 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNon-native Children's Automatic Speech Assessment Challenge (NOCASA)
Apr 29, 2025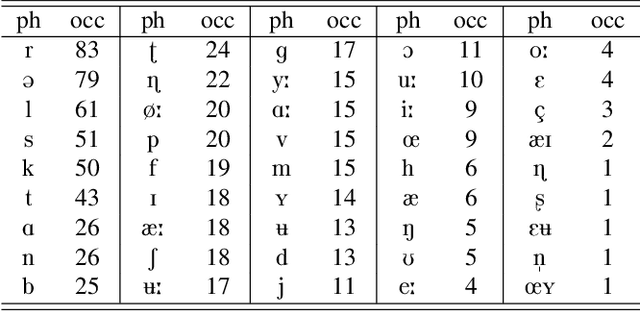
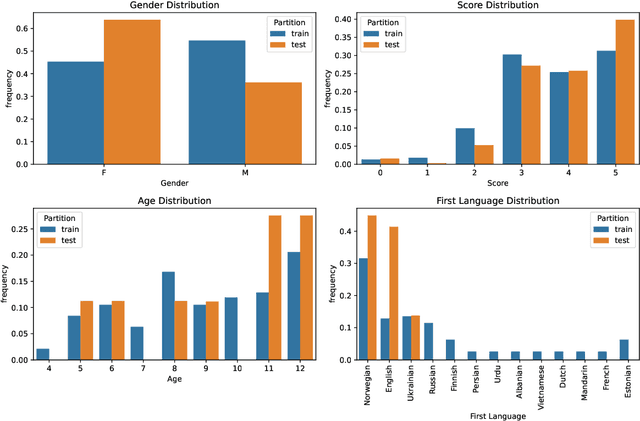

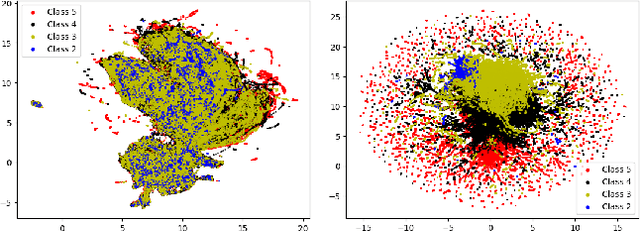
This paper presents the "Non-native Children's Automatic Speech Assessment" (NOCASA) - a data competition part of the IEEE MLSP 2025 conference. NOCASA challenges participants to develop new systems that can assess single-word pronunciations of young second language (L2) learners as part of a gamified pronunciation training app. To achieve this, several issues must be addressed, most notably the limited nature of available training data and the highly unbalanced distribution among the pronunciation level categories. To expedite the development, we provide a pseudo-anonymized training data (TeflonNorL2), containing 10,334 recordings from 44 speakers attempting to pronounce 205 distinct Norwegian words, human-rated on a 1 to 5 scale (number of stars that should be given in the game). In addition to the data, two already trained systems are released as official baselines: an SVM classifier trained on the ComParE_16 acoustic feature set and a multi-task wav2vec 2.0 model. The latter achieves the best performance on the challenge test set, with an unweighted average recall (UAR) of 36.37%.
Exploiting Foundation Models and Speech Enhancement for Parkinson's Disease Detection from Speech in Real-World Operative Conditions
Jun 23, 2024



This work is concerned with devising a robust Parkinson's (PD) disease detector from speech in real-world operating conditions using (i) foundational models, and (ii) speech enhancement (SE) methods. To this end, we first fine-tune several foundational-based models on the standard PC-GITA (s-PC-GITA) clean data. Our results demonstrate superior performance to previously proposed models. Second, we assess the generalization capability of the PD models on the extended PC-GITA (e-PC-GITA) recordings, collected in real-world operative conditions, and observe a severe drop in performance moving from ideal to real-world conditions. Third, we align training and testing conditions applaying off-the-shelf SE techniques on e-PC-GITA, and a significant boost in performance is observed only for the foundational-based models. Finally, combining the two best foundational-based models trained on s-PC-GITA, namely WavLM Base and Hubert Base, yielded top performance on the enhanced e-PC-GITA.
