 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDexAvatar: 3D Sign Language Reconstruction with Hand and Body Pose Priors
Dec 24, 2025



The trend in sign language generation is centered around data-driven generative methods that require vast amounts of precise 2D and 3D human pose data to achieve an acceptable generation quality. However, currently, most sign language datasets are video-based and limited to automatically reconstructed 2D human poses (i.e., keypoints) and lack accurate 3D information. Furthermore, existing state-of-the-art for automatic 3D human pose estimation from sign language videos is prone to self-occlusion, noise, and motion blur effects, resulting in poor reconstruction quality. In response to this, we introduce DexAvatar, a novel framework to reconstruct bio-mechanically accurate fine-grained hand articulations and body movements from in-the-wild monocular sign language videos, guided by learned 3D hand and body priors. DexAvatar achieves strong performance in the SGNify motion capture dataset, the only benchmark available for this task, reaching an improvement of 35.11% in the estimation of body and hand poses compared to the state-of-the-art. The official website of this work is: https://github.com/kaustesseract/DexAvatar.
Do Blind Spots Matter for Word-Referent Mapping? A Computational Study with Infant Egocentric Video
Nov 13, 2025
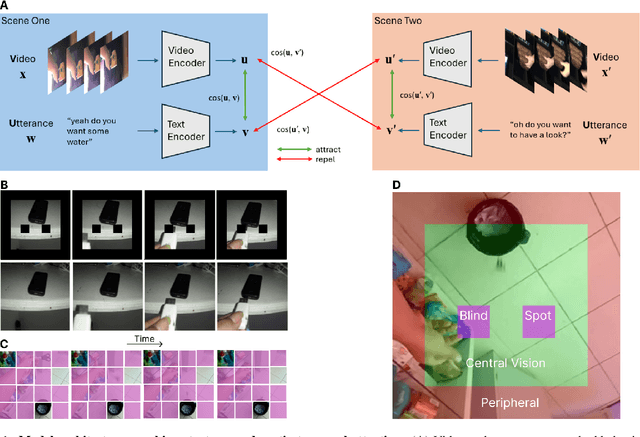


Typically, children start to learn their first words between 6 and 9 months, linking spoken utterances to their visual referents. Without prior knowledge, a word encountered for the first time can be interpreted in countless ways; it might refer to any of the objects in the environment, their components, or attributes. Using longitudinal, egocentric, and ecologically valid data from the experience of one child, in this work, we propose a self-supervised and biologically plausible strategy to learn strong visual representations. Our masked autoencoder-based visual backbone incorporates knowledge about the blind spot in human eyes to define a novel masking strategy. This mask and reconstruct approach attempts to mimic the way the human brain fills the gaps in the eyes' field of view. This represents a significant shift from standard random masking strategies, which are difficult to justify from a biological perspective. The pretrained encoder is utilized in a contrastive learning-based video-text model capable of acquiring word-referent mappings. Extensive evaluation suggests that the proposed biologically plausible masking strategy is at least as effective as random masking for learning word-referent mappings from cross-situational and temporally extended episodes.
1M-Deepfakes Detection Challenge
Sep 11, 2024



The detection and localization of deepfake content, particularly when small fake segments are seamlessly mixed with real videos, remains a significant challenge in the field of digital media security. Based on the recently released AV-Deepfake1M dataset, which contains more than 1 million manipulated videos across more than 2,000 subjects, we introduce the 1M-Deepfakes Detection Challenge. This challenge is designed to engage the research community in developing advanced methods for detecting and localizing deepfake manipulations within the large-scale high-realistic audio-visual dataset. The participants can access the AV-Deepfake1M dataset and are required to submit their inference results for evaluation across the metrics for detection or localization tasks. The methodologies developed through the challenge will contribute to the development of next-generation deepfake detection and localization systems. Evaluation scripts, baseline models, and accompanying code will be available on https://github.com/ControlNet/AV-Deepfake1M.
GTA-HDR: A Large-Scale Synthetic Dataset for HDR Image Reconstruction
Mar 26, 2024



