 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeART: Adaptive Relational Transformer for Pedestrian Trajectory Prediction with Temporal-Aware Relations
Apr 04, 2026Accurate prediction of real-world pedestrian trajectories is crucial for a wide range of robot-related applications. Recent approaches typically adopt graph-based or transformer-based frameworks to model interactions. Despite their effectiveness, these methods either introduce unnecessary computational overhead or struggle to represent the diverse and time-varying characteristics of human interactions. In this work, we present an Adaptive Relational Transformer (ART), which introduces a Temporal-Aware Relation Graph (TARG) to explicitly capture the evolution of pairwise interactions and an Adaptive Interaction Pruning (AIP) mechanism to reduce redundant computations efficiently. Extensive evaluations on ETH/UCY and NBA benchmarks show that ART delivers state-of-the-art accuracy with high computational efficiency.
Investigating Permutation-Invariant Discrete Representation Learning for Spatially Aligned Images
Apr 02, 2026Vector quantization approaches (VQ-VAE, VQ-GAN) learn discrete neural representations of images, but these representations are inherently position-dependent: codes are spatially arranged and contextually entangled, requiring autoregressive or diffusion-based priors to model their dependencies at sample time. In this work, we ask whether positional information is necessary for discrete representations of spatially aligned data. We propose the permutation-invariant vector-quantized autoencoder (PI-VQ), in which latent codes are constrained to carry no positional information. We find that this constraint encourages codes to capture global, semantic features, and enables direct interpolation between images without a learned prior. To address the reduced information capacity of permutation-invariant representations, we introduce matching quantization, a vector quantization algorithm based on optimal bipartite matching that increases effective bottleneck capacity by $3.5\times$ relative to naive nearest-neighbour quantization. The compositional structure of the learned codes further enables interpolation-based sampling, allowing synthesis of novel images in a single forward pass. We evaluate PI-VQ on CelebA, CelebA-HQ and FFHQ, obtaining competitive precision, density and coverage metrics for images synthesised with our approach. We discuss the trade-offs inherent to position-free representations, including separability and interpretability of the latent codes, pointing to numerous directions for future work.
VRUD: A Drone Dataset for Complex Vehicle-VRU Interactions within Mixed Traffic
Apr 01, 2026The Operational Design Domain (ODD) of urbanoriented Level 4 (L4) autonomous driving, especially for autonomous robotaxis, confronts formidable challenges in complex urban mixed traffic environments. These challenges stem mainly from the high density of Vulnerable Road Users (VRUs) and their highly uncertain and unpredictable interaction behaviors. However, existing open-source datasets predominantly focus on structured scenarios such as highways or regulated intersections, leaving a critical gap in data representing chaotic, unstructured urban environments. To address this, this paper proposes an efficient, high-precision method for constructing drone-based datasets and establishes the Vehicle-Vulnerable Road User Interaction Dataset (VRUD), as illustrated in Figure 1. Distinct from prior works, VRUD is collected from typical "Urban Villages" in Shenzhen, characterized by loose traffic supervision and extreme occlusion. The dataset comprises 4 hours of 4K/30Hz recording, containing 11,479 VRU trajectories and 1,939 vehicle trajectories. A key characteristic of VRUD is its composition: VRUs account for about 87% of all traffic participants, significantly exceeding the proportions in existing benchmarks. Furthermore, unlike datasets that only provide raw trajectories, we extracted 4,002 multi-agent interaction scenarios based on a novel Vector Time to Collision (VTTC) threshold, supported by standard OpenDRIVE HD maps. This study provides valuable, rare edge-case resources for enhancing the safety performance of ADS in complex, unstructured urban environments. To facilitate further research, we have made the VRUD dataset open-source at: https://zzi4.github.io/VRUD/.
