 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntelliCode: A Multi-Agent LLM Tutoring System with Centralized Learner Modeling
Dec 21, 2025LLM-based tutors are typically single-turn assistants that lack persistent representations of learner knowledge, making it difficult to provide principled, transparent, and long-term pedagogical support. We introduce IntelliCode, a multi-agent LLM tutoring system built around a centralized, versioned learner state that integrates mastery estimates, misconceptions, review schedules, and engagement signals. A StateGraph Orchestrator coordinates six specialized agents: skill assessment, learner profiling, graduated hinting, curriculum selection, spaced repetition, and engagement monitoring, each operating as a pure transformation over the shared state under a single-writer policy. This architecture enables auditable mastery updates, proficiency-aware hints, dependency-aware curriculum adaptation, and safety-aligned prompting. The demo showcases an end-to-end tutoring workflow: a learner attempts a DSA problem, receives a conceptual hint when stuck, submits a corrected solution, and immediately sees mastery updates and a personalized review interval. We report validation results with simulated learners, showing stable state updates, improved task success with graduated hints, and diverse curriculum coverage. IntelliCode demonstrates how persistent learner modeling, orchestrated multi-agent reasoning, and principled instructional design can be combined to produce transparent and reliable LLM-driven tutoring.
CSGaze: Context-aware Social Gaze Prediction
Nov 14, 2025A person's gaze offers valuable insights into their focus of attention, level of social engagement, and confidence. In this work, we investigate how contextual cues combined with visual scene and facial information can be effectively utilized to predict and interpret social gaze patterns during conversational interactions. We introduce CSGaze, a context aware multimodal approach that leverages facial, scene information as complementary inputs to enhance social gaze pattern prediction from multi-person images. The model also incorporates a fine-grained attention mechanism centered on the principal speaker, which helps in better modeling social gaze dynamics. Experimental results show that CSGaze performs competitively with state-of-the-art methods on GP-Static, UCO-LAEO and AVA-LAEO. Our findings highlight the role of contextual cues in improving social gaze prediction. Additionally, we provide initial explainability through generated attention scores, offering insights into the model's decision-making process. We also demonstrate our model's generalizability by testing our model on open set datasets that demonstrating its robustness across diverse scenarios.
mmJEE-Eval: A Bilingual Multimodal Benchmark for Evaluating Scientific Reasoning in Vision-Language Models
Nov 12, 2025



Contemporary vision-language models (VLMs) perform well on existing multimodal reasoning benchmarks (78-85\% accuracy on MMMU, MathVista). Yet, these results fail to sufficiently distinguish true scientific reasoning articulation capabilities from pattern-matching. To address this gap, we introduce \textbf{mmJEE-Eval}, a multimodal bilingual (English and Hindi) benchmark comprising 1,460 questions from India's JEE Advanced examination (2019-2025) spanning pre-college Physics, Chemistry, and Mathematics domains. Our evaluation of 17 state-of-the-art models reveals that while frontier VLMs (GPT-5, Gemini 2.5 Pro/Flash) achieve 77-84\% accuracy on held-out 2025 questions, open-source models plateau at 37-45\% despite scaling to 400B parameters, a significant difference not observed on existing benchmarks. While closed frontiers from Google and OpenAI show high problem-solving accuracies (up to 100\% pass@3 scores), they fully collapse when the reasoning load is increased meta-cognitively (GPT-5 fixes just 5.2\% errors). Systematic ablations show mmJEE-Eval's difficulty stems from complexity and reasoning depth rather than memorization. Effectively, our benchmark segregates superior training and reasoning methodologies where alternatives fail. We publicly release our code and data: https://mmjee-eval.github.io
Developing a Transferable Federated Network Intrusion Detection System
Aug 12, 2025Intrusion Detection Systems (IDS) are a vital part of a network-connected device. In this paper, we develop a deep learning based intrusion detection system that is deployed in a distributed setup across devices connected to a network. Our aim is to better equip deep learning models against unknown attacks using knowledge from known attacks. To this end, we develop algorithms to maximize the number of transferability relationships. We propose a Convolutional Neural Network (CNN) model, along with two algorithms that maximize the number of relationships observed. One is a two step data pre-processing stage, and the other is a Block-Based Smart Aggregation (BBSA) algorithm. The proposed system succeeds in achieving superior transferability performance while maintaining impressive local detection rates. We also show that our method is generalizable, exhibiting transferability potential across datasets and even with different backbones. The code for this work can be found at https://github.com/ghosh64/tabfidsv2.
