 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Subjectivity of Monoculture
Feb 27, 2026Machine learning models -- including large language models (LLMs) -- are often said to exhibit monoculture, where outputs agree strikingly often. But what does it actually mean for models to agree too much? We argue that this question is inherently subjective, relying on two key decisions. First, the analyst must specify a baseline null model for what "independence" should look like. This choice is inherently subjective, and as we show, different null models result in dramatically different inferences about excess agreement. Second, we show that inferences depend on the population of models and items under consideration. Models that seem highly correlated in one context may appear independent when evaluated on a different set of questions, or against a different set of peers. Experiments on two large-scale benchmarks validate our theoretical findings. For example, we find drastically different inferences when using a null model with item difficulty compared to previous works that do not. Together, our results reframe monoculture evaluation not as an absolute property of model behavior, but as a context-dependent inference problem.
How Many Features Can a Language Model Store Under the Linear Representation Hypothesis?
Feb 11, 2026We introduce a mathematical framework for the linear representation hypothesis (LRH), which asserts that intermediate layers of language models store features linearly. We separate the hypothesis into two claims: linear representation (features are linearly embedded in neuron activations) and linear accessibility (features can be linearly decoded). We then ask: How many neurons $d$ suffice to both linearly represent and linearly access $m$ features? Classical results in compressed sensing imply that for $k$-sparse inputs, $d = O(k\log (m/k))$ suffices if we allow non-linear decoding algorithms (Candes and Tao, 2006; Candes et al., 2006; Donoho, 2006). However, the additional requirement of linear decoding takes the problem out of the classical compressed sensing, into linear compressed sensing. Our main theoretical result establishes nearly-matching upper and lower bounds for linear compressed sensing. We prove that $d = Ω_ε(\frac{k^2}{\log k}\log (m/k))$ is required while $d = O_ε(k^2\log m)$ suffices. The lower bound establishes a quantitative gap between classical and linear compressed setting, illustrating how linear accessibility is a meaningfully stronger hypothesis than linear representation alone. The upper bound confirms that neurons can store an exponential number of features under the LRH, giving theoretical evidence for the "superposition hypothesis" (Elhage et al., 2022). The upper bound proof uses standard random constructions of matrices with approximately orthogonal columns. The lower bound proof uses rank bounds for near-identity matrices (Alon, 2003) together with Turán's theorem (bounding the number of edges in clique-free graphs). We also show how our results do and do not constrain the geometry of feature representations and extend our results to allow decoders with an activation function and bias.
Paper Skygest: Personalized Academic Recommendations on Bluesky
Jan 06, 2026We build, deploy, and evaluate Paper Skygest, a custom personalized social feed for scientific content posted by a user's network on Bluesky and the AT Protocol. We leverage a new capability on emerging decentralized social media platforms: the ability for anyone to build and deploy feeds for other users, to use just as they would a native platform-built feed. To our knowledge, Paper Skygest is the first and largest such continuously deployed personalized social media feed by academics, with over 50,000 weekly uses by over 1,000 daily active users, all organically acquired. First, we quantitatively and qualitatively evaluate Paper Skygest usage, showing that it has sustained usage and satisfies users; we further show adoption of Paper Skygest increases a user's interactions with posts about research, and how interaction rates change as a function of post order. Second, we share our full code and describe our system architecture, to support other academics in building and deploying such feeds sustainably. Third, we overview the potential of custom feeds such as Paper Skygest for studying algorithm designs, building for user agency, and running recommender system experiments with organic users without partnering with a centralized platform.
Personalized Spiking Neural Networks with Ferroelectric Synapses for EEG Signal Processing
Jan 05, 2026Electroencephalography (EEG)-based brain-computer interfaces (BCIs) are strongly affected by non-stationary neural signals that vary across sessions and individuals, limiting the generalization of subject-agnostic models and motivating adaptive and personalized learning on resource-constrained platforms. Programmable memristive hardware offers a promising substrate for such post-deployment adaptation; however, practical realization is challenged by limited weight resolution, device variability, nonlinear programming dynamics, and finite device endurance. In this work, we show that spiking neural networks (SNNs) can be deployed on ferroelectric memristive synaptic devices for adaptive EEG-based motor imagery decoding under realistic device constraints. We fabricate, characterize, and model ferroelectric synapses. We evaluate a convolutional-recurrent SNN architecture under two complementary deployment strategies: (i) device-aware training using a ferroelectric synapse model, and (ii) transfer of software-trained weights followed by low-overhead on-device re-tuning. To enable efficient adaptation, we introduce a device-aware weight-update strategy in which gradient-based updates are accumulated digitally and converted into discrete programming events only when a threshold is exceeded, emulating nonlinear, state-dependent programming dynamics while reducing programming frequency. Both deployment strategies achieve classification performance comparable to state-of-the-art software-based SNNs. Furthermore, subject-specific transfer learning achieved by retraining only the final network layers improves classification accuracy. These results demonstrate that programmable ferroelectric hardware can support robust, low-overhead adaptation in spiking neural networks, opening a practical path toward personalized neuromorphic processing of neural signals.