High Dynamic Range (HDR) content (i.e., images and videos) has a broad range of applications. However, capturing HDR content from real-world scenes is expensive and time-consuming. Therefore, the challenging task of reconstructing visually accurate HDR images from their Low Dynamic Range (LDR) counterparts is gaining attention in the vision research community. A major challenge in this research problem is the lack of datasets, which capture diverse scene conditions (e.g., lighting, shadows, weather, locations, landscapes, objects, humans, buildings) and various image features (e.g., color, contrast, saturation, hue, luminance, brightness, radiance). To address this gap, in this paper, we introduce GTA-HDR, a large-scale synthetic dataset of photo-realistic HDR images sampled from the GTA-V video game. We perform thorough evaluation of the proposed dataset, which demonstrates significant qualitative and quantitative improvements of the state-of-the-art HDR image reconstruction methods. Furthermore, we demonstrate the effectiveness of the proposed dataset and its impact on additional computer vision tasks including 3D human pose estimation, human body part segmentation, and holistic scene segmentation. The dataset, data collection pipeline, and evaluation code are available at: https://github.com/HrishavBakulBarua/GTA-HDR.
Human Brain Exhibits Distinct Patterns When Listening to Fake Versus Real Audio: Preliminary Evidence
Feb 22, 2024



In this paper we study the variations in human brain activity when listening to real and fake audio. Our preliminary results suggest that the representations learned by a state-of-the-art deepfake audio detection algorithm, do not exhibit clear distinct patterns between real and fake audio. In contrast, human brain activity, as measured by EEG, displays distinct patterns when individuals are exposed to fake versus real audio. This preliminary evidence enables future research directions in areas such as deepfake audio detection.
HistoHDR-Net: Histogram Equalization for Single LDR to HDR Image Translation
Feb 08, 2024



High Dynamic Range (HDR) imaging aims to replicate the high visual quality and clarity of real-world scenes. Due to the high costs associated with HDR imaging, the literature offers various data-driven methods for HDR image reconstruction from Low Dynamic Range (LDR) counterparts. A common limitation of these approaches is missing details in regions of the reconstructed HDR images, which are over- or under-exposed in the input LDR images. To this end, we propose a simple and effective method, HistoHDR-Net, to recover the fine details (e.g., color, contrast, saturation, and brightness) of HDR images via a fusion-based approach utilizing histogram-equalized LDR images along with self-attention guidance. Our experiments demonstrate the efficacy of the proposed approach over the state-of-art methods.
AV-Deepfake1M: A Large-Scale LLM-Driven Audio-Visual Deepfake Dataset
Nov 26, 2023
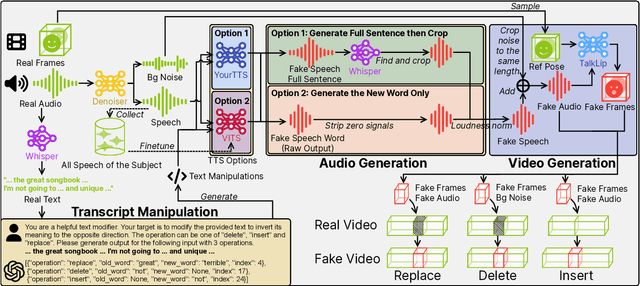