Developing Acoustic Models for Automatic Speech Recognition in Swedish
Apr 25, 2024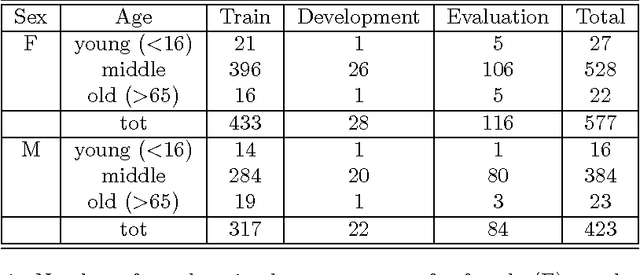
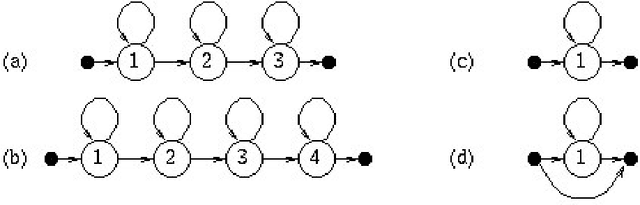
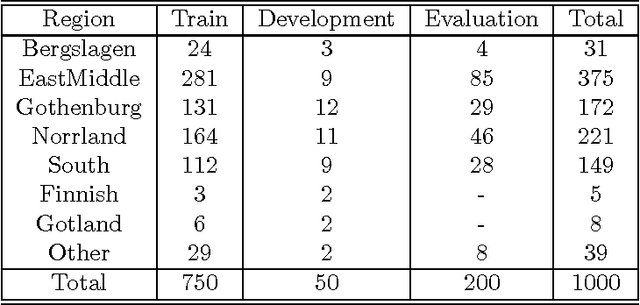
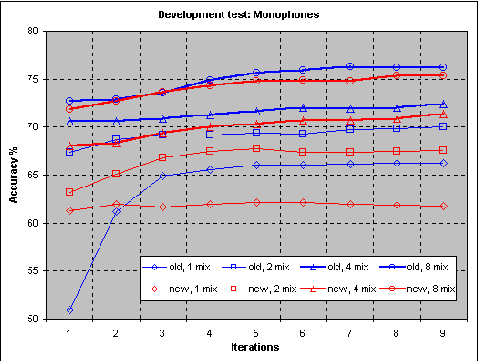
This paper is concerned with automatic continuous speech recognition using trainable systems. The aim of this work is to build acoustic models for spoken Swedish. This is done employing hidden Markov models and using the SpeechDat database to train their parameters. Acoustic modeling has been worked out at a phonetic level, allowing general speech recognition applications, even though a simplified task (digits and natural number recognition) has been considered for model evaluation. Different kinds of phone models have been tested, including context independent models and two variations of context dependent models. Furthermore many experiments have been done with bigram language models to tune some of the system parameters. System performance over various speaker subsets with different sex, age and dialect has also been examined. Results are compared to previous similar studies showing a remarkable improvement.
* 16 pages, 7 figures
Dynamic Behaviour of Connectionist Speech Recognition with Strong Latency Constraints
Jan 12, 2024

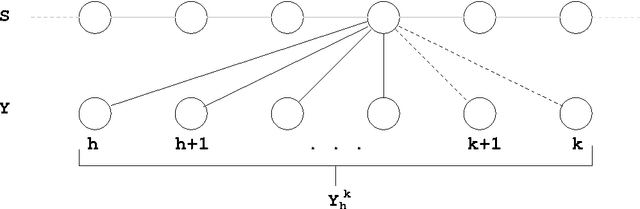

This paper describes the use of connectionist techniques in phonetic speech recognition with strong latency constraints. The constraints are imposed by the task of deriving the lip movements of a synthetic face in real time from the speech signal, by feeding the phonetic string into an articulatory synthesiser. Particular attention has been paid to analysing the interaction between the time evolution model learnt by the multi-layer perceptrons and the transition model imposed by the Viterbi decoder, in different latency conditions. Two experiments were conducted in which the time dependencies in the language model (LM) were controlled by a parameter. The results show a strong interaction between the three factors involved, namely the neural network topology, the length of time dependencies in the LM and the decoder latency.