Urban Incident Prediction with Graph Neural Networks: Integrating Government Ratings and Crowdsourced Reports
Jun 10, 2025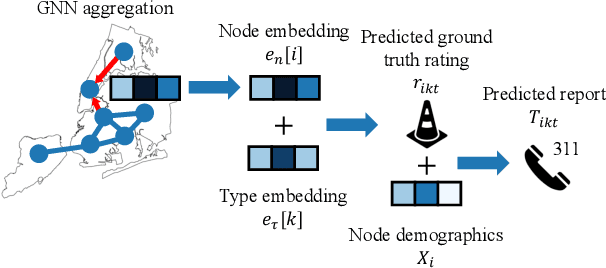

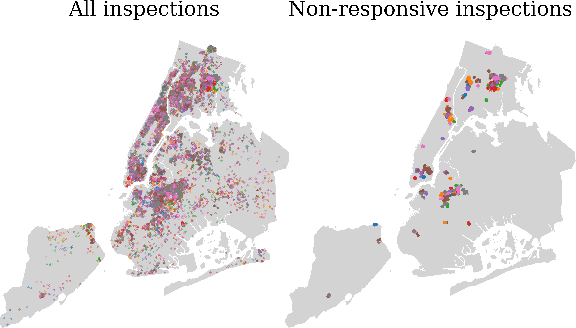
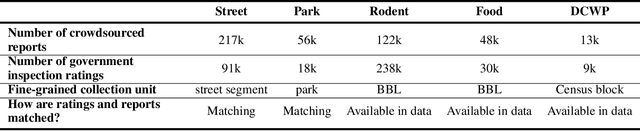
Graph neural networks (GNNs) are widely used in urban spatiotemporal forecasting, such as predicting infrastructure problems. In this setting, government officials wish to know in which neighborhoods incidents like potholes or rodent issues occur. The true state of incidents (e.g., street conditions) for each neighborhood is observed via government inspection ratings. However, these ratings are only conducted for a sparse set of neighborhoods and incident types. We also observe the state of incidents via crowdsourced reports, which are more densely observed but may be biased due to heterogeneous reporting behavior. First, for such settings, we propose a multiview, multioutput GNN-based model that uses both unbiased rating data and biased reporting data to predict the true latent state of incidents. Second, we investigate a case study of New York City urban incidents and collect, standardize, and make publicly available a dataset of 9,615,863 crowdsourced reports and 1,041,415 government inspection ratings over 3 years and across 139 types of incidents. Finally, we show on both real and semi-synthetic data that our model can better predict the latent state compared to models that use only reporting data or models that use only rating data, especially when rating data is sparse and reports are predictive of ratings. We also quantify demographic biases in crowdsourced reporting, e.g., higher-income neighborhoods report problems at higher rates. Our analysis showcases a widely applicable approach for latent state prediction using heterogeneous, sparse, and biased data.
Correlated Errors in Large Language Models
Jun 09, 2025



Diversity in training data, architecture, and providers is assumed to mitigate homogeneity in LLMs. However, we lack empirical evidence on whether different LLMs differ meaningfully. We conduct a large-scale empirical evaluation on over 350 LLMs overall, using two popular leaderboards and a resume-screening task. We find substantial correlation in model errors -- on one leaderboard dataset, models agree 60% of the time when both models err. We identify factors driving model correlation, including shared architectures and providers. Crucially, however, larger and more accurate models have highly correlated errors, even with distinct architectures and providers. Finally, we show the effects of correlation in two downstream tasks: LLM-as-judge evaluation and hiring -- the latter reflecting theoretical predictions regarding algorithmic monoculture.
