 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Central Frequencies Locally Competitive Algorithm for Speech
Feb 10, 2025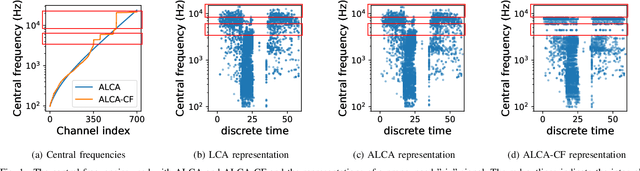
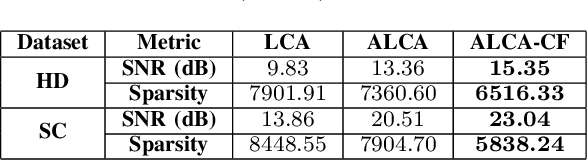
Neuromorphic computing, inspired by nervous systems, revolutionizes information processing with its focus on efficiency and low power consumption. Using sparse coding, this paradigm enhances processing efficiency, which is crucial for edge devices with power constraints. The Locally Competitive Algorithm (LCA), adapted for audio with Gammatone and Gammachirp filter banks, provides an efficient sparse coding method for neuromorphic speech processing. Adaptive LCA (ALCA) further refines this method by dynamically adjusting modulation parameters, thereby improving reconstruction quality and sparsity. This paper introduces an enhanced ALCA version, the ALCA Central Frequency (ALCA-CF), which dynamically adapts both modulation parameters and central frequencies, optimizing the speech representation. Evaluations show that this approach improves reconstruction quality and sparsity while significantly reducing the power consumption of speech classification, without compromising classification accuracy, particularly on Intel's Loihi 2 neuromorphic chip.
Maximizing Information in Neuron Populations for Neuromorphic Spike Encoding
Dec 11, 2024



Neuromorphic applications emulate the processing performed by the brain by using spikes as inputs instead of time-varying analog stimuli. Therefore, these time-varying stimuli have to be encoded into spikes, which can induce important information loss. To alleviate this loss, some studies use population coding strategies to encode more information using a population of neurons rather than just one neuron. However, configuring the encoding parameters of such a population is an open research question. This work proposes an approach based on maximizing the mutual information between the signal and the spikes in the population of neurons. The proposed algorithm is inspired by the information-theoretic framework of Partial Information Decomposition. Two applications are presented: blood pressure pulse wave classification, and neural action potential waveform classification. In both tasks, the data is encoded into spikes and the encoding parameters of the neuron populations are tuned to maximize the encoded information using the proposed algorithm. The spikes are then classified and the performance is measured using classification accuracy as a metric. Two key results are reported. Firstly, adding neurons to the population leads to an increase in both mutual information and classification accuracy beyond what could be accounted for by each neuron separately, showing the usefulness of population coding strategies. Secondly, the classification accuracy obtained with the tuned parameters is near-optimal and it closely follows the mutual information as more neurons are added to the population. Furthermore, the proposed approach significantly outperforms random parameter selection, showing the usefulness of the proposed approach. These results are reproduced in both applications.