FetFIDS: A Feature Embedding Attention based Federated Network Intrusion Detection Algorithm
Aug 12, 2025Intrusion Detection Systems (IDS) have an increasingly important role in preventing exploitation of network vulnerabilities by malicious actors. Recent deep learning based developments have resulted in significant improvements in the performance of IDS systems. In this paper, we present FetFIDS, where we explore the employment of feature embedding instead of positional embedding to improve intrusion detection performance of a transformer based deep learning system. Our model is developed with the aim of deployments in edge learning scenarios, where federated learning over multiple communication rounds can ensure both privacy and localized performance improvements. FetFIDS outperforms multiple state-of-the-art intrusion detection systems in a federated environment and demonstrates a high degree of suitability to federated learning. The code for this work can be found at https://github.com/ghosh64/fetfids.
Gems: Group Emotion Profiling Through Multimodal Situational Understanding
Jul 30, 2025Understanding individual, group and event level emotions along with contextual information is crucial for analyzing a multi-person social situation. To achieve this, we frame emotion comprehension as the task of predicting fine-grained individual emotion to coarse grained group and event level emotion. We introduce GEMS that leverages a multimodal swin-transformer and S3Attention based architecture, which processes an input scene, group members, and context information to generate joint predictions. Existing multi-person emotion related benchmarks mainly focus on atomic interactions primarily based on emotion perception over time and group level. To this end, we extend and propose VGAF-GEMS to provide more fine grained and holistic analysis on top of existing group level annotation of VGAF dataset. GEMS aims to predict basic discrete and continuous emotions (including valence and arousal) as well as individual, group and event level perceived emotions. Our benchmarking effort links individual, group and situational emotional responses holistically. The quantitative and qualitative comparisons with adapted state-of-the-art models demonstrate the effectiveness of GEMS framework on VGAF-GEMS benchmarking. We believe that it will pave the way of further research. The code and data is available at: https://github.com/katariaak579/GEMS
AV-Deepfake1M++: A Large-Scale Audio-Visual Deepfake Benchmark with Real-World Perturbations
Jul 28, 2025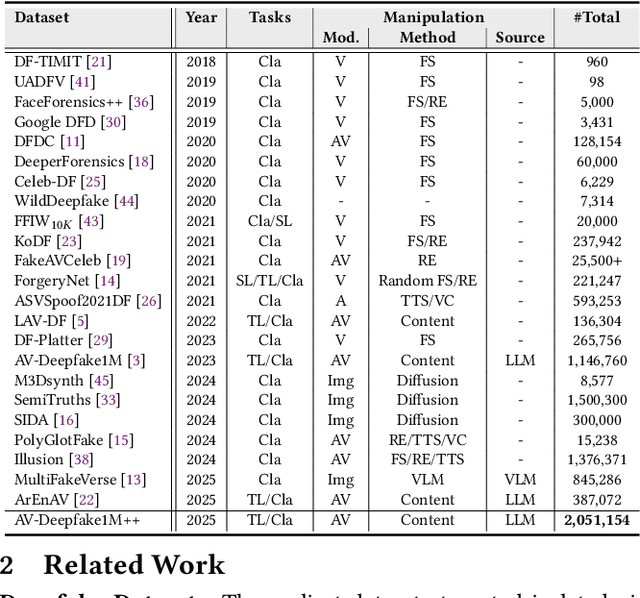
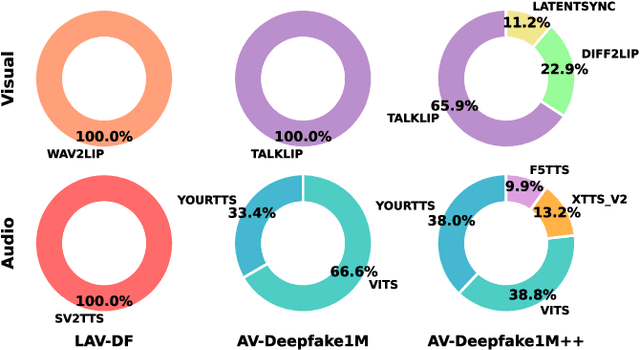
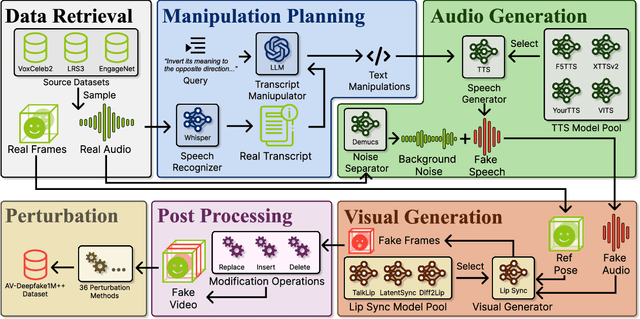
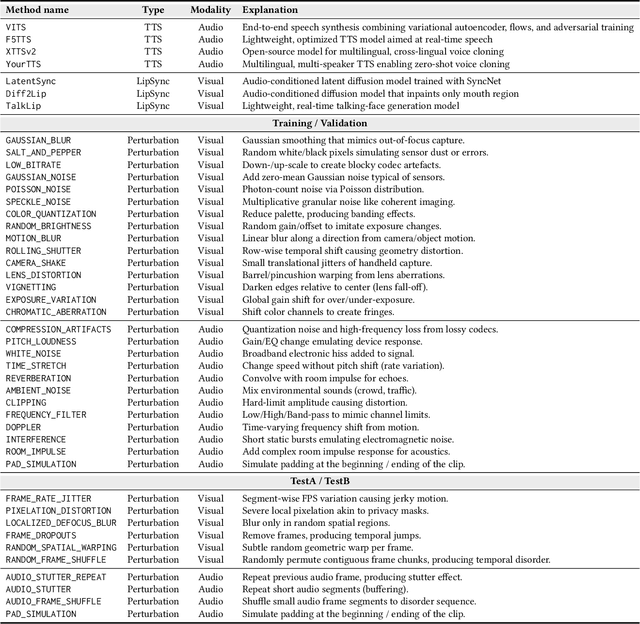
The rapid surge of text-to-speech and face-voice reenactment models makes video fabrication easier and highly realistic. To encounter this problem, we require datasets that rich in type of generation methods and perturbation strategy which is usually common for online videos. To this end, we propose AV-Deepfake1M++, an extension of the AV-Deepfake1M having 2 million video clips with diversified manipulation strategy and audio-visual perturbation. This paper includes the description of data generation strategies along with benchmarking of AV-Deepfake1M++ using state-of-the-art methods. We believe that this dataset will play a pivotal role in facilitating research in Deepfake domain. Based on this dataset, we host the 2025 1M-Deepfakes Detection Challenge. The challenge details, dataset and evaluation scripts are available online under a research-only license at https://deepfakes1m.github.io/2025.
