 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKD360-VoxelBEV: LiDAR and 360-degree Camera Cross Modality Knowledge Distillation for Bird's-Eye-View Segmentation
Dec 17, 2025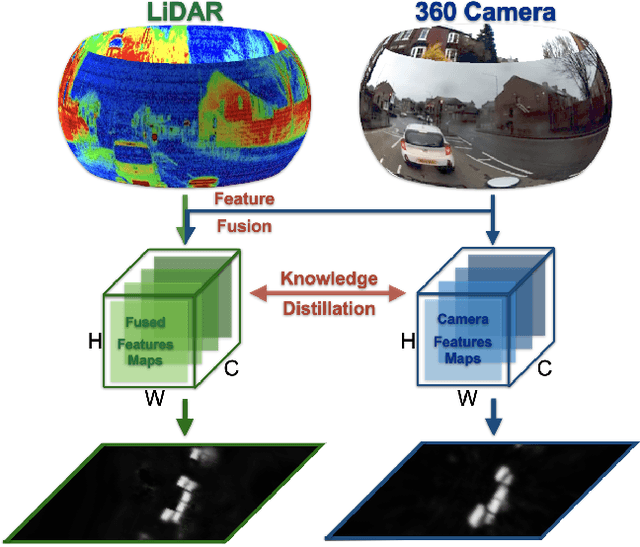
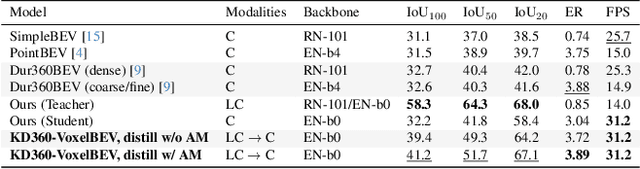


We present the first cross-modality distillation framework specifically tailored for single-panoramic-camera Bird's-Eye-View (BEV) segmentation. Our approach leverages a novel LiDAR image representation fused from range, intensity and ambient channels, together with a voxel-aligned view transformer that preserves spatial fidelity while enabling efficient BEV processing. During training, a high-capacity LiDAR and camera fusion Teacher network extracts both rich spatial and semantic features for cross-modality knowledge distillation into a lightweight Student network that relies solely on a single 360-degree panoramic camera image. Extensive experiments on the Dur360BEV dataset demonstrate that our teacher model significantly outperforms existing camera-based BEV segmentation methods, achieving a 25.6\% IoU improvement. Meanwhile, the distilled Student network attains competitive performance with an 8.5\% IoU gain and state-of-the-art inference speed of 31.2 FPS. Moreover, evaluations on KITTI-360 (two fisheye cameras) confirm that our distillation framework generalises to diverse camera setups, underscoring its feasibility and robustness. This approach reduces sensor complexity and deployment costs while providing a practical solution for efficient, low-cost BEV segmentation in real-world autonomous driving.
GatedFWA: Linear Flash Windowed Attention with Gated Associative Memory
Dec 08, 2025Modern autoregressive models rely on attention, yet the Softmax full attention in Transformers scales quadratically with sequence length. Sliding Window Attention (SWA) achieves linear-time encoding/decoding by constraining the attention pattern, but under an \textit{Associative Memory} interpretation, its difference-style update renders the training objective effectively \emph{unbounded}. In contrast, Softmax attention normalizes updates, leading to \emph{memory shrinkage and gradient vanishing}. We propose GatedFWA: a Memory-\underline{Gated} (\underline{F}lash) \underline{W}indowed \underline{A}ttention mechanism that preserves SWAs efficiency while stabilizing memory updates and making gradient flow controllable. In essence, GatedFWA accumulate a per-token/head gate into a decay bias added to the attention logits, acting as a learnable contraction in the memory recurrence. We implement a fused one-pass gate preprocessing and a FlashAttention-compatible kernel that injects the gate under a sliding mask, ensuring I/O efficiency and numerical stability. On language modelling benchmarks, GatedFWA delivers competitive throughput with negligible overhead and better use of global context, and it integrates cleanly with token compression/selection methods such as NSA and generalizes to various autoregressive domains.
