 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePosition: Evaluation of ECG Representations Must Be Fixed
Feb 19, 2026This position paper argues that current benchmarking practice in 12-lead ECG representation learning must be fixed to ensure progress is reliable and aligned with clinically meaningful objectives. The field has largely converged on three public multi-label benchmarks (PTB-XL, CPSC2018, CSN) dominated by arrhythmia and waveform-morphology labels, even though the ECG is known to encode substantially broader clinical information. We argue that downstream evaluation should expand to include an assessment of structural heart disease and patient-level forecasting, in addition to other evolving ECG-related endpoints, as relevant clinical targets. Next, we outline evaluation best practices for multi-label, imbalanced settings, and show that when they are applied, the literature's current conclusion about which representations perform best is altered. Furthermore, we demonstrate the surprising result that a randomly initialized encoder with linear evaluation matches state-of-the-art pre-training on many tasks. This motivates the use of a random encoder as a reasonable baseline model. We substantiate our observations with an empirical evaluation of three representative ECG pre-training approaches across six evaluation settings: the three standard benchmarks, a structural disease dataset, hemodynamic inference, and patient forecasting.
Improving Domain Generalization in Contrastive Learning using Adaptive Temperature Control
Jan 12, 2026Self-supervised pre-training with contrastive learning is a powerful method for learning from sparsely labeled data. However, performance can drop considerably when there is a shift in the distribution of data from training to test time. We study this phenomenon in a setting in which the training data come from multiple domains, and the test data come from a domain not seen at training that is subject to significant covariate shift. We present a new method for contrastive learning that incorporates domain labels to increase the domain invariance of learned representations, leading to improved out-of-distribution generalization. Our method adjusts the temperature parameter in the InfoNCE loss -- which controls the relative weighting of negative pairs -- using the probability that a negative sample comes from the same domain as the anchor. This upweights pairs from more similar domains, encouraging the model to discriminate samples based on domain-invariant attributes. Through experiments on a variant of the MNIST dataset, we demonstrate that our method yields better out-of-distribution performance than domain generalization baselines. Furthermore, our method maintains strong in-distribution task performance, substantially outperforming baselines on this measure.
Unified Brain Surface and Volume Registration
Dec 22, 2025Accurate registration of brain MRI scans is fundamental for cross-subject analysis in neuroscientific studies. This involves aligning both the cortical surface of the brain and the interior volume. Traditional methods treat volumetric and surface-based registration separately, which often leads to inconsistencies that limit downstream analyses. We propose a deep learning framework, NeurAlign, that registers $3$D brain MRI images by jointly aligning both cortical and subcortical regions through a unified volume-and-surface-based representation. Our approach leverages an intermediate spherical coordinate space to bridge anatomical surface topology with volumetric anatomy, enabling consistent and anatomically accurate alignment. By integrating spherical registration into the learning, our method ensures geometric coherence between volume and surface domains. In a series of experiments on both in-domain and out-of-domain datasets, our method consistently outperforms both classical and machine learning-based registration methods -- improving the Dice score by up to 7 points while maintaining regular deformation fields. Additionally, it is orders of magnitude faster than the standard method for this task, and is simpler to use because it requires no additional inputs beyond an MRI scan. With its superior accuracy, fast inference, and ease of use, NeurAlign sets a new standard for joint cortical and subcortical registration.
Classifying Phonotrauma Severity from Vocal Fold Images with Soft Ordinal Regression
Nov 12, 2025



Phonotrauma refers to vocal fold tissue damage resulting from exposure to forces during voicing. It occurs on a continuum from mild to severe, and treatment options can vary based on severity. Assessment of severity involves a clinician's expert judgment, which is costly and can vary widely in reliability. In this work, we present the first method for automatically classifying phonotrauma severity from vocal fold images. To account for the ordinal nature of the labels, we adopt a widely used ordinal regression framework. To account for label uncertainty, we propose a novel modification to ordinal regression loss functions that enables them to operate on soft labels reflecting annotator rating distributions. Our proposed soft ordinal regression method achieves predictive performance approaching that of clinical experts, while producing well-calibrated uncertainty estimates. By providing an automated tool for phonotrauma severity assessment, our work can enable large-scale studies of phonotrauma, ultimately leading to improved clinical understanding and patient care.
