 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Bayesian Model for Multi-stage Censoring
Nov 18, 2025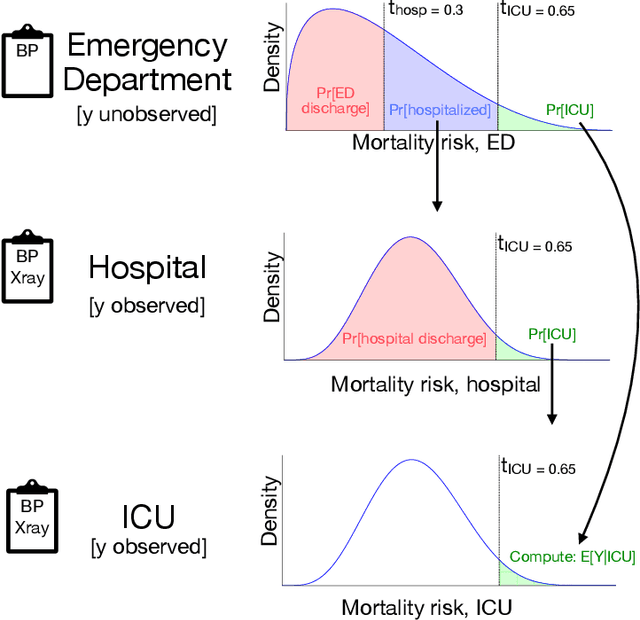
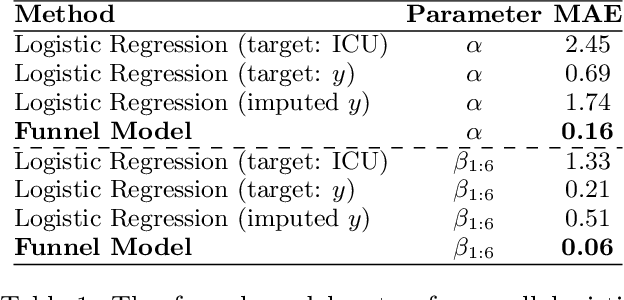

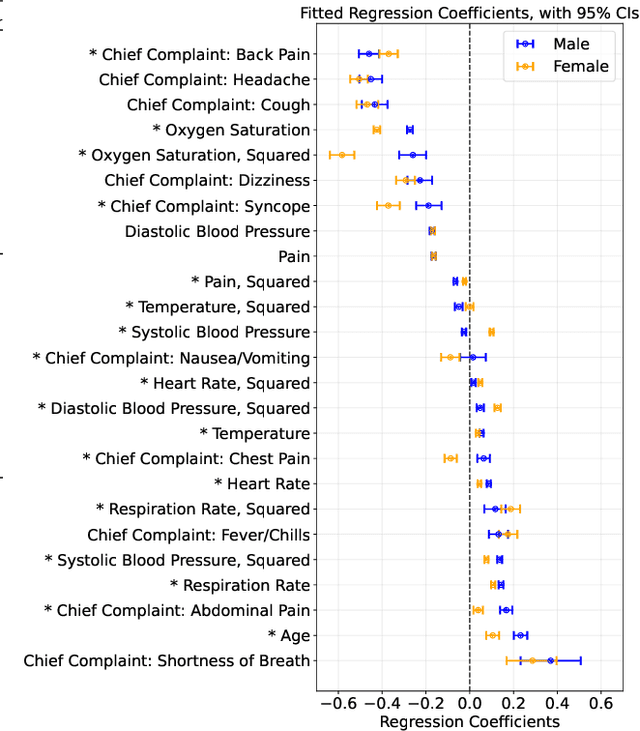
Many sequential decision settings in healthcare feature funnel structures characterized by a series of stages, such as screenings or evaluations, where the number of patients who advance to each stage progressively decreases and decisions become increasingly costly. For example, an oncologist may first conduct a breast exam, followed by a mammogram for patients with concerning exams, followed by a biopsy for patients with concerning mammograms. A key challenge is that the ground truth outcome, such as the biopsy result, is only revealed at the end of this funnel. The selective censoring of the ground truth can introduce statistical biases in risk estimation, especially in underserved patient groups, whose outcomes are more frequently censored. We develop a Bayesian model for funnel decision structures, drawing from prior work on selective labels and censoring. We first show in synthetic settings that our model is able to recover the true parameters and predict outcomes for censored patients more accurately than baselines. We then apply our model to a dataset of emergency department visits, where in-hospital mortality is observed only for those who are admitted to either the hospital or ICU. We find that there are gender-based differences in hospital and ICU admissions. In particular, our model estimates that the mortality risk threshold to admit women to the ICU is higher for women (5.1%) than for men (4.5%).
Urban Incident Prediction with Graph Neural Networks: Integrating Government Ratings and Crowdsourced Reports
Jun 10, 2025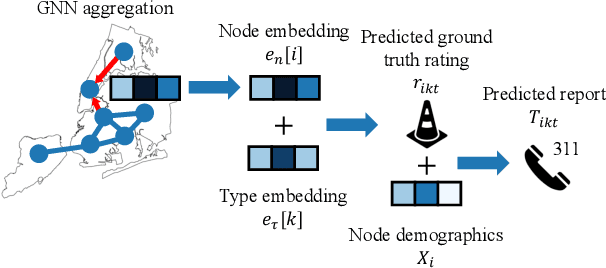