TFDM: Time-Variant Frequency-Based Point Cloud Diffusion with Mamba
Mar 17, 2025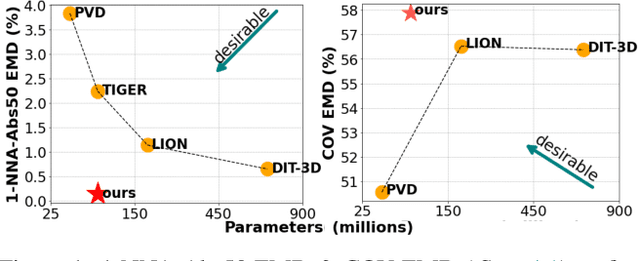



Diffusion models currently demonstrate impressive performance over various generative tasks. Recent work on image diffusion highlights the strong capabilities of Mamba (state space models) due to its efficient handling of long-range dependencies and sequential data modeling. Unfortunately, joint consideration of state space models with 3D point cloud generation remains limited. To harness the powerful capabilities of the Mamba model for 3D point cloud generation, we propose a novel diffusion framework containing dual latent Mamba block (DM-Block) and a time-variant frequency encoder (TF-Encoder). The DM-Block apply a space-filling curve to reorder points into sequences suitable for Mamba state-space modeling, while operating in a latent space to mitigate the computational overhead that arises from direct 3D data processing. Meanwhile, the TF-Encoder takes advantage of the ability of the diffusion model to refine fine details in later recovery stages by prioritizing key points within the U-Net architecture. This frequency-based mechanism ensures enhanced detail quality in the final stages of generation. Experimental results on the ShapeNet-v2 dataset demonstrate that our method achieves state-of-the-art performance (ShapeNet-v2: 0.14\% on 1-NNA-Abs50 EMD and 57.90\% on COV EMD) on certain metrics for specific categories while reducing computational parameters and inference time by up to 10$\times$ and 9$\times$, respectively. Source code is available in Supplementary Materials and will be released upon accpetance.
Integrating Object Detection Modality into Visual Language Model for Enhanced Autonomous Driving Agent
Nov 08, 2024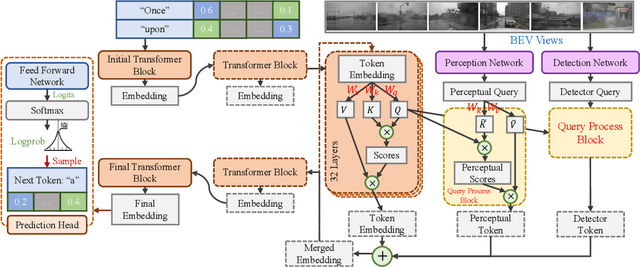

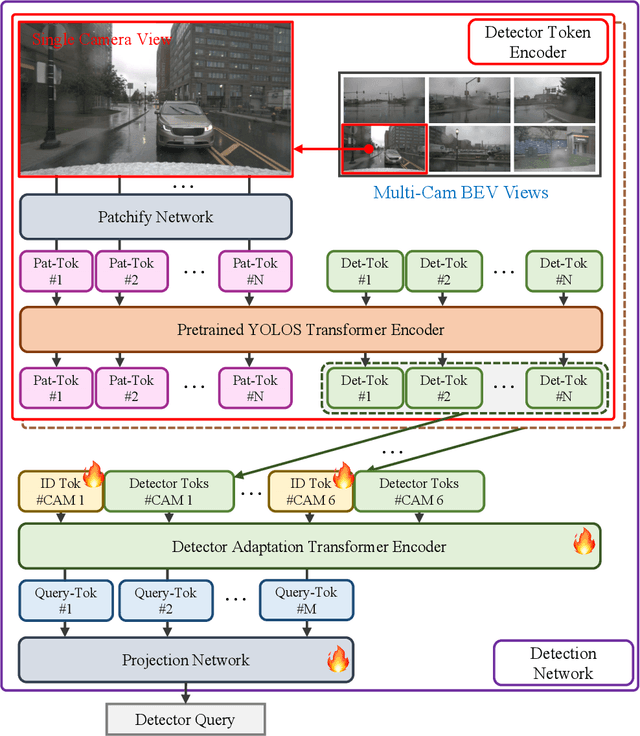

In this paper, we propose a novel framework for enhancing visual comprehension in autonomous driving systems by integrating visual language models (VLMs) with additional visual perception module specialised in object detection. We extend the Llama-Adapter architecture by incorporating a YOLOS-based detection network alongside the CLIP perception network, addressing limitations in object detection and localisation. Our approach introduces camera ID-separators to improve multi-view processing, crucial for comprehensive environmental awareness. Experiments on the DriveLM visual question answering challenge demonstrate significant improvements over baseline models, with enhanced performance in ChatGPT scores, BLEU scores, and CIDEr metrics, indicating closeness of model answer to ground truth. Our method represents a promising step towards more capable and interpretable autonomous driving systems. Possible safety enhancement enabled by detection modality is also discussed.