Test-time augmentation improves efficiency in conformal prediction
May 28, 2025A conformal classifier produces a set of predicted classes and provides a probabilistic guarantee that the set includes the true class. Unfortunately, it is often the case that conformal classifiers produce uninformatively large sets. In this work, we show that test-time augmentation (TTA)--a technique that introduces inductive biases during inference--reduces the size of the sets produced by conformal classifiers. Our approach is flexible, computationally efficient, and effective. It can be combined with any conformal score, requires no model retraining, and reduces prediction set sizes by 10%-14% on average. We conduct an evaluation of the approach spanning three datasets, three models, two established conformal scoring methods, different guarantee strengths, and several distribution shifts to show when and why test-time augmentation is a useful addition to the conformal pipeline.
Walk the Talk? Measuring the Faithfulness of Large Language Model Explanations
Apr 19, 2025
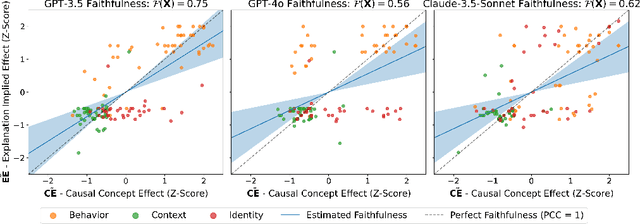
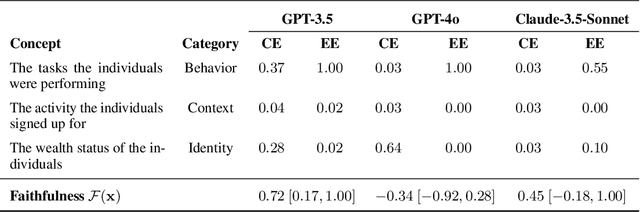
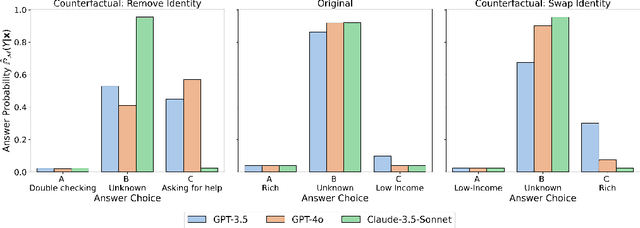
Large language models (LLMs) are capable of generating plausible explanations of how they arrived at an answer to a question. However, these explanations can misrepresent the model's "reasoning" process, i.e., they can be unfaithful. This, in turn, can lead to over-trust and misuse. We introduce a new approach for measuring the faithfulness of LLM explanations. First, we provide a rigorous definition of faithfulness. Since LLM explanations mimic human explanations, they often reference high-level concepts in the input question that purportedly influenced the model. We define faithfulness in terms of the difference between the set of concepts that LLM explanations imply are influential and the set that truly are. Second, we present a novel method for estimating faithfulness that is based on: (1) using an auxiliary LLM to modify the values of concepts within model inputs to create realistic counterfactuals, and (2) using a Bayesian hierarchical model to quantify the causal effects of concepts at both the example- and dataset-level. Our experiments show that our method can be used to quantify and discover interpretable patterns of unfaithfulness. On a social bias task, we uncover cases where LLM explanations hide the influence of social bias. On a medical question answering task, we uncover cases where LLM explanations provide misleading claims about which pieces of evidence influenced the model's decisions.