Bayesian Modeling of Zero-Shot Classifications for Urban Flood Detection
Mar 18, 2025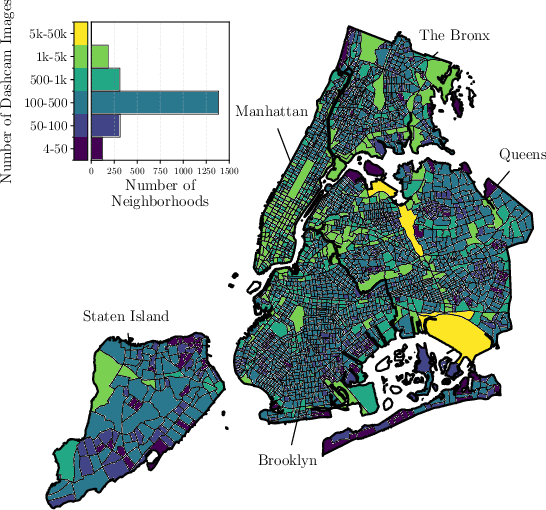
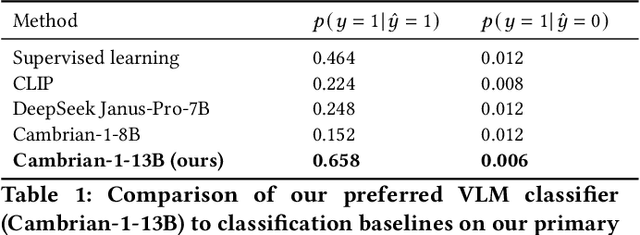

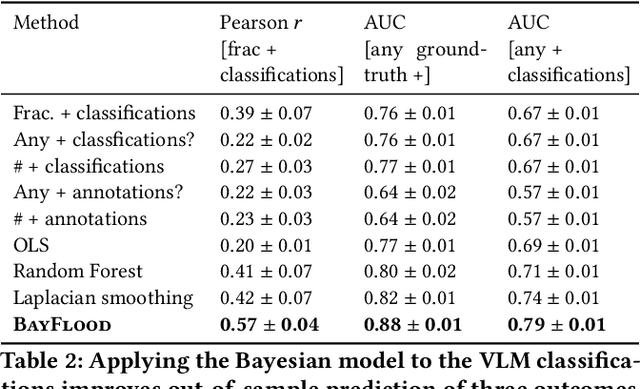
Street scene datasets, collected from Street View or dashboard cameras, offer a promising means of detecting urban objects and incidents like street flooding. However, a major challenge in using these datasets is their lack of reliable labels: there are myriad types of incidents, many types occur rarely, and ground-truth measures of where incidents occur are lacking. Here, we propose BayFlood, a two-stage approach which circumvents this difficulty. First, we perform zero-shot classification of where incidents occur using a pretrained vision-language model (VLM). Second, we fit a spatial Bayesian model on the VLM classifications. The zero-shot approach avoids the need to annotate large training sets, and the Bayesian model provides frequent desiderata in urban settings - principled measures of uncertainty, smoothing across locations, and incorporation of external data like stormwater accumulation zones. We comprehensively validate this two-stage approach, showing that VLMs provide strong zero-shot signal for floods across multiple cities and time periods, the Bayesian model improves out-of-sample prediction relative to baseline methods, and our inferred flood risk correlates with known external predictors of risk. Having validated our approach, we show it can be used to improve urban flood detection: our analysis reveals 113,738 people who are at high risk of flooding overlooked by current methods, identifies demographic biases in existing methods, and suggests locations for new flood sensors. More broadly, our results showcase how Bayesian modeling of zero-shot LM annotations represents a promising paradigm because it avoids the need to collect large labeled datasets and leverages the power of foundation models while providing the expressiveness and uncertainty quantification of Bayesian models.
Sparse Autoencoders for Hypothesis Generation
Feb 05, 2025



We describe HypotheSAEs, a general method to hypothesize interpretable relationships between text data (e.g., headlines) and a target variable (e.g., clicks). HypotheSAEs has three steps: (1) train a sparse autoencoder on text embeddings to produce interpretable features describing the data distribution, (2) select features that predict the target variable, and (3) generate a natural language interpretation of each feature (e.g., "mentions being surprised or shocked") using an LLM. Each interpretation serves as a hypothesis about what predicts the target variable. Compared to baselines, our method better identifies reference hypotheses on synthetic datasets (at least +0.06 in F1) and produces more predictive hypotheses on real datasets (~twice as many significant findings), despite requiring 1-2 orders of magnitude less compute than recent LLM-based methods. HypotheSAEs also produces novel discoveries on two well-studied tasks: explaining partisan differences in Congressional speeches and identifying drivers of engagement with online headlines.