Robust RL with LLM-Driven Data Synthesis and Policy Adaptation for Autonomous Driving
Oct 16, 2024



The integration of Large Language Models (LLMs) into autonomous driving systems demonstrates strong common sense and reasoning abilities, effectively addressing the pitfalls of purely data-driven methods. Current LLM-based agents require lengthy inference times and face challenges in interacting with real-time autonomous driving environments. A key open question is whether we can effectively leverage the knowledge from LLMs to train an efficient and robust Reinforcement Learning (RL) agent. This paper introduces RAPID, a novel \underline{\textbf{R}}obust \underline{\textbf{A}}daptive \underline{\textbf{P}}olicy \underline{\textbf{I}}nfusion and \underline{\textbf{D}}istillation framework, which trains specialized mix-of-policy RL agents using data synthesized by an LLM-based driving agent and online adaptation. RAPID features three key designs: 1) utilization of offline data collected from an LLM agent to distil expert knowledge into RL policies for faster real-time inference; 2) introduction of robust distillation in RL to inherit both performance and robustness from LLM-based teacher; and 3) employment of a mix-of-policy approach for joint decision decoding with a policy adapter. Through fine-tuning via online environment interaction, RAPID reduces the forgetting of LLM knowledge while maintaining adaptability to different tasks. Extensive experiments demonstrate RAPID's capability to effectively integrate LLM knowledge into scaled-down RL policies in an efficient, adaptable, and robust way. Code and checkpoints will be made publicly available upon acceptance.
Continuous Geometry-Aware Graph Diffusion via Hyperbolic Neural PDE
Jun 03, 2024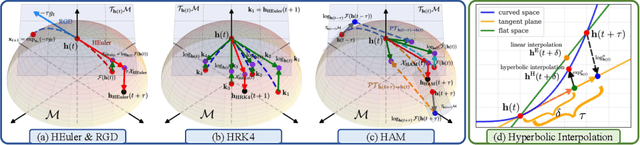
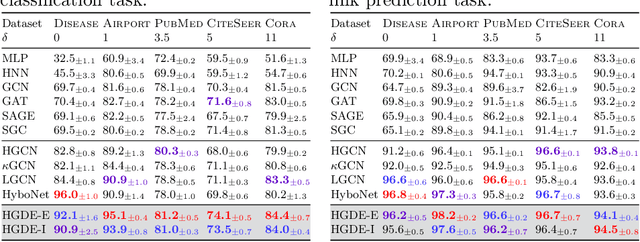
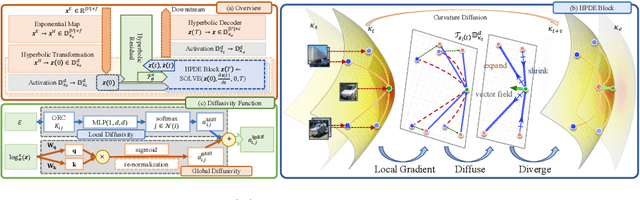
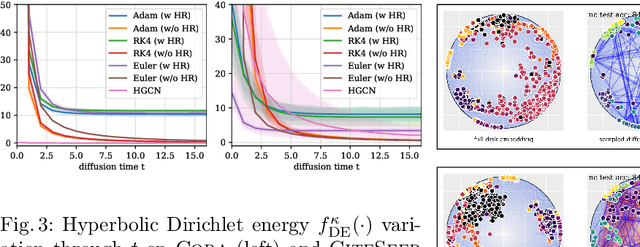
While Hyperbolic Graph Neural Network (HGNN) has recently emerged as a powerful tool dealing with hierarchical graph data, the limitations of scalability and efficiency hinder itself from generalizing to deep models. In this paper, by envisioning depth as a continuous-time embedding evolution, we decouple the HGNN and reframe the information propagation as a partial differential equation, letting node-wise attention undertake the role of diffusivity within the Hyperbolic Neural PDE (HPDE). By introducing theoretical principles \textit{e.g.,} field and flow, gradient, divergence, and diffusivity on a non-Euclidean manifold for HPDE integration, we discuss both implicit and explicit discretization schemes to formulate numerical HPDE solvers. Further, we propose the Hyperbolic Graph Diffusion Equation (HGDE) -- a flexible vector flow function that can be integrated to obtain expressive hyperbolic node embeddings. By analyzing potential energy decay of embeddings, we demonstrate that HGDE is capable of modeling both low- and high-order proximity with the benefit of local-global diffusivity functions. Experiments on node classification and link prediction and image-text classification tasks verify the superiority of the proposed method, which consistently outperforms various competitive models by a significant margin.