Segment Boundary Detection via Class Entropy Measurements in Connectionist Phoneme Recognition
Jan 12, 2024This article investigates the possibility to use the class entropy of the output of a connectionist phoneme recogniser to predict time boundaries between phonetic classes. The rationale is that the value of the entropy should increase in proximity of a transition between two segments that are well modelled (known) by the recognition network since it is a measure of uncertainty. The advantage of this measure is its simplicity as the posterior probabilities of each class are available in connectionist phoneme recognition. The entropy and a number of measures based on differentiation of the entropy are used in isolation and in combination. The decision methods for predicting the boundaries range from simple thresholds to neural network based procedure. The different methods are compared with respect to their precision, measured in terms of the ratio between the number C of predicted boundaries within 10 or 20 msec of the reference and the total number of predicted boundaries, and recall, measured as the ratio between C and the total number of reference boundaries.
S-HR-VQVAE: Sequential Hierarchical Residual Learning Vector Quantized Variational Autoencoder for Video Prediction
Jul 13, 2023



We address the video prediction task by putting forth a novel model that combines (i) our recently proposed hierarchical residual vector quantized variational autoencoder (HR-VQVAE), and (ii) a novel spatiotemporal PixelCNN (ST-PixelCNN). We refer to this approach as a sequential hierarchical residual learning vector quantized variational autoencoder (S-HR-VQVAE). By leveraging the intrinsic capabilities of HR-VQVAE at modeling still images with a parsimonious representation, combined with the ST-PixelCNN's ability at handling spatiotemporal information, S-HR-VQVAE can better deal with chief challenges in video prediction. These include learning spatiotemporal information, handling high dimensional data, combating blurry prediction, and implicit modeling of physical characteristics. Extensive experimental results on the KTH Human Action and Moving-MNIST tasks demonstrate that our model compares favorably against top video prediction techniques both in quantitative and qualitative evaluations despite a much smaller model size. Finally, we boost S-HR-VQVAE by proposing a novel training method to jointly estimate the HR-VQVAE and ST-PixelCNN parameters.
Hierarchical Residual Learning Based Vector Quantized Variational Autoencoder for Image Reconstruction and Generation
Aug 09, 2022

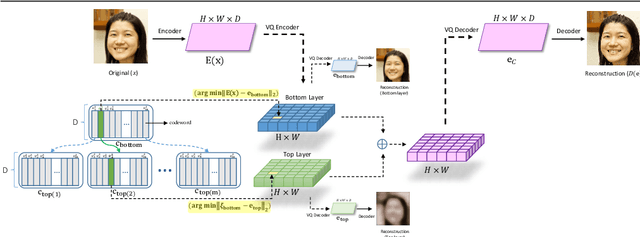
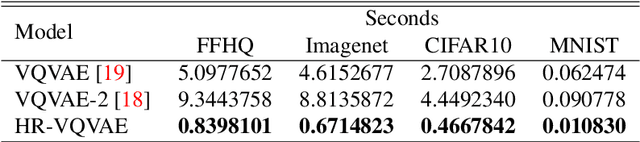
We propose a multi-layer variational autoencoder method, we call HR-VQVAE, that learns hierarchical discrete representations of the data. By utilizing a novel objective function, each layer in HR-VQVAE learns a discrete representation of the residual from previous layers through a vector quantized encoder. Furthermore, the representations at each layer are hierarchically linked to those at previous layers. We evaluate our method on the tasks of image reconstruction and generation. Experimental results demonstrate that the discrete representations learned by HR-VQVAE enable the decoder to reconstruct high-quality images with less distortion than the baseline methods, namely VQVAE and VQVAE-2. HR-VQVAE can also generate high-quality and diverse images that outperform state-of-the-art generative models, providing further verification of the efficiency of the learned representations. The hierarchical nature of HR-VQVAE i) reduces the decoding search time, making the method particularly suitable for high-load tasks and ii) allows to increase the codebook size without incurring the codebook collapse problem.
