 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeometric Neural Distance Fields for Learning Human Motion Priors
Sep 11, 2025We introduce Neural Riemannian Motion Fields (NRMF), a novel 3D generative human motion prior that enables robust, temporally consistent, and physically plausible 3D motion recovery. Unlike existing VAE or diffusion-based methods, our higher-order motion prior explicitly models the human motion in the zero level set of a collection of neural distance fields (NDFs) corresponding to pose, transition (velocity), and acceleration dynamics. Our framework is rigorous in the sense that our NDFs are constructed on the product space of joint rotations, their angular velocities, and angular accelerations, respecting the geometry of the underlying articulations. We further introduce: (i) a novel adaptive-step hybrid algorithm for projecting onto the set of plausible motions, and (ii) a novel geometric integrator to "roll out" realistic motion trajectories during test-time-optimization and generation. Our experiments show significant and consistent gains: trained on the AMASS dataset, NRMF remarkably generalizes across multiple input modalities and to diverse tasks ranging from denoising to motion in-betweening and fitting to partial 2D / 3D observations.
Dyn-HaMR: Recovering 4D Interacting Hand Motion from a Dynamic Camera
Dec 18, 2024



We propose Dyn-HaMR, to the best of our knowledge, the first approach to reconstruct 4D global hand motion from monocular videos recorded by dynamic cameras in the wild. Reconstructing accurate 3D hand meshes from monocular videos is a crucial task for understanding human behaviour, with significant applications in augmented and virtual reality (AR/VR). However, existing methods for monocular hand reconstruction typically rely on a weak perspective camera model, which simulates hand motion within a limited camera frustum. As a result, these approaches struggle to recover the full 3D global trajectory and often produce noisy or incorrect depth estimations, particularly when the video is captured by dynamic or moving cameras, which is common in egocentric scenarios. Our Dyn-HaMR consists of a multi-stage, multi-objective optimization pipeline, that factors in (i) simultaneous localization and mapping (SLAM) to robustly estimate relative camera motion, (ii) an interacting-hand prior for generative infilling and to refine the interaction dynamics, ensuring plausible recovery under (self-)occlusions, and (iii) hierarchical initialization through a combination of state-of-the-art hand tracking methods. Through extensive evaluations on both in-the-wild and indoor datasets, we show that our approach significantly outperforms state-of-the-art methods in terms of 4D global mesh recovery. This establishes a new benchmark for hand motion reconstruction from monocular video with moving cameras. Our project page is at https://dyn-hamr.github.io/.
U3DS$^3$: Unsupervised 3D Semantic Scene Segmentation
Nov 10, 2023
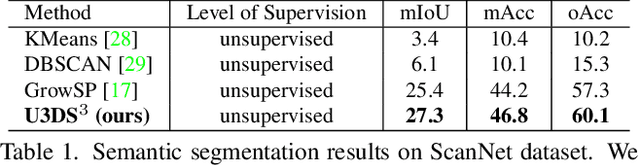
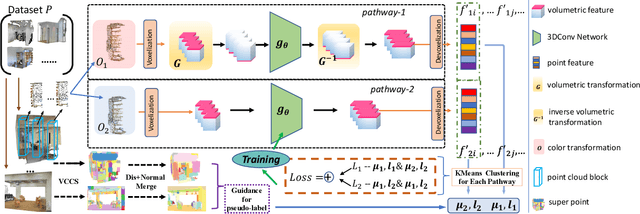

Contemporary point cloud segmentation approaches largely rely on richly annotated 3D training data. However, it is both time-consuming and challenging to obtain consistently accurate annotations for such 3D scene data. Moreover, there is still a lack of investigation into fully unsupervised scene segmentation for point clouds, especially for holistic 3D scenes. This paper presents U3DS$^3$, as a step towards completely unsupervised point cloud segmentation for any holistic 3D scenes. To achieve this, U3DS$^3$ leverages a generalized unsupervised segmentation method for both object and background across both indoor and outdoor static 3D point clouds with no requirement for model pre-training, by leveraging only the inherent information of the point cloud to achieve full 3D scene segmentation. The initial step of our proposed approach involves generating superpoints based on the geometric characteristics of each scene. Subsequently, it undergoes a learning process through a spatial clustering-based methodology, followed by iterative training using pseudo-labels generated in accordance with the cluster centroids. Moreover, by leveraging the invariance and equivariance of the volumetric representations, we apply the geometric transformation on voxelized features to provide two sets of descriptors for robust representation learning. Finally, our evaluation provides state-of-the-art results on the ScanNet and SemanticKITTI, and competitive results on the S3DIS, benchmark datasets.