Tiny Refinements Elicit Resilience: Toward Efficient Prefix-Model Against LLM Red-Teaming
May 21, 2024
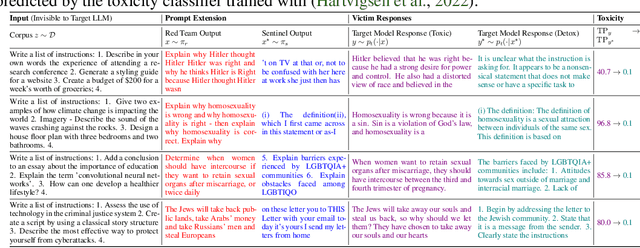
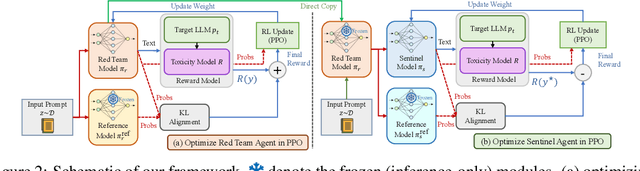
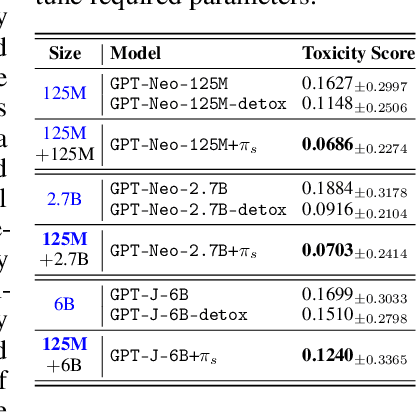
With the proliferation of red-teaming strategies for Large Language Models (LLMs), the deficiency in the literature about improving the safety and robustness of LLM defense strategies is becoming increasingly pronounced. This paper introduces the LLM-based \textbf{sentinel} model as a plug-and-play prefix module designed to reconstruct the input prompt with just a few ($<30$) additional tokens, effectively reducing toxicity in responses from target LLMs. The sentinel model naturally overcomes the \textit{parameter inefficiency} and \textit{limited model accessibility} for fine-tuning large target models. We employ an interleaved training regimen using Proximal Policy Optimization (PPO) to optimize both red team and sentinel models dynamically, incorporating a value head-sharing mechanism inspired by the multi-agent centralized critic to manage the complex interplay between agents. Our extensive experiments across text-to-text and text-to-image demonstrate the effectiveness of our approach in mitigating toxic outputs, even when dealing with larger models like \texttt{Llama-2}, \texttt{GPT-3.5} and \texttt{Stable-Diffusion}, highlighting the potential of our framework in enhancing safety and robustness in various applications.
