 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaDiS: Taming Masked Diffusion Language Models for Sign Language Generation
Jan 27, 2026Sign language generation (SLG) aims to translate written texts into expressive sign motions, bridging communication barriers for the Deaf and Hard-of-Hearing communities. Recent studies formulate SLG within the language modeling framework using autoregressive language models, which suffer from unidirectional context modeling and slow token-by-token inference. To address these limitations, we present MaDiS, a masked-diffusion-based language model for SLG that captures bidirectional dependencies and supports efficient parallel multi-token generation. We further introduce a tri-level cross-modal pretraining scheme that jointly learns from token-, latent-, and 3D physical-space objectives, leading to richer and more grounded sign representations. To accelerate model convergence in the fine-tuning stage, we design a novel unmasking strategy with temporal checkpoints, reducing the combinatorial complexity of unmasking orders by over $10^{41}$ times. In addition, a mixture-of-parts embedding layer is developed to effectively fuse information stored in different part-wise sign tokens through learnable gates and well-optimized codebooks. Extensive experiments on CSL-Daily, Phoenix-2014T, and How2Sign demonstrate that MaDiS achieves superior performance across multiple metrics, including DTW error and two newly introduced metrics, SiBLEU and SiCLIP, while reducing inference latency by nearly 30%. Code and models will be released on our project page.
An Anatomy of Vision-Language-Action Models: From Modules to Milestones and Challenges
Dec 19, 2025Vision-Language-Action (VLA) models are driving a revolution in robotics, enabling machines to understand instructions and interact with the physical world. This field is exploding with new models and datasets, making it both exciting and challenging to keep pace with. This survey offers a clear and structured guide to the VLA landscape. We design it to follow the natural learning path of a researcher: we start with the basic Modules of any VLA model, trace the history through key Milestones, and then dive deep into the core Challenges that define recent research frontier. Our main contribution is a detailed breakdown of the five biggest challenges in: (1) Representation, (2) Execution, (3) Generalization, (4) Safety, and (5) Dataset and Evaluation. This structure mirrors the developmental roadmap of a generalist agent: establishing the fundamental perception-action loop, scaling capabilities across diverse embodiments and environments, and finally ensuring trustworthy deployment-all supported by the essential data infrastructure. For each of them, we review existing approaches and highlight future opportunities. We position this paper as both a foundational guide for newcomers and a strategic roadmap for experienced researchers, with the dual aim of accelerating learning and inspiring new ideas in embodied intelligence. A live version of this survey, with continuous updates, is maintained on our \href{https://suyuz1.github.io/VLA-Survey-Anatomy/}{project page}.
STARCaster: Spatio-Temporal AutoRegressive Video Diffusion for Identity- and View-Aware Talking Portraits
Dec 15, 2025


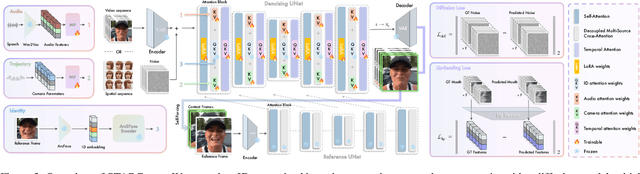
This paper presents STARCaster, an identity-aware spatio-temporal video diffusion model that addresses both speech-driven portrait animation and free-viewpoint talking portrait synthesis, given an identity embedding or reference image, within a unified framework. Existing 2D speech-to-video diffusion models depend heavily on reference guidance, leading to limited motion diversity. At the same time, 3D-aware animation typically relies on inversion through pre-trained tri-plane generators, which often leads to imperfect reconstructions and identity drift. We rethink reference- and geometry-based paradigms in two ways. First, we deviate from strict reference conditioning at pre-training by introducing softer identity constraints. Second, we address 3D awareness implicitly within the 2D video domain by leveraging the inherent multi-view nature of video data. STARCaster adopts a compositional approach progressing from ID-aware motion modeling, to audio-visual synchronization via lip reading-based supervision, and finally to novel view animation through temporal-to-spatial adaptation. To overcome the scarcity of 4D audio-visual data, we propose a decoupled learning approach in which view consistency and temporal coherence are trained independently. A self-forcing training scheme enables the model to learn from longer temporal contexts than those generated at inference, mitigating the overly static animations common in existing autoregressive approaches. Comprehensive evaluations demonstrate that STARCaster generalizes effectively across tasks and identities, consistently surpassing prior approaches in different benchmarks.