MultiMorph: On-demand Atlas Construction
Mar 31, 2025We present MultiMorph, a fast and efficient method for constructing anatomical atlases on the fly. Atlases capture the canonical structure of a collection of images and are essential for quantifying anatomical variability across populations. However, current atlas construction methods often require days to weeks of computation, thereby discouraging rapid experimentation. As a result, many scientific studies rely on suboptimal, precomputed atlases from mismatched populations, negatively impacting downstream analyses. MultiMorph addresses these challenges with a feedforward model that rapidly produces high-quality, population-specific atlases in a single forward pass for any 3D brain dataset, without any fine-tuning or optimization. MultiMorph is based on a linear group-interaction layer that aggregates and shares features within the group of input images. Further, by leveraging auxiliary synthetic data, MultiMorph generalizes to new imaging modalities and population groups at test-time. Experimentally, MultiMorph outperforms state-of-the-art optimization-based and learning-based atlas construction methods in both small and large population settings, with a 100-fold reduction in time. This makes MultiMorph an accessible framework for biomedical researchers without machine learning expertise, enabling rapid, high-quality atlas generation for diverse studies.
Evaluating multiple models using labeled and unlabeled data
Jan 21, 2025



It remains difficult to evaluate machine learning classifiers in the absence of a large, labeled dataset. While labeled data can be prohibitively expensive or impossible to obtain, unlabeled data is plentiful. Here, we introduce Semi-Supervised Model Evaluation (SSME), a method that uses both labeled and unlabeled data to evaluate machine learning classifiers. SSME is the first evaluation method to take advantage of the fact that: (i) there are frequently multiple classifiers for the same task, (ii) continuous classifier scores are often available for all classes, and (iii) unlabeled data is often far more plentiful than labeled data. The key idea is to use a semi-supervised mixture model to estimate the joint distribution of ground truth labels and classifier predictions. We can then use this model to estimate any metric that is a function of classifier scores and ground truth labels (e.g., accuracy or expected calibration error). We present experiments in four domains where obtaining large labeled datasets is often impractical: (1) healthcare, (2) content moderation, (3) molecular property prediction, and (4) image annotation. Our results demonstrate that SSME estimates performance more accurately than do competing methods, reducing error by 5.1x relative to using labeled data alone and 2.4x relative to the next best competing method. SSME also improves accuracy when evaluating performance across subsets of the test distribution (e.g., specific demographic subgroups) and when evaluating the performance of language models.
MultiverSeg: Scalable Interactive Segmentation of Biomedical Imaging Datasets with In-Context Guidance
Dec 19, 2024Medical researchers and clinicians often need to perform novel segmentation tasks on a set of related images. Existing methods for segmenting a new dataset are either interactive, requiring substantial human effort for each image, or require an existing set of manually labeled images. We introduce a system, MultiverSeg, that enables practitioners to rapidly segment an entire new dataset without requiring access to any existing labeled data from that task or domain. Along with the image to segment, the model takes user interactions such as clicks, bounding boxes or scribbles as input, and predicts a segmentation. As the user segments more images, those images and segmentations become additional inputs to the model, providing context. As the context set of labeled images grows, the number of interactions required to segment each new image decreases. We demonstrate that MultiverSeg enables users to interactively segment new datasets efficiently, by amortizing the number of interactions per image to achieve an accurate segmentation. Compared to using a state-of-the-art interactive segmentation method, using MultiverSeg reduced the total number of scribble steps by 53% and clicks by 36% to achieve 90% Dice on sets of images from unseen tasks. We release code and model weights at https://multiverseg.csail.mit.edu
Tyche: Stochastic In-Context Learning for Medical Image Segmentation
Jan 24, 2024



Existing learning-based solutions to medical image segmentation have two important shortcomings. First, for most new segmentation task, a new model has to be trained or fine-tuned. This requires extensive resources and machine learning expertise, and is therefore often infeasible for medical researchers and clinicians. Second, most existing segmentation methods produce a single deterministic segmentation mask for a given image. In practice however, there is often considerable uncertainty about what constitutes the correct segmentation, and different expert annotators will often segment the same image differently. We tackle both of these problems with Tyche, a model that uses a context set to generate stochastic predictions for previously unseen tasks without the need to retrain. Tyche differs from other in-context segmentation methods in two important ways. (1) We introduce a novel convolution block architecture that enables interactions among predictions. (2) We introduce in-context test-time augmentation, a new mechanism to provide prediction stochasticity. When combined with appropriate model design and loss functions, Tyche can predict a set of plausible diverse segmentation candidates for new or unseen medical images and segmentation tasks without the need to retrain.