 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeART: Adaptive Relational Transformer for Pedestrian Trajectory Prediction with Temporal-Aware Relations
Apr 04, 2026Accurate prediction of real-world pedestrian trajectories is crucial for a wide range of robot-related applications. Recent approaches typically adopt graph-based or transformer-based frameworks to model interactions. Despite their effectiveness, these methods either introduce unnecessary computational overhead or struggle to represent the diverse and time-varying characteristics of human interactions. In this work, we present an Adaptive Relational Transformer (ART), which introduces a Temporal-Aware Relation Graph (TARG) to explicitly capture the evolution of pairwise interactions and an Adaptive Interaction Pruning (AIP) mechanism to reduce redundant computations efficiently. Extensive evaluations on ETH/UCY and NBA benchmarks show that ART delivers state-of-the-art accuracy with high computational efficiency.
Large-Scale Multi-Character Interaction Synthesis
May 20, 2025Generating large-scale multi-character interactions is a challenging and important task in character animation. Multi-character interactions involve not only natural interactive motions but also characters coordinated with each other for transition. For example, a dance scenario involves characters dancing with partners and also characters coordinated to new partners based on spatial and temporal observations. We term such transitions as coordinated interactions and decompose them into interaction synthesis and transition planning. Previous methods of single-character animation do not consider interactions that are critical for multiple characters. Deep-learning-based interaction synthesis usually focuses on two characters and does not consider transition planning. Optimization-based interaction synthesis relies on manually designing objective functions that may not generalize well. While crowd simulation involves more characters, their interactions are sparse and passive. We identify two challenges to multi-character interaction synthesis, including the lack of data and the planning of transitions among close and dense interactions. Existing datasets either do not have multiple characters or do not have close and dense interactions. The planning of transitions for multi-character close and dense interactions needs both spatial and temporal considerations. We propose a conditional generative pipeline comprising a coordinatable multi-character interaction space for interaction synthesis and a transition planning network for coordinations. Our experiments demonstrate the effectiveness of our proposed pipeline for multicharacter interaction synthesis and the applications facilitated by our method show the scalability and transferability.
CADReN: Contextual Anchor-Driven Relational Network for Controllable Cross-Graphs Node Importance Estimation
Feb 06, 2024Node Importance Estimation (NIE) is crucial for integrating external information into Large Language Models through Retriever-Augmented Generation. Traditional methods, focusing on static, single-graph characteristics, lack adaptability to new graphs and user-specific requirements. CADReN, our proposed method, addresses these limitations by introducing a Contextual Anchor (CA) mechanism. This approach enables the network to assess node importance relative to the CA, considering both structural and semantic features within Knowledge Graphs (KGs). Extensive experiments show that CADReN achieves better performance in cross-graph NIE task, with zero-shot prediction ability. CADReN is also proven to match the performance of previous models on single-graph NIE task. Additionally, we introduce and opensource two new datasets, RIC200 and WK1K, specifically designed for cross-graph NIE research, providing a valuable resource for future developments in this domain.
Hard No-Box Adversarial Attack on Skeleton-Based Human Action Recognition with Skeleton-Motion-Informed Gradient
Aug 18, 2023
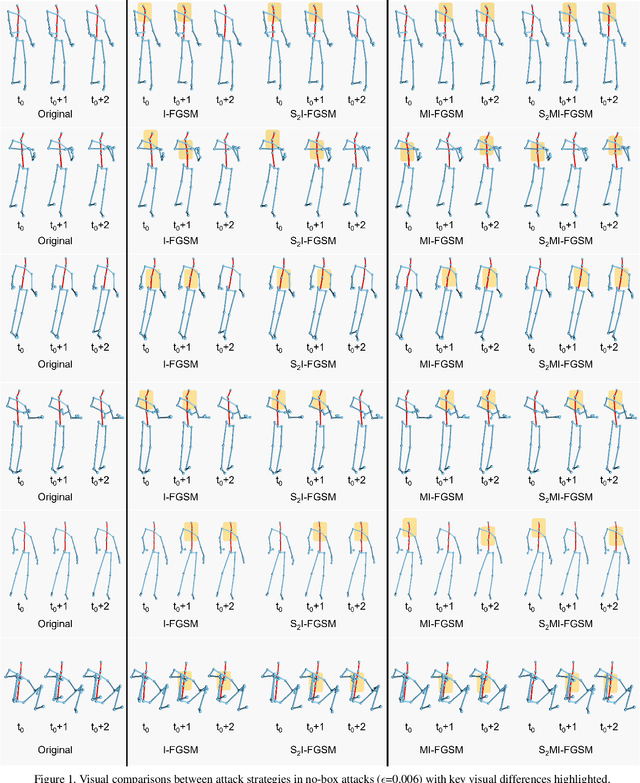
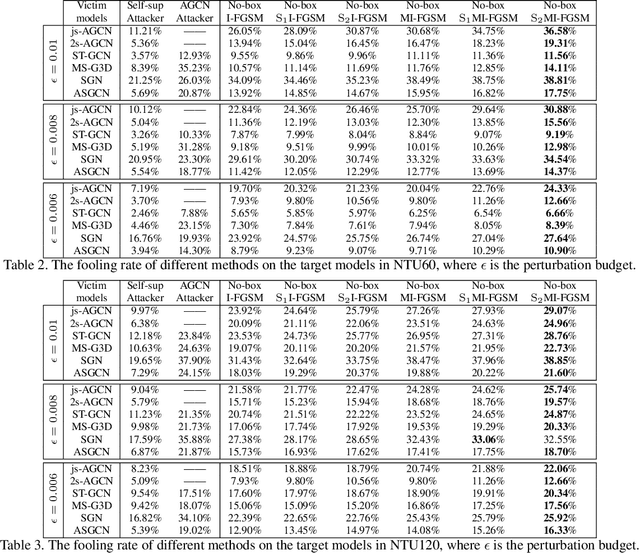
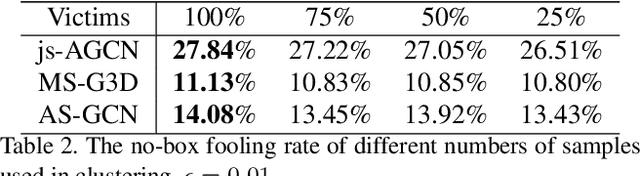
Recently, methods for skeleton-based human activity recognition have been shown to be vulnerable to adversarial attacks. However, these attack methods require either the full knowledge of the victim (i.e. white-box attacks), access to training data (i.e. transfer-based attacks) or frequent model queries (i.e. black-box attacks). All their requirements are highly restrictive, raising the question of how detrimental the vulnerability is. In this paper, we show that the vulnerability indeed exists. To this end, we consider a new attack task: the attacker has no access to the victim model or the training data or labels, where we coin the term hard no-box attack. Specifically, we first learn a motion manifold where we define an adversarial loss to compute a new gradient for the attack, named skeleton-motion-informed (SMI) gradient. Our gradient contains information of the motion dynamics, which is different from existing gradient-based attack methods that compute the loss gradient assuming each dimension in the data is independent. The SMI gradient can augment many gradient-based attack methods, leading to a new family of no-box attack methods. Extensive evaluation and comparison show that our method imposes a real threat to existing classifiers. They also show that the SMI gradient improves the transferability and imperceptibility of adversarial samples in both no-box and transfer-based black-box settings.
On the Design Fundamentals of Diffusion Models: A Survey
Jun 07, 2023