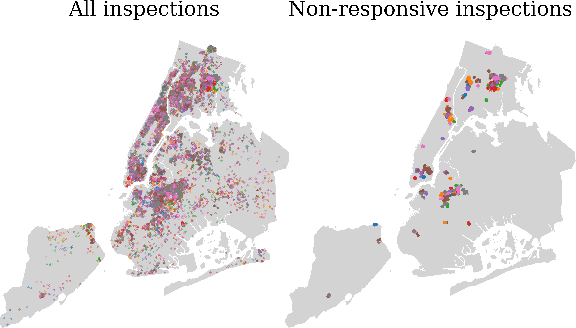
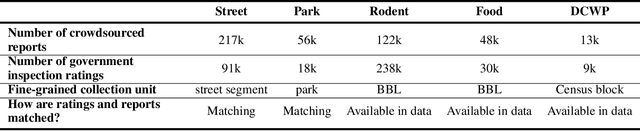
Graph neural networks (GNNs) are widely used in urban spatiotemporal forecasting, such as predicting infrastructure problems. In this setting, government officials wish to know in which neighborhoods incidents like potholes or rodent issues occur. The true state of incidents (e.g., street conditions) for each neighborhood is observed via government inspection ratings. However, these ratings are only conducted for a sparse set of neighborhoods and incident types. We also observe the state of incidents via crowdsourced reports, which are more densely observed but may be biased due to heterogeneous reporting behavior. First, for such settings, we propose a multiview, multioutput GNN-based model that uses both unbiased rating data and biased reporting data to predict the true latent state of incidents. Second, we investigate a case study of New York City urban incidents and collect, standardize, and make publicly available a dataset of 9,615,863 crowdsourced reports and 1,041,415 government inspection ratings over 3 years and across 139 types of incidents. Finally, we show on both real and semi-synthetic data that our model can better predict the latent state compared to models that use only reporting data or models that use only rating data, especially when rating data is sparse and reports are predictive of ratings. We also quantify demographic biases in crowdsourced reporting, e.g., higher-income neighborhoods report problems at higher rates. Our analysis showcases a widely applicable approach for latent state prediction using heterogeneous, sparse, and biased data.
Evaluating multiple models using labeled and unlabeled data
Jan 21, 2025



It remains difficult to evaluate machine learning classifiers in the absence of a large, labeled dataset. While labeled data can be prohibitively expensive or impossible to obtain, unlabeled data is plentiful. Here, we introduce Semi-Supervised Model Evaluation (SSME), a method that uses both labeled and unlabeled data to evaluate machine learning classifiers. SSME is the first evaluation method to take advantage of the fact that: (i) there are frequently multiple classifiers for the same task, (ii) continuous classifier scores are often available for all classes, and (iii) unlabeled data is often far more plentiful than labeled data. The key idea is to use a semi-supervised mixture model to estimate the joint distribution of ground truth labels and classifier predictions. We can then use this model to estimate any metric that is a function of classifier scores and ground truth labels (e.g., accuracy or expected calibration error). We present experiments in four domains where obtaining large labeled datasets is often impractical: (1) healthcare, (2) content moderation, (3) molecular property prediction, and (4) image annotation. Our results demonstrate that SSME estimates performance more accurately than do competing methods, reducing error by 5.1x relative to using labeled data alone and 2.4x relative to the next best competing method. SSME also improves accuracy when evaluating performance across subsets of the test distribution (e.g., specific demographic subgroups) and when evaluating the performance of language models.