NAAQA: A Neural Architecture for Acoustic Question Answering
Jun 11, 2021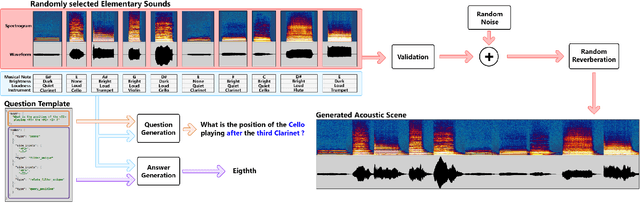

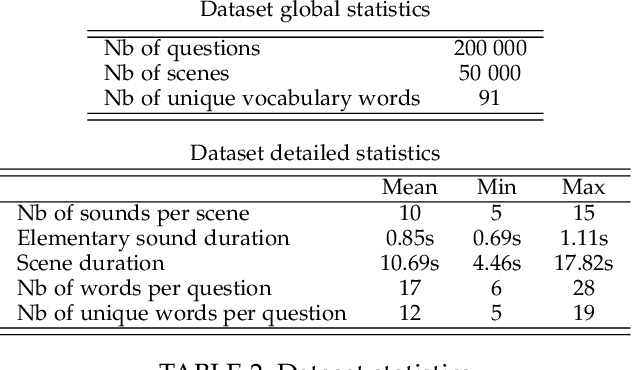
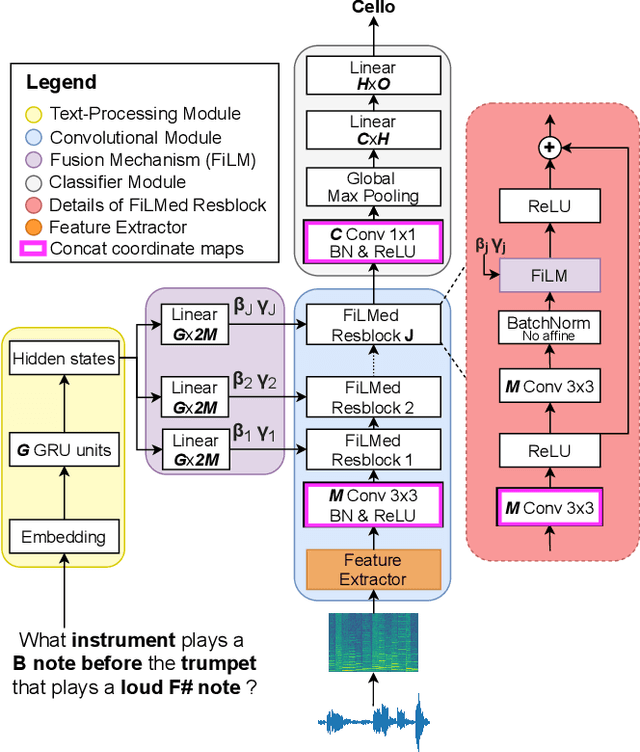
The goal of the Acoustic Question Answering (AQA) task is to answer a free-form text question about the content of an acoustic scene. It was inspired by the Visual Question Answering (VQA) task. In this paper, based on the previously introduced CLEAR dataset, we propose a new benchmark for AQA that emphasizes the specific challenges of acoustic inputs, e.g. variable duration scenes. We also introduce NAAQA, a neural architecture that leverages specific properties of acoustic inputs. The usage of time and frequency 1D convolutions to process 2D spectro-temporal representations of acoustic content shows promising results and enables reductions in model complexity. NAAQA achieves 91.6% of accuracy on the AQA task with about 7 times fewer parameters than the previously explored VQA model. We provide a detailed analysis of the results for the different question types. The effectiveness of coordinate maps in this acoustic context was also studied and we show that time coordinate maps augment temporal localization capabilities which enhance performance of the network by about 17 percentage points.
From Visual to Acoustic Question Answering
Feb 28, 2019

We introduce the new task of Acoustic Question Answering (AQA) to promote research in acoustic reasoning. The AQA task consists of analyzing an acoustic scene composed by a combination of elementary sounds and answering questions that relate the position and properties of these sounds. The kind of relational questions asked, require that the models perform non-trivial reasoning in order to answer correctly. Although similar problems have been extensively studied in the domain of visual reasoning, we are not aware of any previous studies addressing the problem in the acoustic domain. We propose a method for generating the acoustic scenes from elementary sounds and a number of relevant questions for each scene using templates. We also present preliminary results obtained with two models (FiLM and MAC) that have been shown to work for visual reasoning.