Efficient Sparse Coding with the Adaptive Locally Competitive Algorithm for Speech Classification
Sep 12, 2024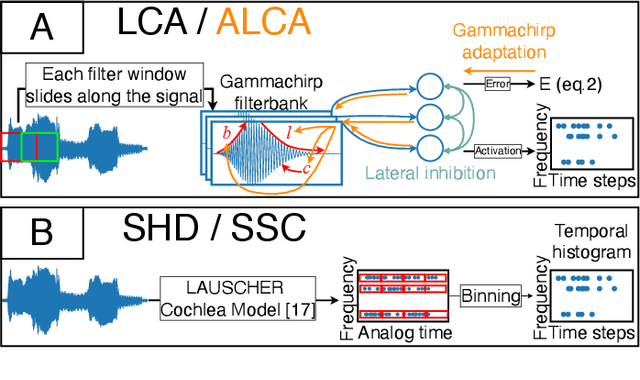
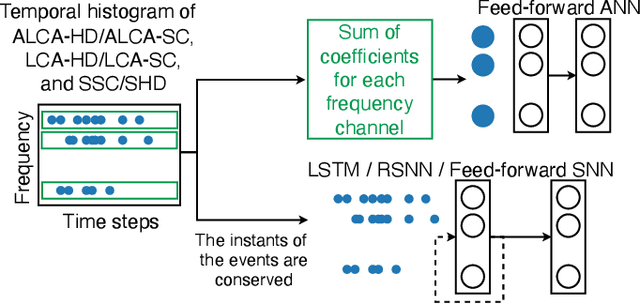
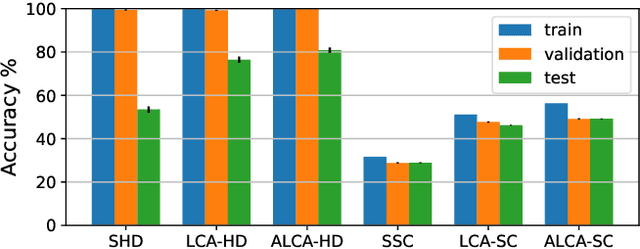
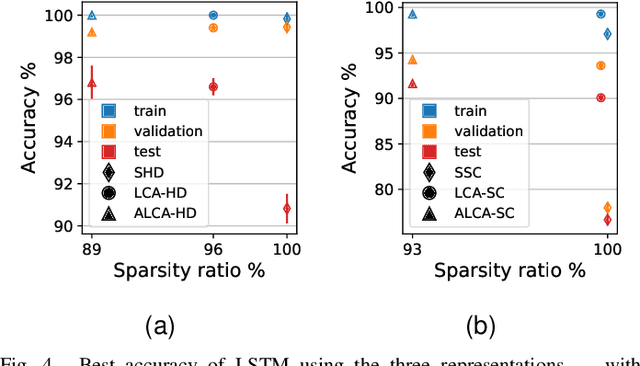
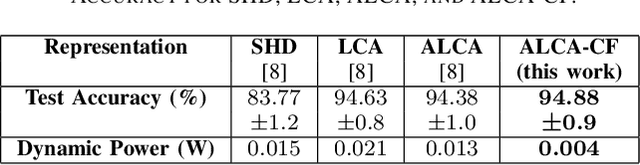
Researchers are exploring novel computational paradigms such as sparse coding and neuromorphic computing to bridge the efficiency gap between the human brain and conventional computers in complex tasks. A key area of focus is neuromorphic audio processing. While the Locally Competitive Algorithm has emerged as a promising solution for sparse coding, offering potential for real-time and low-power processing on neuromorphic hardware, its applications in neuromorphic speech classification have not been thoroughly studied. The Adaptive Locally Competitive Algorithm builds upon the Locally Competitive Algorithm by dynamically adjusting the modulation parameters of the filter bank to fine-tune the filters' sensitivity. This adaptability enhances lateral inhibition, improving reconstruction quality, sparsity, and convergence time, which is crucial for real-time applications. This paper demonstrates the potential of the Locally Competitive Algorithm and its adaptive variant as robust feature extractors for neuromorphic speech classification. Results show that the Locally Competitive Algorithm achieves better speech classification accuracy at the expense of higher power consumption compared to the LAUSCHER cochlea model used for benchmarking. On the other hand, the Adaptive Locally Competitive Algorithm mitigates this power consumption issue without compromising the accuracy. The dynamic power consumption is reduced to a range of 0.004 to 13 milliwatts on neuromorphic hardware, three orders of magnitude less than setups using Graphics Processing Units. These findings position the Adaptive Locally Competitive Algorithm as a compelling solution for efficient speech classification systems, promising substantial advancements in balancing speech classification accuracy and power efficiency.
