the performance of previous models on single-graph NIE task. Additionally, we introduce and opensource two new datasets, RIC200 and WK1K, specifically designed for cross-graph NIE research, providing a valuable resource for future developments in this domain.
Boosting Semantic Segmentation from the Perspective of Explicit Class Embeddings
Aug 24, 2023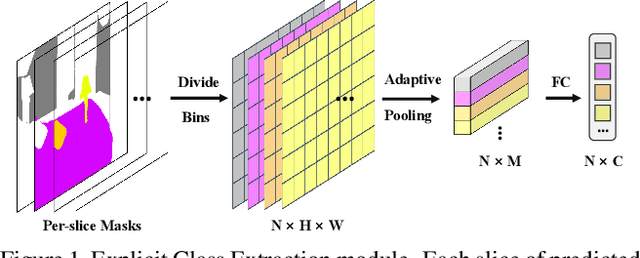
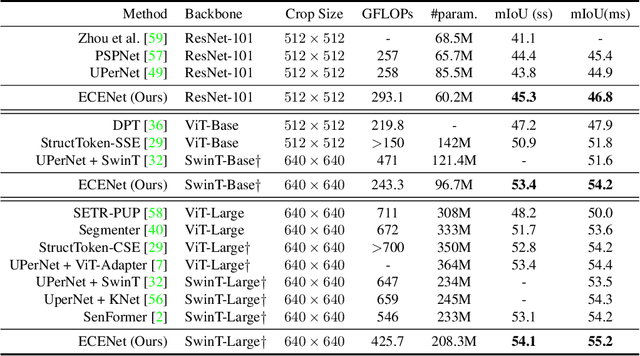
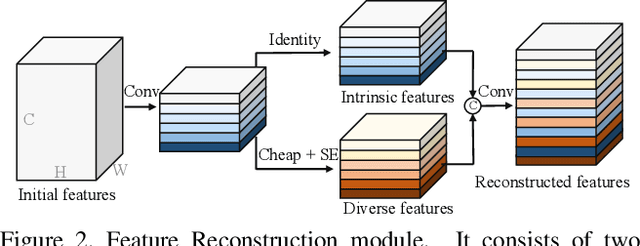
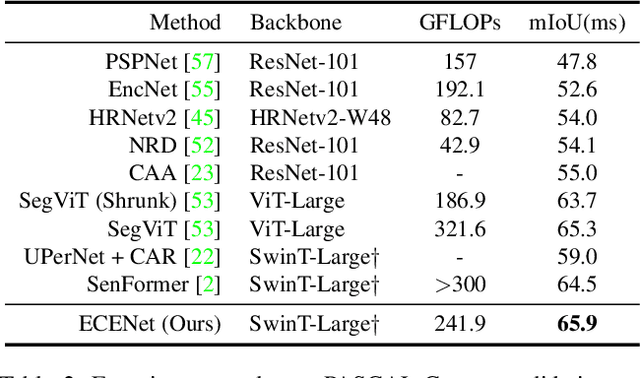
Semantic segmentation is a computer vision task that associates a label with each pixel in an image. Modern approaches tend to introduce class embeddings into semantic segmentation for deeply utilizing category semantics, and regard supervised class masks as final predictions. In this paper, we explore the mechanism of class embeddings and have an insight that more explicit and meaningful class embeddings can be generated based on class masks purposely. Following this observation, we propose ECENet, a new segmentation paradigm, in which class embeddings are obtained and enhanced explicitly during interacting with multi-stage image features. Based on this, we revisit the traditional decoding process and explore inverted information flow between segmentation masks and class embeddings. Furthermore, to ensure the discriminability and informativity of features from backbone, we propose a Feature Reconstruction module, which combines intrinsic and diverse branches together to ensure the concurrence of diversity and redundancy in features. Experiments show that our ECENet outperforms its counterparts on the ADE20K dataset with much less computational cost and achieves new state-of-the-art results on PASCAL-Context dataset. The code will be released at https://gitee.com/mindspore/models and https://github.com/Carol-lyh/ECENet.