Benchmarking Autonomous Vehicles: A Driver Foundation Model Framework
Feb 09, 2026Autonomous vehicles (AVs) are poised to revolutionize global transportation systems. However, its widespread acceptance and market penetration remain significantly below expectations. This gap is primarily driven by persistent challenges in safety, comfort, commuting efficiency and energy economy when compared to the performance of experienced human drivers. We hypothesize that these challenges can be addressed through the development of a driver foundation model (DFM). Accordingly, we propose a framework for establishing DFMs to comprehensively benchmark AVs. Specifically, we describe a large-scale dataset collection strategy for training a DFM, discuss the core functionalities such a model should possess, and explore potential technical solutions to realize these functionalities. We further present the utility of the DFM across the operational spectrum, from defining human-centric safety envelopes to establishing benchmarks for energy economy. Overall, We aim to formalize the DFM concept and introduce a new paradigm for the systematic specification, verification and validation of AVs.
KD360-VoxelBEV: LiDAR and 360-degree Camera Cross Modality Knowledge Distillation for Bird's-Eye-View Segmentation
Dec 17, 2025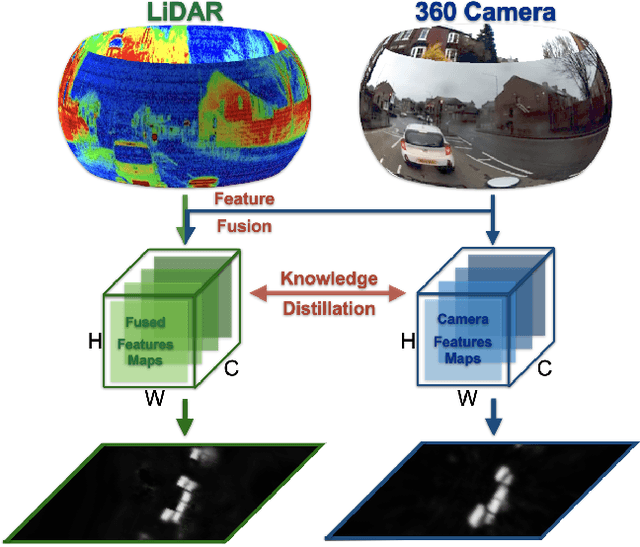
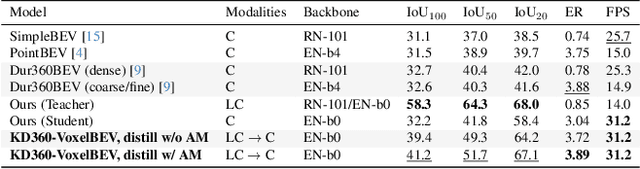


We present the first cross-modality distillation framework specifically tailored for single-panoramic-camera Bird's-Eye-View (BEV) segmentation. Our approach leverages a novel LiDAR image representation fused from range, intensity and ambient channels, together with a voxel-aligned view transformer that preserves spatial fidelity while enabling efficient BEV processing. During training, a high-capacity LiDAR and camera fusion Teacher network extracts both rich spatial and semantic features for cross-modality knowledge distillation into a lightweight Student network that relies solely on a single 360-degree panoramic camera image. Extensive experiments on the Dur360BEV dataset demonstrate that our teacher model significantly outperforms existing camera-based BEV segmentation methods, achieving a 25.6\% IoU improvement. Meanwhile, the distilled Student network attains competitive performance with an 8.5\% IoU gain and state-of-the-art inference speed of 31.2 FPS. Moreover, evaluations on KITTI-360 (two fisheye cameras) confirm that our distillation framework generalises to diverse camera setups, underscoring its feasibility and robustness. This approach reduces sensor complexity and deployment costs while providing a practical solution for efficient, low-cost BEV segmentation in real-world autonomous driving.
ViTE: Virtual Graph Trajectory Expert Router for Pedestrian Trajectory Prediction
Nov 15, 2025Pedestrian trajectory prediction is critical for ensuring safety in autonomous driving, surveillance systems, and urban planning applications. While early approaches primarily focus on one-hop pairwise relationships, recent studies attempt to capture high-order interactions by stacking multiple Graph Neural Network (GNN) layers. However, these approaches face a fundamental trade-off: insufficient layers may lead to under-reaching problems that limit the model's receptive field, while excessive depth can result in prohibitive computational costs. We argue that an effective model should be capable of adaptively modeling both explicit one-hop interactions and implicit high-order dependencies, rather than relying solely on architectural depth. To this end, we propose ViTE (Virtual graph Trajectory Expert router), a novel framework for pedestrian trajectory prediction. ViTE consists of two key modules: a Virtual Graph that introduces dynamic virtual nodes to model long-range and high-order interactions without deep GNN stacks, and an Expert Router that adaptively selects interaction experts based on social context using a Mixture-of-Experts design. This combination enables flexible and scalable reasoning across varying interaction patterns. Experiments on three benchmarks (ETH/UCY, NBA, and SDD) demonstrate that our method consistently achieves state-of-the-art performance, validating both its effectiveness and practical efficiency.