Expanding memory in recurrent spiking networks
Oct 29, 2023Recurrent spiking neural networks (RSNNs) are notoriously difficult to train because of the vanishing gradient problem that is enhanced by the binary nature of the spikes. In this paper, we review the ability of the current state-of-the-art RSNNs to solve long-term memory tasks, and show that they have strong constraints both in performance, and for their implementation on hardware analog neuromorphic processors. We present a novel spiking neural network that circumvents these limitations. Our biologically inspired neural network uses synaptic delays, branching factor regularization and a novel surrogate derivative for the spiking function. The proposed network proves to be more successful in using the recurrent connections on memory tasks.
Stabilizing RNN Gradients through Pre-training
Aug 23, 2023


Numerous theories of learning suggest to prevent the gradient variance from exponential growth with depth or time, to stabilize and improve training. Typically, these analyses are conducted on feed-forward fully-connected neural networks or single-layer recurrent neural networks, given their mathematical tractability. In contrast, this study demonstrates that pre-training the network to local stability can be effective whenever the architectures are too complex for an analytical initialization. Furthermore, we extend known stability theories to encompass a broader family of deep recurrent networks, requiring minimal assumptions on data and parameter distribution, a theory that we refer to as the Local Stability Condition (LSC). Our investigation reveals that the classical Glorot, He, and Orthogonal initialization schemes satisfy the LSC when applied to feed-forward fully-connected neural networks. However, analysing deep recurrent networks, we identify a new additive source of exponential explosion that emerges from counting gradient paths in a rectangular grid in depth and time. We propose a new approach to mitigate this issue, that consists on giving a weight of a half to the time and depth contributions to the gradient, instead of the classical weight of one. Our empirical results confirm that pre-training both feed-forward and recurrent networks to fulfill the LSC often results in improved final performance across models. This study contributes to the field by providing a means to stabilize networks of any complexity. Our approach can be implemented as an additional step before pre-training on large augmented datasets, and as an alternative to finding stable initializations analytically.
Excitatory/Inhibitory Balance Emerges as a Key Factor for RBN Performance, Overriding Attractor Dynamics
Aug 02, 2023Reservoir computing provides a time and cost-efficient alternative to traditional learning methods.Critical regimes, known as the "edge of chaos," have been found to optimize computational performance in binary neural networks. However, little attention has been devoted to studying reservoir-to-reservoir variability when investigating the link between connectivity, dynamics, and performance. As physical reservoir computers become more prevalent, developing a systematic approach to network design is crucial. In this article, we examine Random Boolean Networks (RBNs) and demonstrate that specific distribution parameters can lead to diverse dynamics near critical points. We identify distinct dynamical attractors and quantify their statistics, revealing that most reservoirs possess a dominant attractor. We then evaluate performance in two challenging tasks, memorization and prediction, and find that a positive excitatory balance produces a critical point with higher memory performance. In comparison, a negative inhibitory balance delivers another critical point with better prediction performance. Interestingly, we show that the intrinsic attractor dynamics have little influence on performance in either case.