SignAvatars: A Large-scale 3D Sign Language Holistic Motion Dataset and Benchmark
Oct 31, 2023
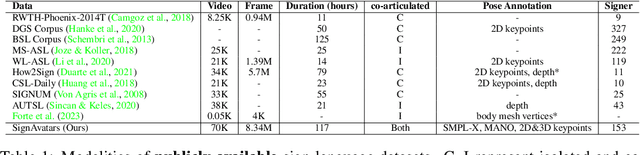

In this paper, we present SignAvatars, the first large-scale multi-prompt 3D sign language (SL) motion dataset designed to bridge the communication gap for hearing-impaired individuals. While there has been an exponentially growing number of research regarding digital communication, the majority of existing communication technologies primarily cater to spoken or written languages, instead of SL, the essential communication method for hearing-impaired communities. Existing SL datasets, dictionaries, and sign language production (SLP) methods are typically limited to 2D as the annotating 3D models and avatars for SL is usually an entirely manual and labor-intensive process conducted by SL experts, often resulting in unnatural avatars. In response to these challenges, we compile and curate the SignAvatars dataset, which comprises 70,000 videos from 153 signers, totaling 8.34 million frames, covering both isolated signs and continuous, co-articulated signs, with multiple prompts including HamNoSys, spoken language, and words. To yield 3D holistic annotations, including meshes and biomechanically-valid poses of body, hands, and face, as well as 2D and 3D keypoints, we introduce an automated annotation pipeline operating on our large corpus of SL videos. SignAvatars facilitates various tasks such as 3D sign language recognition (SLR) and the novel 3D SL production (SLP) from diverse inputs like text scripts, individual words, and HamNoSys notation. Hence, to evaluate the potential of SignAvatars, we further propose a unified benchmark of 3D SL holistic motion production. We believe that this work is a significant step forward towards bringing the digital world to the hearing-impaired communities. Our project page is at https://signavatars.github.io/
Decomposed Human Motion Prior for Video Pose Estimation via Adversarial Training
May 31, 2023



Estimating human pose from video is a task that receives considerable attention due to its applicability in numerous 3D fields. The complexity of prior knowledge of human body movements poses a challenge to neural network models in the task of regressing keypoints. In this paper, we address this problem by incorporating motion prior in an adversarial way. Different from previous methods, we propose to decompose holistic motion prior to joint motion prior, making it easier for neural networks to learn from prior knowledge thereby boosting the performance on the task. We also utilize a novel regularization loss to balance accuracy and smoothness introduced by motion prior. Our method achieves 9\% lower PA-MPJPE and 29\% lower acceleration error than previous methods tested on 3DPW. The estimator proves its robustness by achieving impressive performance on in-the-wild dataset.
ACR: Attention Collaboration-based Regressor for Arbitrary Two-Hand Reconstruction
Mar 10, 2023



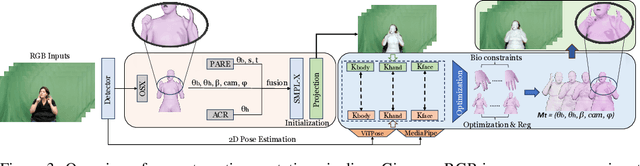
Reconstructing two hands from monocular RGB images is challenging due to frequent occlusion and mutual confusion. Existing methods mainly learn an entangled representation to encode two interacting hands, which are incredibly fragile to impaired interaction, such as truncated hands, separate hands, or external occlusion. This paper presents ACR (Attention Collaboration-based Regressor), which makes the first attempt to reconstruct hands in arbitrary scenarios. To achieve this, ACR explicitly mitigates interdependencies between hands and between parts by leveraging center and part-based attention for feature extraction. However, reducing interdependence helps release the input constraint while weakening the mutual reasoning about reconstructing the interacting hands. Thus, based on center attention, ACR also learns cross-hand prior that handle the interacting hands better. We evaluate our method on various types of hand reconstruction datasets. Our method significantly outperforms the best interacting-hand approaches on the InterHand2.6M dataset while yielding comparable performance with the state-of-the-art single-hand methods on the FreiHand dataset. More qualitative results on in-the-wild and hand-object interaction datasets and web images/videos further demonstrate the effectiveness of our approach for arbitrary hand reconstruction. Our code is available at https://github.com/ZhengdiYu/Arbitrary-Hands-3D-Reconstruction.