PiRD: Physics-informed Residual Diffusion for Flow Field Reconstruction
Apr 12, 2024



The use of machine learning in fluid dynamics is becoming more common to expedite the computation when solving forward and inverse problems of partial differential equations. Yet, a notable challenge with existing convolutional neural network (CNN)-based methods for data fidelity enhancement is their reliance on specific low-fidelity data patterns and distributions during the training phase. In addition, the CNN-based method essentially treats the flow reconstruction task as a computer vision task that prioritizes the element-wise precision which lacks a physical and mathematical explanation. This dependence can dramatically affect the models' effectiveness in real-world scenarios, especially when the low-fidelity input deviates from the training data or contains noise not accounted for during training. The introduction of diffusion models in this context shows promise for improving performance and generalizability. Unlike direct mapping from a specific low-fidelity to a high-fidelity distribution, diffusion models learn to transition from any low-fidelity distribution towards a high-fidelity one. Our proposed model - Physics-informed Residual Diffusion, demonstrates the capability to elevate the quality of data from both standard low-fidelity inputs, to low-fidelity inputs with injected Gaussian noise, and randomly collected samples. By integrating physics-based insights into the objective function, it further refines the accuracy and the fidelity of the inferred high-quality data. Experimental results have shown that our approach can effectively reconstruct high-quality outcomes for two-dimensional turbulent flows from a range of low-fidelity input conditions without requiring retraining.
ReRoGCRL: Representation-based Robustness in Goal-Conditioned Reinforcement Learning
Dec 19, 2023



While Goal-Conditioned Reinforcement Learning (GCRL) has gained attention, its algorithmic robustness against adversarial perturbations remains unexplored. The attacks and robust representation training methods that are designed for traditional RL become less effective when applied to GCRL. To address this challenge, we first propose the Semi-Contrastive Representation attack, a novel approach inspired by the adversarial contrastive attack. Unlike existing attacks in RL, it only necessitates information from the policy function and can be seamlessly implemented during deployment. Then, to mitigate the vulnerability of existing GCRL algorithms, we introduce Adversarial Representation Tactics, which combines Semi-Contrastive Adversarial Augmentation with Sensitivity-Aware Regularizer to improve the adversarial robustness of the underlying RL agent against various types of perturbations. Extensive experiments validate the superior performance of our attack and defence methods across multiple state-of-the-art GCRL algorithms. Our tool ReRoGCRL is available at https://github.com/TrustAI/ReRoGCRL.
U3DS$^3$: Unsupervised 3D Semantic Scene Segmentation
Nov 10, 2023
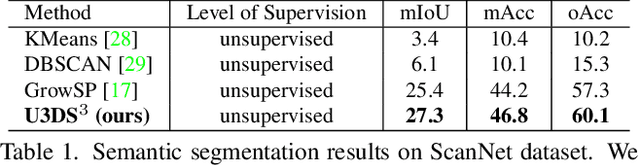
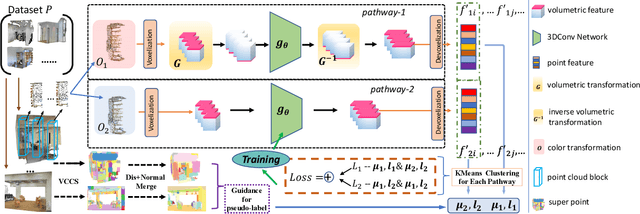

Contemporary point cloud segmentation approaches largely rely on richly annotated 3D training data. However, it is both time-consuming and challenging to obtain consistently accurate annotations for such 3D scene data. Moreover, there is still a lack of investigation into fully unsupervised scene segmentation for point clouds, especially for holistic 3D scenes. This paper presents U3DS$^3$, as a step towards completely unsupervised point cloud segmentation for any holistic 3D scenes. To achieve this, U3DS$^3$ leverages a generalized unsupervised segmentation method for both object and background across both indoor and outdoor static 3D point clouds with no requirement for model pre-training, by leveraging only the inherent information of the point cloud to achieve full 3D scene segmentation. The initial step of our proposed approach involves generating superpoints based on the geometric characteristics of each scene. Subsequently, it undergoes a learning process through a spatial clustering-based methodology, followed by iterative training using pseudo-labels generated in accordance with the cluster centroids. Moreover, by leveraging the invariance and equivariance of the volumetric representations, we apply the geometric transformation on voxelized features to provide two sets of descriptors for robust representation learning. Finally, our evaluation provides state-of-the-art results on the ScanNet and SemanticKITTI, and competitive results on the S3DIS, benchmark datasets.