* 22 pages, 6 figures
Efficient spike encoding algorithms for neuromorphic speech recognition
Jul 14, 2022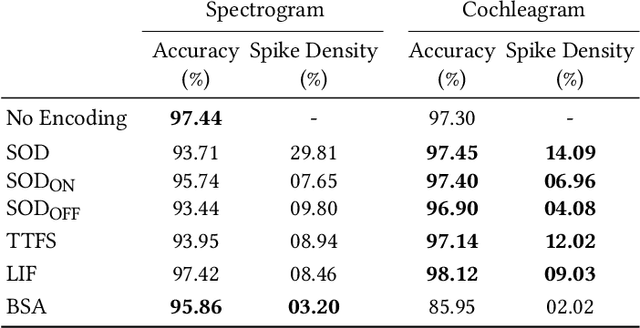
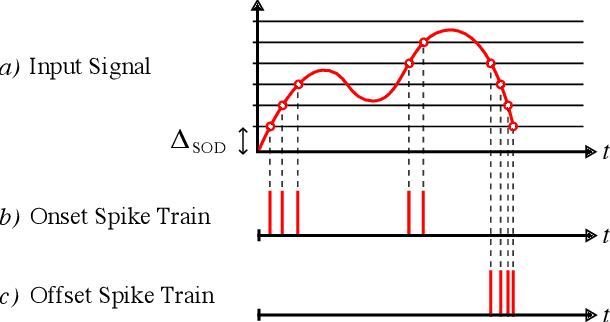

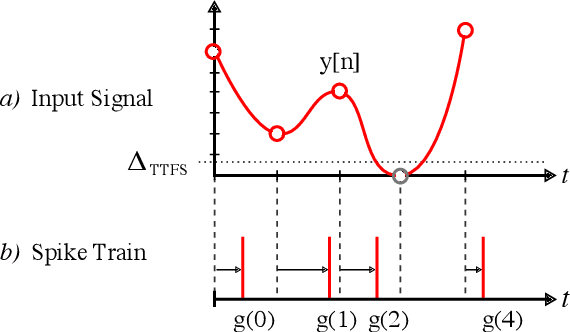
Spiking Neural Networks (SNN) are known to be very effective for neuromorphic processor implementations, achieving orders of magnitude improvements in energy efficiency and computational latency over traditional deep learning approaches. Comparable algorithmic performance was recently made possible as well with the adaptation of supervised training algorithms to the context of SNN. However, information including audio, video, and other sensor-derived data are typically encoded as real-valued signals that are not well-suited to SNN, preventing the network from leveraging spike timing information. Efficient encoding from real-valued signals to spikes is therefore critical and significantly impacts the performance of the overall system. To efficiently encode signals into spikes, both the preservation of information relevant to the task at hand as well as the density of the encoded spikes must be considered. In this paper, we study four spike encoding methods in the context of a speaker independent digit classification system: Send on Delta, Time to First Spike, Leaky Integrate and Fire Neuron and Bens Spiker Algorithm. We first show that all encoding methods yield higher classification accuracy using significantly fewer spikes when encoding a bio-inspired cochleagram as opposed to a traditional short-time Fourier transform. We then show that two Send On Delta variants result in classification results comparable with a state of the art deep convolutional neural network baseline, while simultaneously reducing the encoded bit rate. Finally, we show that several encoding methods result in improved performance over the conventional deep learning baseline in certain cases, further demonstrating the power of spike encoding algorithms in the encoding of real-valued signals and that neuromorphic implementation has the potential to outperform state of the art techniques.