Continual Action Quality Assessment via Adaptive Manifold-Aligned Graph Regularization
Oct 08, 2025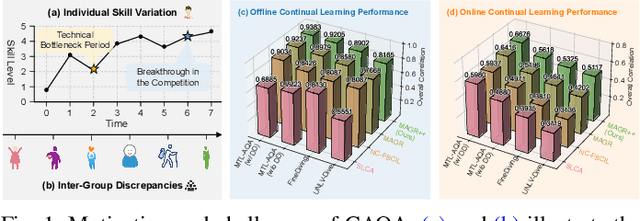
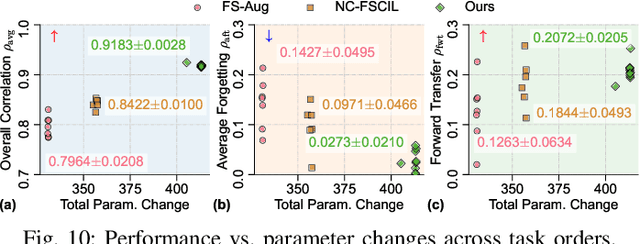
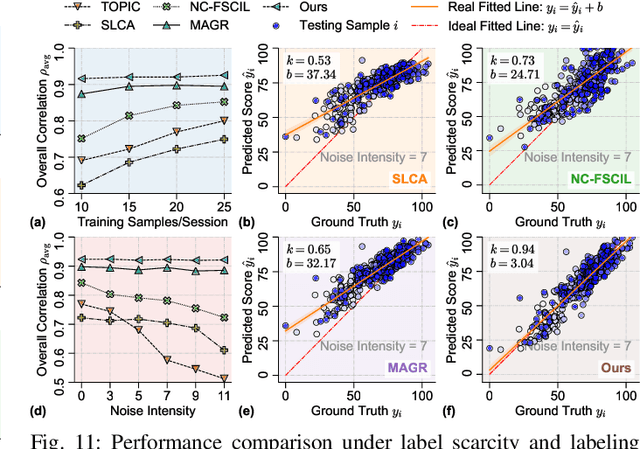
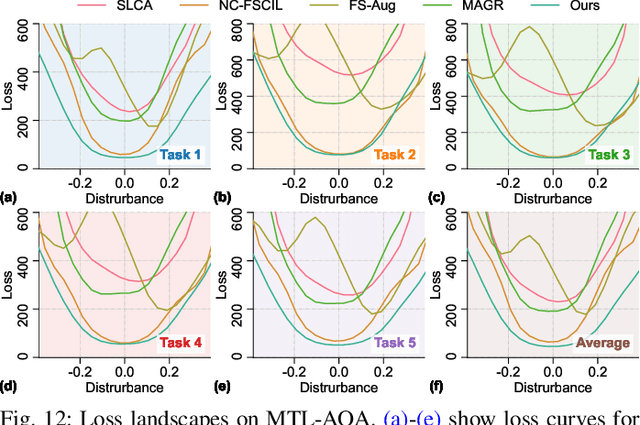
Action Quality Assessment (AQA) quantifies human actions in videos, supporting applications in sports scoring, rehabilitation, and skill evaluation. A major challenge lies in the non-stationary nature of quality distributions in real-world scenarios, which limits the generalization ability of conventional methods. We introduce Continual AQA (CAQA), which equips AQA with Continual Learning (CL) capabilities to handle evolving distributions while mitigating catastrophic forgetting. Although parameter-efficient fine-tuning of pretrained models has shown promise in CL for image classification, we find it insufficient for CAQA. Our empirical and theoretical analyses reveal two insights: (i) Full-Parameter Fine-Tuning (FPFT) is necessary for effective representation learning; yet (ii) uncontrolled FPFT induces overfitting and feature manifold shift, thereby aggravating forgetting. To address this, we propose Adaptive Manifold-Aligned Graph Regularization (MAGR++), which couples backbone fine-tuning that stabilizes shallow layers while adapting deeper ones with a two-step feature rectification pipeline: a manifold projector to translate deviated historical features into the current representation space, and a graph regularizer to align local and global distributions. We construct four CAQA benchmarks from three datasets with tailored evaluation protocols and strong baselines, enabling systematic cross-dataset comparison. Extensive experiments show that MAGR++ achieves state-of-the-art performance, with average correlation gains of 3.6% offline and 12.2% online over the strongest baseline, confirming its robustness and effectiveness. Our code is available at https://github.com/ZhouKanglei/MAGRPP.