Beyond the Self: Using Grounded Affordances to Interpret and Describe Others' Actions
Feb 26, 2019
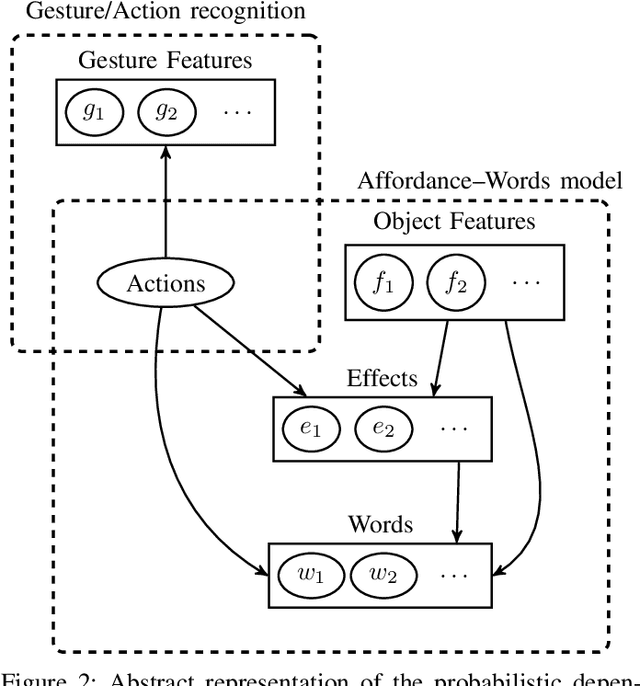
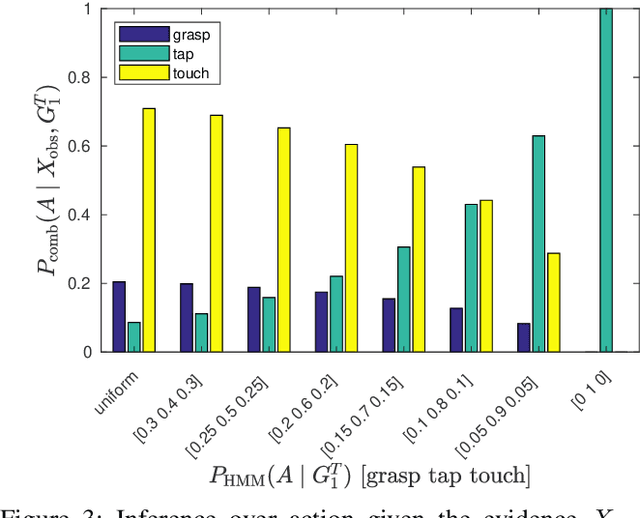
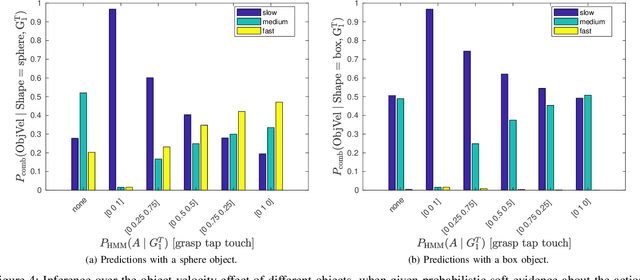
We propose a developmental approach that allows a robot to interpret and describe the actions of human agents by reusing previous experience. The robot first learns the association between words and object affordances by manipulating the objects in its environment. It then uses this information to learn a mapping between its own actions and those performed by a human in a shared environment. It finally fuses the information from these two models to interpret and describe human actions in light of its own experience. In our experiments, we show that the model can be used flexibly to do inference on different aspects of the scene. We can predict the effects of an action on the basis of object properties. We can revise the belief that a certain action occurred, given the observed effects of the human action. In an early action recognition fashion, we can anticipate the effects when the action has only been partially observed. By estimating the probability of words given the evidence and feeding them into a pre-defined grammar, we can generate relevant descriptions of the scene. We believe that this is a step towards providing robots with the fundamental skills to engage in social collaboration with humans.