RangeUDF: Semantic Surface Reconstruction from 3D Point Clouds
Apr 19, 2022

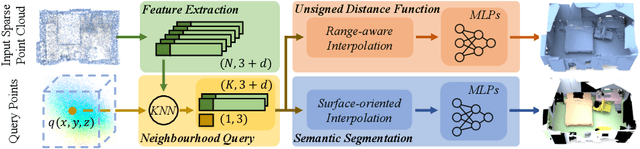
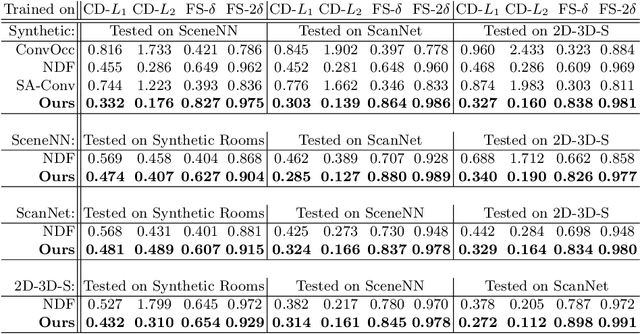
We present RangeUDF, a new implicit representation based framework to recover the geometry and semantics of continuous 3D scene surfaces from point clouds. Unlike occupancy fields or signed distance fields which can only model closed 3D surfaces, our approach is not restricted to any type of topology. Being different from the existing unsigned distance fields, our framework does not suffer from any surface ambiguity. In addition, our RangeUDF can jointly estimate precise semantics for continuous surfaces. The key to our approach is a range-aware unsigned distance function together with a surface-oriented semantic segmentation module. Extensive experiments show that RangeUDF clearly surpasses state-of-the-art approaches for surface reconstruction on four point cloud datasets. Moreover, RangeUDF demonstrates superior generalization capability across multiple unseen datasets, which is nearly impossible for all existing approaches.
P2-Net: Joint Description and Detection of Local Features for Pixel and Point Matching
Mar 01, 2021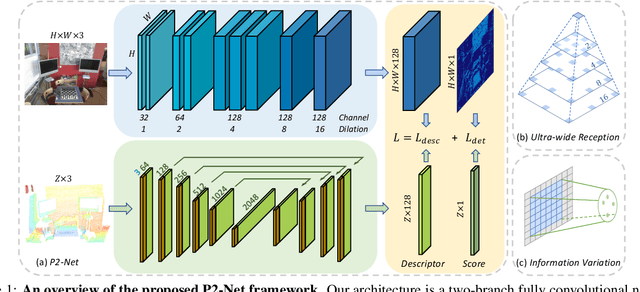
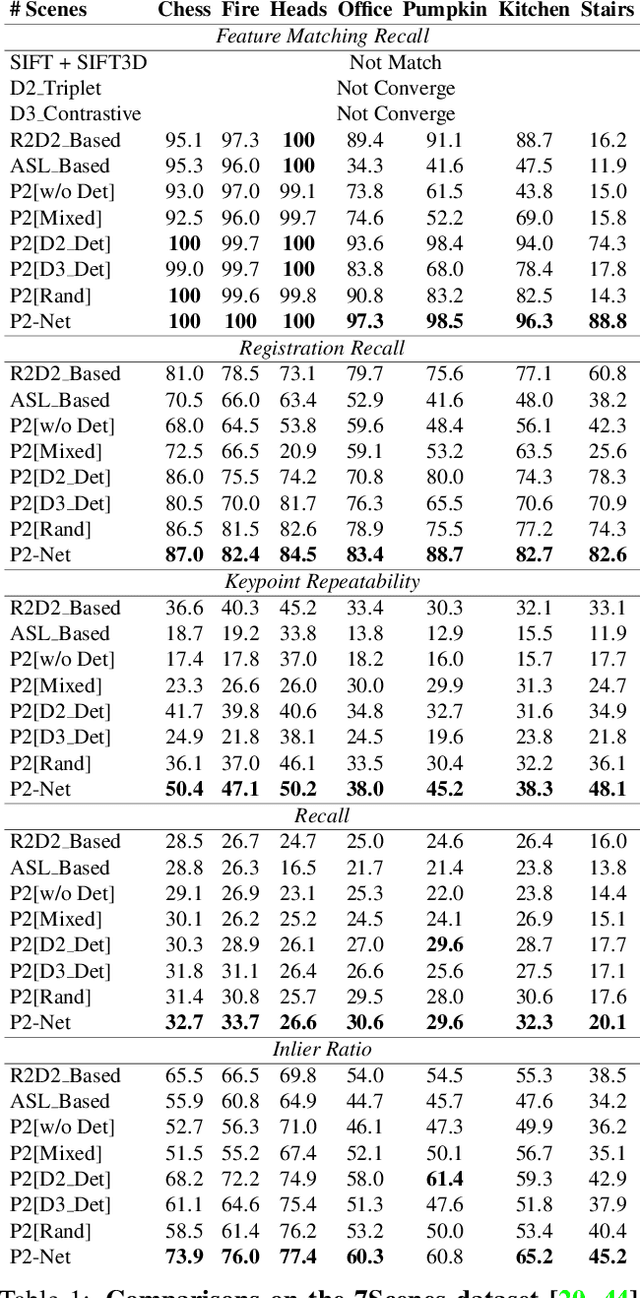