Diffusion models are generative models, which gradually add and remove noise to learn the underlying distribution of training data for data generation. The components of diffusion models have gained significant attention with many design choices proposed. Existing reviews have primarily focused on higher-level solutions, thereby covering less on the design fundamentals of components. This study seeks to address this gap by providing a comprehensive and coherent review on component-wise design choices in diffusion models. Specifically, we organize this review according to their three key components, namely the forward process, the reverse process, and the sampling procedure. This allows us to provide a fine-grained perspective of diffusion models, benefiting future studies in the analysis of individual components, the applicability of design choices, and the implementation of diffusion models.
Unifying Human Motion Synthesis and Style Transfer with Denoising Diffusion Probabilistic Models
Dec 16, 2022Generating realistic motions for digital humans is a core but challenging part of computer animations and games, as human motions are both diverse in content and rich in styles. While the latest deep learning approaches have made significant advancements in this domain, they mostly consider motion synthesis and style manipulation as two separate problems. This is mainly due to the challenge of learning both motion contents that account for the inter-class behaviour and styles that account for the intra-class behaviour effectively in a common representation. To tackle this challenge, we propose a denoising diffusion probabilistic model solution for styled motion synthesis. As diffusion models have a high capacity brought by the injection of stochasticity, we can represent both inter-class motion content and intra-class style behaviour in the same latent. This results in an integrated, end-to-end trained pipeline that facilitates the generation of optimal motion and exploration of content-style coupled latent space. To achieve high-quality results, we design a multi-task architecture of diffusion model that strategically generates aspects of human motions for local guidance. We also design adversarial and physical regulations for global guidance. We demonstrate superior performance with quantitative and qualitative results and validate the effectiveness of our multi-task architecture.
3D Reconstruction of Sculptures from Single Images via Unsupervised Domain Adaptation on Implicit Models
Oct 09, 2022


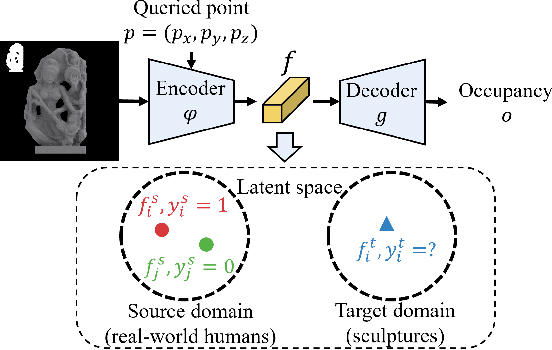
Acquiring the virtual equivalent of exhibits, such as sculptures, in virtual reality (VR) museums, can be labour-intensive and sometimes infeasible. Deep learning based 3D reconstruction approaches allow us to recover 3D shapes from 2D observations, among which single-view-based approaches can reduce the need for human intervention and specialised equipment in acquiring 3D sculptures for VR museums. However, there exist two challenges when attempting to use the well-researched human reconstruction methods: limited data availability and domain shift. Considering sculptures are usually related to humans, we propose our unsupervised 3D domain adaptation method for adapting a single-view 3D implicit reconstruction model from the source (real-world humans) to the target (sculptures) domain. We have compared the generated shapes with other methods and conducted ablation studies as well as a user study to demonstrate the effectiveness of our adaptation method. We also deploy our results in a VR application.
Denoising Diffusion Probabilistic Models for Styled Walking Synthesis
Sep 29, 2022

Generating realistic motions for digital humans is time-consuming for many graphics applications. Data-driven motion synthesis approaches have seen solid progress in recent years through deep generative models. These results offer high-quality motions but typically suffer in motion style diversity. For the first time, we propose a framework using the denoising diffusion probabilistic model (DDPM) to synthesize styled human motions, integrating two tasks into one pipeline with increased style diversity compared with traditional motion synthesis methods. Experimental results show that our system can generate high-quality and diverse walking motions.