TripCraft: A Benchmark for Spatio-Temporally Fine Grained Travel Planning
Feb 27, 2025



Recent advancements in probing Large Language Models (LLMs) have explored their latent potential as personalized travel planning agents, yet existing benchmarks remain limited in real world applicability. Existing datasets, such as TravelPlanner and TravelPlanner+, suffer from semi synthetic data reliance, spatial inconsistencies, and a lack of key travel constraints, making them inadequate for practical itinerary generation. To address these gaps, we introduce TripCraft, a spatiotemporally coherent travel planning dataset that integrates real world constraints, including public transit schedules, event availability, diverse attraction categories, and user personas for enhanced personalization. To evaluate LLM generated plans beyond existing binary validation methods, we propose five continuous evaluation metrics, namely Temporal Meal Score, Temporal Attraction Score, Spatial Score, Ordering Score, and Persona Score which assess itinerary quality across multiple dimensions. Our parameter informed setting significantly enhances meal scheduling, improving the Temporal Meal Score from 61% to 80% in a 7 day scenario. TripCraft establishes a new benchmark for LLM driven personalized travel planning, offering a more realistic, constraint aware framework for itinerary generation. Dataset and Codebase will be made publicly available upon acceptance.
A Racing Dataset and Baseline Model for Track Detection in Autonomous Racing
Feb 19, 2025A significant challenge in racing-related research is the lack of publicly available datasets containing raw images with corresponding annotations for the downstream task. In this paper, we introduce RoRaTrack, a novel dataset that contains annotated multi-camera image data from racing scenarios for track detection. The data is collected on a Dallara AV-21 at a racing circuit in Indiana, in collaboration with the Indy Autonomous Challenge (IAC). RoRaTrack addresses common problems such as blurriness due to high speed, color inversion from the camera, and absence of lane markings on the track. Consequently, we propose RaceGAN, a baseline model based on a Generative Adversarial Network (GAN) that effectively addresses these challenges. The proposed model demonstrates superior performance compared to current state-of-the-art machine learning models in track detection. The dataset and code for this work are available at github.com/RaceGAN.
Exploring Language Model Generalization in Low-Resource Extractive QA
Sep 27, 2024In this paper, we investigate Extractive Question Answering (EQA) with Large Language Models (LLMs) under domain drift, i.e., can LLMs generalize well to closed-domains that require specific knowledge such as medicine and law in a zero-shot fashion without additional in-domain training? To this end, we devise a series of experiments to empirically explain the performance gap. Our findings suggest that: a) LLMs struggle with dataset demands of closed-domains such as retrieving long answer-spans; b) Certain LLMs, despite showing strong overall performance, display weaknesses in meeting basic requirements as discriminating between domain-specific senses of words which we link to pre-processing decisions; c) Scaling model parameters is not always effective for cross-domain generalization; and d) Closed-domain datasets are quantitatively much different than open-domain EQA datasets and current LLMs struggle to deal with them. Our findings point out important directions for improving existing LLMs.