Voltage-Dependent Synaptic Plasticity (VDSP): Unsupervised probabilistic Hebbian plasticity rule based on neurons membrane potential
Apr 14, 2022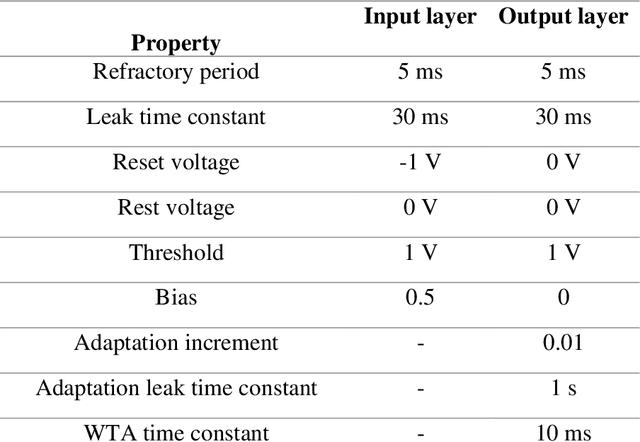
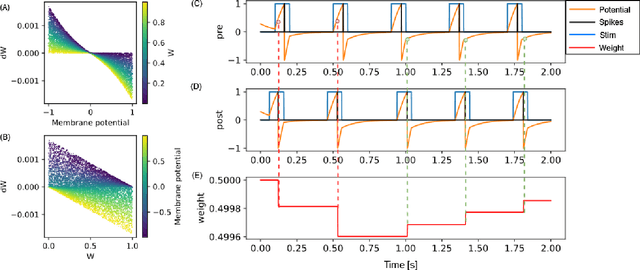
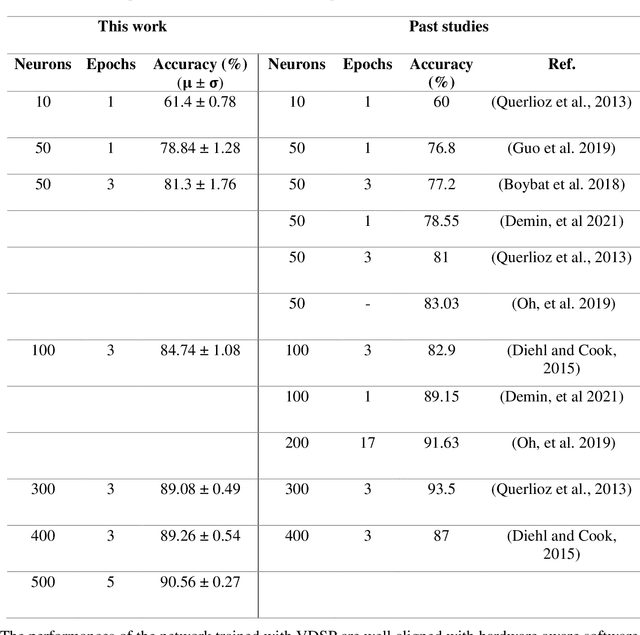
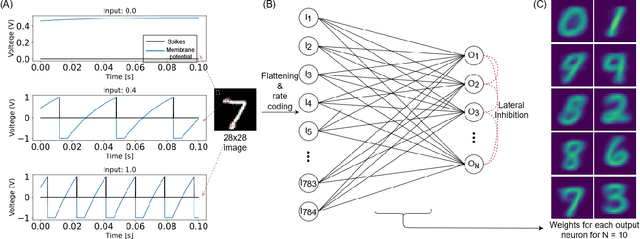
This study proposes voltage-dependent-synaptic plasticity (VDSP), a novel brain-inspired unsupervised local learning rule for the online implementation of Hebb's plasticity mechanism on neuromorphic hardware. The proposed VDSP learning rule updates the synaptic conductance on the spike of the postsynaptic neuron only, which reduces by a factor of two the number of updates with respect to standard spike-timing-dependent plasticity (STDP). This update is dependent on the membrane potential of the presynaptic neuron, which is readily available as part of neuron implementation and hence does not require additional memory for storage. Moreover, the update is also regularized on synaptic weight and prevents explosion or vanishing of weights on repeated stimulation. Rigorous mathematical analysis is performed to draw an equivalence between VDSP and STDP. To validate the system-level performance of VDSP, we train a single-layer spiking neural network (SNN) for the recognition of handwritten digits. We report 85.01 $ \pm $ 0.76% (Mean $ \pm $ S.D.) accuracy for a network of 100 output neurons on the MNIST dataset. The performance improves when scaling the network size (89.93 $ \pm $ 0.41% for 400 output neurons, 90.56 $ \pm $ 0.27 for 500 neurons), which validates the applicability of the proposed learning rule for large-scale computer vision tasks. Interestingly, the learning rule better adapts than STDP to the frequency of input signal and does not require hand-tuning of hyperparameters.