The detection and localization of highly realistic deepfake audio-visual content are challenging even for the most advanced state-of-the-art methods. While most of the research efforts in this domain are focused on detecting high-quality deepfake images and videos, only a few works address the problem of the localization of small segments of audio-visual manipulations embedded in real videos. In this research, we emulate the process of such content generation and propose the AV-Deepfake1M dataset. The dataset contains content-driven (i) video manipulations, (ii) audio manipulations, and (iii) audio-visual manipulations for more than 2K subjects resulting in a total of more than 1M videos. The paper provides a thorough description of the proposed data generation pipeline accompanied by a rigorous analysis of the quality of the generated data. The comprehensive benchmark of the proposed dataset utilizing state-of-the-art deepfake detection and localization methods indicates a significant drop in performance compared to previous datasets. The proposed dataset will play a vital role in building the next-generation deepfake localization methods. The dataset and associated code are available at https://github.com/ControlNet/AV-Deepfake1M .
ArtHDR-Net: Perceptually Realistic and Accurate HDR Content Creation
Sep 07, 2023



High Dynamic Range (HDR) content creation has become an important topic for modern media and entertainment sectors, gaming and Augmented/Virtual Reality industries. Many methods have been proposed to recreate the HDR counterparts of input Low Dynamic Range (LDR) images/videos given a single exposure or multi-exposure LDRs. The state-of-the-art methods focus primarily on the preservation of the reconstruction's structural similarity and the pixel-wise accuracy. However, these conventional approaches do not emphasize preserving the artistic intent of the images in terms of human visual perception, which is an essential element in media, entertainment and gaming. In this paper, we attempt to study and fill this gap. We propose an architecture called ArtHDR-Net based on a Convolutional Neural Network that uses multi-exposed LDR features as input. Experimental results show that ArtHDR-Net can achieve state-of-the-art performance in terms of the HDR-VDP-2 score (i.e., mean opinion score index) while reaching competitive performance in terms of PSNR and SSIM.
S-HR-VQVAE: Sequential Hierarchical Residual Learning Vector Quantized Variational Autoencoder for Video Prediction
Jul 13, 2023



We address the video prediction task by putting forth a novel model that combines (i) our recently proposed hierarchical residual vector quantized variational autoencoder (HR-VQVAE), and (ii) a novel spatiotemporal PixelCNN (ST-PixelCNN). We refer to this approach as a sequential hierarchical residual learning vector quantized variational autoencoder (S-HR-VQVAE). By leveraging the intrinsic capabilities of HR-VQVAE at modeling still images with a parsimonious representation, combined with the ST-PixelCNN's ability at handling spatiotemporal information, S-HR-VQVAE can better deal with chief challenges in video prediction. These include learning spatiotemporal information, handling high dimensional data, combating blurry prediction, and implicit modeling of physical characteristics. Extensive experimental results on the KTH Human Action and Moving-MNIST tasks demonstrate that our model compares favorably against top video prediction techniques both in quantitative and qualitative evaluations despite a much smaller model size. Finally, we boost S-HR-VQVAE by proposing a novel training method to jointly estimate the HR-VQVAE and ST-PixelCNN parameters.
"Glitch in the Matrix!": A Large Scale Benchmark for Content Driven Audio-Visual Forgery Detection and Localization
May 05, 2023



Most deepfake detection methods focus on detecting spatial and/or spatio-temporal changes in facial attributes. This is because available benchmark datasets contain mostly visual-only modifications. However, a sophisticated deepfake may include small segments of audio or audio-visual manipulations that can completely change the meaning of the content. To addresses this gap, we propose and benchmark a new dataset, Localized Audio Visual DeepFake (LAV-DF), consisting of strategic content-driven audio, visual and audio-visual manipulations. The proposed baseline method, Boundary Aware Temporal Forgery Detection (BA-TFD), is a 3D Convolutional Neural Network-based architecture which efficiently captures multimodal manipulations. We further improve (i.e. BA-TFD+) the baseline method by replacing the backbone with a Multiscale Vision Transformer and guide the training process with contrastive, frame classification, boundary matching and multimodal boundary matching loss functions. The quantitative analysis demonstrates the superiority of BA- TFD+ on temporal forgery localization and deepfake detection tasks using several benchmark datasets including our newly proposed dataset. The dataset, models and code are available at https://github.com/ControlNet/LAV-DF.