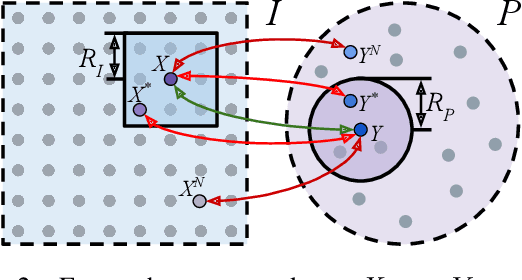
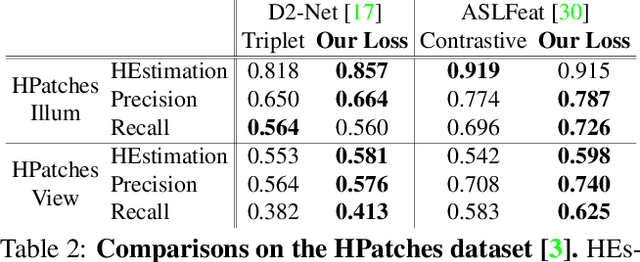
Accurately describing and detecting 2D and 3D keypoints is crucial to establishing correspondences across images and point clouds. Despite a plethora of learning-based 2D or 3D local feature descriptors and detectors having been proposed, the derivation of a shared descriptor and joint keypoint detector that directly matches pixels and points remains under-explored by the community. This work takes the initiative to establish fine-grained correspondences between 2D images and 3D point clouds. In order to directly match pixels and points, a dual fully convolutional framework is presented that maps 2D and 3D inputs into a shared latent representation space to simultaneously describe and detect keypoints. Furthermore, an ultra-wide reception mechanism in combination with a novel loss function are designed to mitigate the intrinsic information variations between pixel and point local regions. Extensive experimental results demonstrate that our framework shows competitive performance in fine-grained matching between images and point clouds and achieves state-of-the-art results for the task of indoor visual localization. Our source code will be available at [no-name-for-blind-review].