Perceptive, non-linear Speech Processing and Spiking Neural Networks
Mar 31, 2022Source separation and speech recognition are very difficult in the context of noisy and corrupted speech. Most conventional techniques need huge databases to estimate speech (or noise) density probabilities to perform separation or recognition. We discuss the potential of perceptive speech analysis and processing in combination with biologically plausible neural network processors. We illustrate the potential of such non-linear processing of speech on a source separation system inspired by an Auditory Scene Analysis paradigm. We also discuss a potential application in speech recognition.
Evaluation of Neuromorphic Spike Encoding of Sound Using Information Theory
Feb 19, 2022
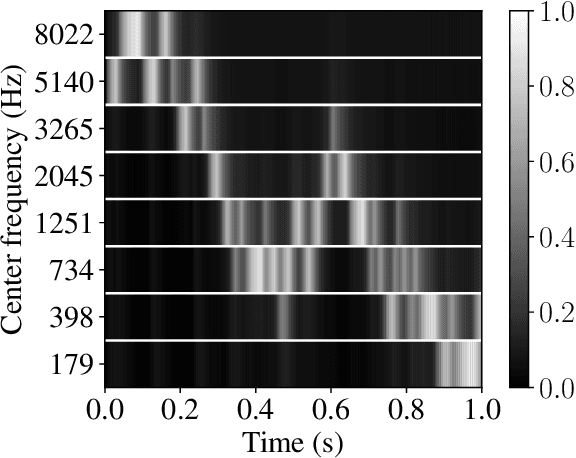
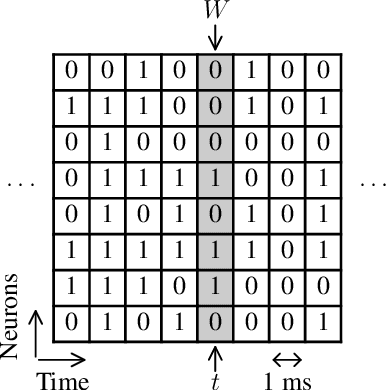
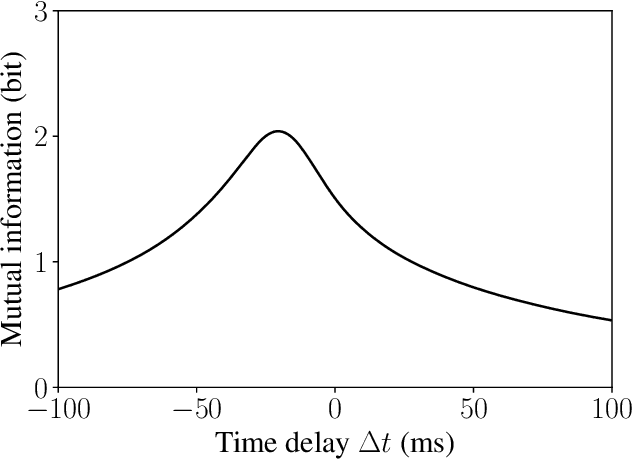
The problem of spike encoding of sound consists in transforming a sound waveform into spikes. It is of interest in many domains, including the development of audio-based spiking neural networks, where it is the first and most crucial stage of processing. Many algorithms have been proposed to perform spike encoding of sound. However, a systematic approach to quantitatively evaluate their performance is currently lacking. We propose the use of an information-theoretic framework to solve this problem. Specifically, we evaluate the coding efficiency of four spike encoding algorithms on two coding tasks that consist of coding the fundamental characteristics of sound: frequency and amplitude. The algorithms investigated are: Independent Spike Coding, Send-on-Delta coding, Ben's Spiker Algorithm, and Leaky Integrate-and-Fire coding. Using the tools of information theory, we estimate the information that the spikes carry on relevant aspects of an input stimulus. We find disparities in the coding efficiencies of the algorithms, where Leaky Integrate-and-Fire coding performs best. The information-theoretic analysis of their performance on these coding tasks provides insight on the encoding of richer and more complex sound stimuli.