EEG-D3: A Solution to the Hidden Overfitting Problem of Deep Learning Models
Dec 15, 2025Deep learning for decoding EEG signals has gained traction, with many claims to state-of-the-art accuracy. However, despite the convincing benchmark performance, successful translation to real applications is limited. The frequent disconnect between performance on controlled BCI benchmarks and its lack of generalisation to practical settings indicates hidden overfitting problems. We introduce Disentangled Decoding Decomposition (D3), a weakly supervised method for training deep learning models across EEG datasets. By predicting the place in the respective trial sequence from which the input window was sampled, EEG-D3 separates latent components of brain activity, akin to non-linear ICA. We utilise a novel model architecture with fully independent sub-networks for strict interpretability. We outline a feature interpretation paradigm to contrast the component activation profiles on different datasets and inspect the associated temporal and spatial filters. The proposed method reliably separates latent components of brain activity on motor imagery data. Training downstream classifiers on an appropriate subset of these components prevents hidden overfitting caused by task-correlated artefacts, which severely affects end-to-end classifiers. We further exploit the linearly separable latent space for effective few-shot learning on sleep stage classification. The ability to distinguish genuine components of brain activity from spurious features results in models that avoid the hidden overfitting problem and generalise well to real-world applications, while requiring only minimal labelled data. With interest to the neuroscience community, the proposed method gives researchers a tool to separate individual brain processes and potentially even uncover heretofore unknown dynamics.
ID-Consistent, Precise Expression Generation with Blendshape-Guided Diffusion
Oct 06, 2025
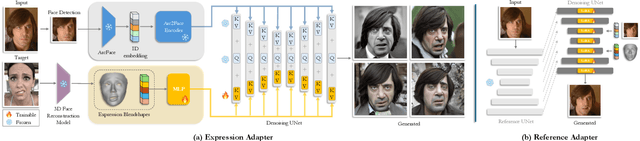
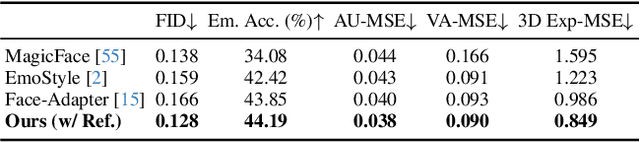

Human-centric generative models designed for AI-driven storytelling must bring together two core capabilities: identity consistency and precise control over human performance. While recent diffusion-based approaches have made significant progress in maintaining facial identity, achieving fine-grained expression control without compromising identity remains challenging. In this work, we present a diffusion-based framework that faithfully reimagines any subject under any particular facial expression. Building on an ID-consistent face foundation model, we adopt a compositional design featuring an expression cross-attention module guided by FLAME blendshape parameters for explicit control. Trained on a diverse mixture of image and video data rich in expressive variation, our adapter generalizes beyond basic emotions to subtle micro-expressions and expressive transitions, overlooked by prior works. In addition, a pluggable Reference Adapter enables expression editing in real images by transferring the appearance from a reference frame during synthesis. Extensive quantitative and qualitative evaluations show that our model outperforms existing methods in tailored and identity-consistent expression generation. Code and models can be found at https://github.com/foivospar/Arc2Face.
Embodied Arena: A Comprehensive, Unified, and Evolving Evaluation Platform for Embodied AI
Sep 18, 2025Embodied AI development significantly lags behind large foundation models due to three critical challenges: (1) lack of systematic understanding of core capabilities needed for Embodied AI, making research lack clear objectives; (2) absence of unified and standardized evaluation systems, rendering cross-benchmark evaluation infeasible; and (3) underdeveloped automated and scalable acquisition methods for embodied data, creating critical bottlenecks for model scaling. To address these obstacles, we present Embodied Arena, a comprehensive, unified, and evolving evaluation platform for Embodied AI. Our platform establishes a systematic embodied capability taxonomy spanning three levels (perception, reasoning, task execution), seven core capabilities, and 25 fine-grained dimensions, enabling unified evaluation with systematic research objectives. We introduce a standardized evaluation system built upon unified infrastructure supporting flexible integration of 22 diverse benchmarks across three domains (2D/3D Embodied Q&A, Navigation, Task Planning) and 30+ advanced models from 20+ worldwide institutes. Additionally, we develop a novel LLM-driven automated generation pipeline ensuring scalable embodied evaluation data with continuous evolution for diversity and comprehensiveness. Embodied Arena publishes three real-time leaderboards (Embodied Q&A, Navigation, Task Planning) with dual perspectives (benchmark view and capability view), providing comprehensive overviews of advanced model capabilities. Especially, we present nine findings summarized from the evaluation results on the leaderboards of Embodied Arena. This helps to establish clear research veins and pinpoint critical research problems, thereby driving forward progress in the field of Embodied AI.
Geometric Neural Distance Fields for Learning Human Motion Priors
Sep 11, 2025We introduce Neural Riemannian Motion Fields (NRMF), a novel 3D generative human motion prior that enables robust, temporally consistent, and physically plausible 3D motion recovery. Unlike existing VAE or diffusion-based methods, our higher-order motion prior explicitly models the human motion in the zero level set of a collection of neural distance fields (NDFs) corresponding to pose, transition (velocity), and acceleration dynamics. Our framework is rigorous in the sense that our NDFs are constructed on the product space of joint rotations, their angular velocities, and angular accelerations, respecting the geometry of the underlying articulations. We further introduce: (i) a novel adaptive-step hybrid algorithm for projecting onto the set of plausible motions, and (ii) a novel geometric integrator to "roll out" realistic motion trajectories during test-time-optimization and generation. Our experiments show significant and consistent gains: trained on the AMASS dataset, NRMF remarkably generalizes across multiple input modalities and to diverse tasks ranging from denoising to motion in-betweening and fitting to partial 2D / 3D observations.