PHI: Bridging Domain Shift in Long-Term Action Quality Assessment via Progressive Hierarchical Instruction
May 26, 2025Long-term Action Quality Assessment (AQA) aims to evaluate the quantitative performance of actions in long videos. However, existing methods face challenges due to domain shifts between the pre-trained large-scale action recognition backbones and the specific AQA task, thereby hindering their performance. This arises since fine-tuning resource-intensive backbones on small AQA datasets is impractical. We address this by identifying two levels of domain shift: task-level, regarding differences in task objectives, and feature-level, regarding differences in important features. For feature-level shifts, which are more detrimental, we propose Progressive Hierarchical Instruction (PHI) with two strategies. First, Gap Minimization Flow (GMF) leverages flow matching to progressively learn a fast flow path that reduces the domain gap between initial and desired features across shallow to deep layers. Additionally, a temporally-enhanced attention module captures long-range dependencies essential for AQA. Second, List-wise Contrastive Regularization (LCR) facilitates coarse-to-fine alignment by comprehensively comparing batch pairs to learn fine-grained cues while mitigating domain shift. Integrating these modules, PHI offers an effective solution. Experiments demonstrate that PHI achieves state-of-the-art performance on three representative long-term AQA datasets, proving its superiority in addressing the domain shift for long-term AQA.
Large-Scale Multi-Character Interaction Synthesis
May 20, 2025Generating large-scale multi-character interactions is a challenging and important task in character animation. Multi-character interactions involve not only natural interactive motions but also characters coordinated with each other for transition. For example, a dance scenario involves characters dancing with partners and also characters coordinated to new partners based on spatial and temporal observations. We term such transitions as coordinated interactions and decompose them into interaction synthesis and transition planning. Previous methods of single-character animation do not consider interactions that are critical for multiple characters. Deep-learning-based interaction synthesis usually focuses on two characters and does not consider transition planning. Optimization-based interaction synthesis relies on manually designing objective functions that may not generalize well. While crowd simulation involves more characters, their interactions are sparse and passive. We identify two challenges to multi-character interaction synthesis, including the lack of data and the planning of transitions among close and dense interactions. Existing datasets either do not have multiple characters or do not have close and dense interactions. The planning of transitions for multi-character close and dense interactions needs both spatial and temporal considerations. We propose a conditional generative pipeline comprising a coordinatable multi-character interaction space for interaction synthesis and a transition planning network for coordinations. Our experiments demonstrate the effectiveness of our proposed pipeline for multicharacter interaction synthesis and the applications facilitated by our method show the scalability and transferability.
Using Fixed and Mobile Eye Tracking to Understand How Visitors View Art in a Museum: A Study at the Bowes Museum, County Durham, UK
Apr 28, 2025The following paper describes a collaborative project involving researchers at Durham University, and professionals at the Bowes Museum, Barnard Castle, County Durham, UK, during which we used fixed and mobile eye tracking to understand how visitors view art. Our study took place during summer 2024 and builds on work presented at DH2017 (Bailey-Ross et al., 2017). Our interdisciplinary team included researchers from digital humanities, psychology, art history and computer science, working in collaboration with professionals from the museum. We used fixed and mobile eye tracking to understand how museum visitors view art in a physical gallery setting. This research will enable us to make recommendations about how the Museum's collections could be more effectively displayed, encouraging visitors to engage with them more fully.