Learning Disease Progression Models That Capture Health Disparities
Dec 20, 2024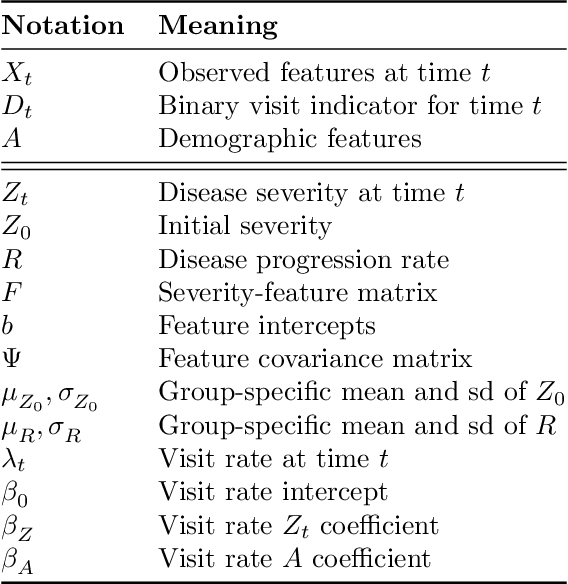
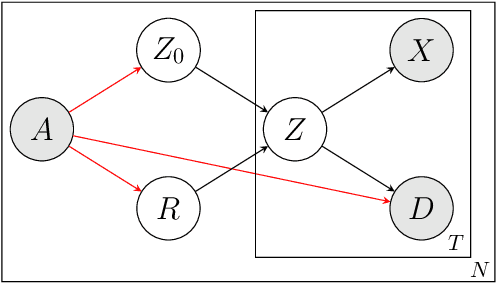
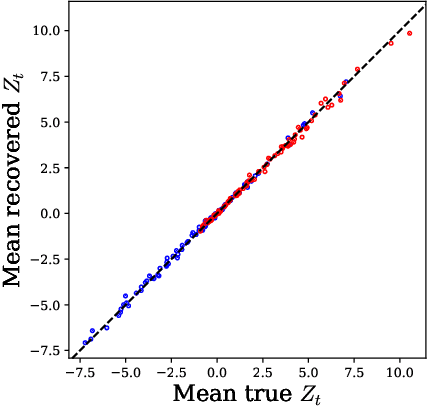
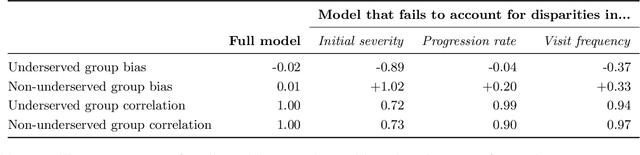
Disease progression models are widely used to inform the diagnosis and treatment of many progressive diseases. However, a significant limitation of existing models is that they do not account for health disparities that can bias the observed data. To address this, we develop an interpretable Bayesian disease progression model that captures three key health disparities: certain patient populations may (1) start receiving care only when their disease is more severe, (2) experience faster disease progression even while receiving care, or (3) receive follow-up care less frequently conditional on disease severity. We show theoretically and empirically that failing to account for disparities produces biased estimates of severity (underestimating severity for disadvantaged groups, for example). On a dataset of heart failure patients, we show that our model can identify groups that face each type of health disparity, and that accounting for these disparities meaningfully shifts which patients are considered high-risk.
User-item fairness tradeoffs in recommendations
Dec 05, 2024
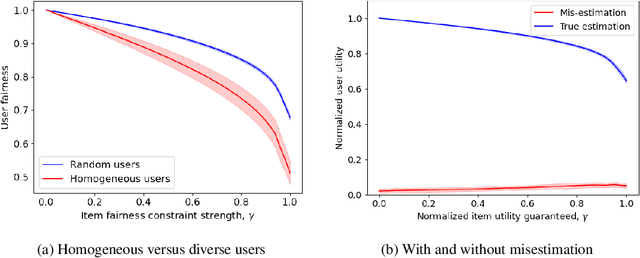
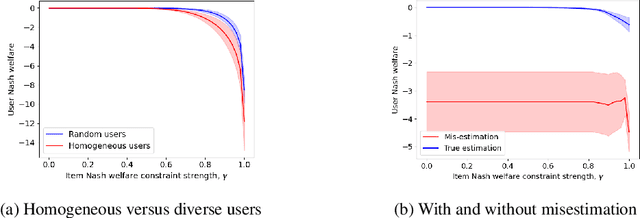

In the basic recommendation paradigm, the most (predicted) relevant item is recommended to each user. This may result in some items receiving lower exposure than they "should"; to counter this, several algorithmic approaches have been developed to ensure item fairness. These approaches necessarily degrade recommendations for some users to improve outcomes for items, leading to user fairness concerns. In turn, a recent line of work has focused on developing algorithms for multi-sided fairness, to jointly optimize user fairness, item fairness, and overall recommendation quality. This induces the question: what is the tradeoff between these objectives, and what are the characteristics of (multi-objective) optimal solutions? Theoretically, we develop a model of recommendations with user and item fairness objectives and characterize the solutions of fairness-constrained optimization. We identify two phenomena: (a) when user preferences are diverse, there is "free" item and user fairness; and (b) users whose preferences are misestimated can be especially disadvantaged by item fairness constraints. Empirically, we prototype a recommendation system for preprints on arXiv and implement our framework, measuring the phenomena in practice and showing how these phenomena inform the design of markets with recommendation systems-intermediated matching.