Large Learning Rates Simultaneously Achieve Robustness to Spurious Correlations and Compressibility
Jul 23, 2025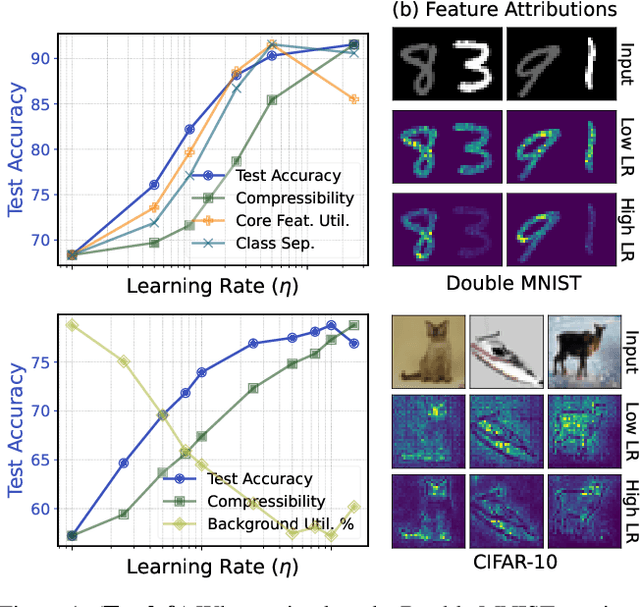



Robustness and resource-efficiency are two highly desirable properties for modern machine learning models. However, achieving them jointly remains a challenge. In this paper, we position high learning rates as a facilitator for simultaneously achieving robustness to spurious correlations and network compressibility. We demonstrate that large learning rates also produce desirable representation properties such as invariant feature utilization, class separation, and activation sparsity. Importantly, our findings indicate that large learning rates compare favorably to other hyperparameters and regularization methods, in consistently satisfying these properties in tandem. In addition to demonstrating the positive effect of large learning rates across diverse spurious correlation datasets, models, and optimizers, we also present strong evidence that the previously documented success of large learning rates in standard classification tasks is likely due to its effect on addressing hidden/rare spurious correlations in the training dataset.
Are Large Brainwave Foundation Models Capable Yet? Insights from Fine-tuning
Jul 01, 2025Foundation Models have demonstrated significant success across various domains in Artificial Intelligence (AI), yet their capabilities for brainwave modeling remain unclear. In this paper, we comprehensively evaluate current Large Brainwave Foundation Models (LBMs) through systematic fine-tuning experiments across multiple Brain-Computer Interface (BCI) benchmark tasks, including memory tasks and sleep stage classification. Our extensive analysis shows that state-of-the-art LBMs achieve only marginal improvements (0.9%-1.2%) over traditional deep architectures while requiring significantly more parameters (millions vs thousands), raising important questions about their efficiency and applicability in BCI contexts. Moreover, through detailed ablation studies and Low-Rank Adaptation (LoRA), we significantly reduce trainable parameters without performance degradation, while demonstrating that architectural and training inefficiencies limit LBMs' current capabilities. Our experiments span both full model fine-tuning and parameter-efficient adaptation techniques, providing insights into optimal training strategies for BCI applications. We pioneer the application of LoRA to LBMs, revealing that performance benefits generally emerge when adapting multiple neural network components simultaneously. These findings highlight the critical need for domain-specific development strategies to advance LBMs, suggesting that current architectures may require redesign to fully leverage the potential of foundation models in brainwave analysis.
Advancing Brainwave Modeling with a Codebook-Based Foundation Model
May 22, 2025Recent advances in large-scale pre-trained Electroencephalogram (EEG) models have shown great promise, driving progress in Brain-Computer Interfaces (BCIs) and healthcare applications. However, despite their success, many existing pre-trained models have struggled to fully capture the rich information content of neural oscillations, a limitation that fundamentally constrains their performance and generalizability across diverse BCI tasks. This limitation is frequently rooted in suboptimal architectural design choices which constrain their representational capacity. In this work, we introduce LaBraM++, an enhanced Large Brainwave Foundation Model (LBM) that incorporates principled improvements grounded in robust signal processing foundations. LaBraM++ demonstrates substantial gains across a variety of tasks, consistently outperforming its originally-based architecture and achieving competitive results when compared to other open-source LBMs. Its superior performance and training efficiency highlight its potential as a strong foundation for future advancements in LBMs.