 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncentives shape how humans co-create with generative AI
Apr 04, 2026Generative AI is quickly becoming an integral part of people's everyday workflows. Early evidence has shown that while generative AI can increase individual-level productivity, it does so at the cost of collective diversity, potentially narrowing the set of ideas and perspectives produced. Our research stands in contrast to this concern: through a pre-registered randomized control trial, we show that incentives mediate AI's homogenizing force in a creative writing task where participants can use AI interactively. Participants rewarded for originality relative to peers produce collectively more diverse writing than those rewarded for quality alone. This divergence is driven not by abandoning AI, but by how participants use it: those incentivized for originality incorporate fewer AI suggestions verbatim, relying on the model more selectively for brainstorming, proofreading, and targeted edits. Our results reveal that the effects of generative AI depend not only on the technology itself, but also the behavioral strategies and incentive structures surrounding its use.
Strategic Candidacy in Generative AI Arenas
Mar 27, 2026AI arenas, which rank generative models from pairwise preferences of users, are a popular method for measuring the relative performance of models in the course of their organic use. Because rankings are computed from noisy preferences, there is a concern that model producers can exploit this randomness by submitting many models (e.g., multiple variants of essentially the same model) and thereby artificially improve the rank of their top models. This can lead to degradations in the quality, and therefore the usefulness, of the ranking. In this paper, we begin by establishing, both theoretically and in simulations calibrated to data from the platform Arena (formerly LMArena, Chatbot Arena), conditions under which producers can benefit from submitting clones when their goal is to be ranked highly. We then propose a new mechanism for ranking models from pairwise comparisons, called You-Rank-We-Rank (YRWR). It requires that producers submit rankings over their own models and uses these rankings to correct statistical estimates of model quality. We prove that this mechanism is approximately clone-robust, in the sense that a producer cannot improve their rank much by doing anything other than submitting each of their unique models exactly once. Moreover, to the extent that model producers are able to correctly rank their own models, YRWR improves overall ranking accuracy. In further simulations, we show that indeed the mechanism is approximately clone-robust and quantify improvements to ranking accuracy, even under producer misranking.
The Subjectivity of Monoculture
Feb 27, 2026Machine learning models -- including large language models (LLMs) -- are often said to exhibit monoculture, where outputs agree strikingly often. But what does it actually mean for models to agree too much? We argue that this question is inherently subjective, relying on two key decisions. First, the analyst must specify a baseline null model for what "independence" should look like. This choice is inherently subjective, and as we show, different null models result in dramatically different inferences about excess agreement. Second, we show that inferences depend on the population of models and items under consideration. Models that seem highly correlated in one context may appear independent when evaluated on a different set of questions, or against a different set of peers. Experiments on two large-scale benchmarks validate our theoretical findings. For example, we find drastically different inferences when using a null model with item difficulty compared to previous works that do not. Together, our results reframe monoculture evaluation not as an absolute property of model behavior, but as a context-dependent inference problem.
Statistical Guarantees in the Search for Less Discriminatory Algorithms
Dec 30, 2025Recent scholarship has argued that firms building data-driven decision systems in high-stakes domains like employment, credit, and housing should search for "less discriminatory algorithms" (LDAs) (Black et al., 2024). That is, for a given decision problem, firms considering deploying a model should make a good-faith effort to find equally performant models with lower disparate impact across social groups. Evidence from the literature on model multiplicity shows that randomness in training pipelines can lead to multiple models with the same performance, but meaningful variations in disparate impact. This suggests that developers can find LDAs simply by randomly retraining models. Firms cannot continue retraining forever, though, which raises the question: What constitutes a good-faith effort? In this paper, we formalize LDA search via model multiplicity as an optimal stopping problem, where a model developer with limited information wants to produce strong evidence that they have sufficiently explored the space of models. Our primary contribution is an adaptive stopping algorithm that yields a high-probability upper bound on the gains achievable from a continued search, allowing the developer to certify (e.g., to a court) that their search was sufficient. We provide a framework under which developers can impose stronger assumptions about the distribution of models, yielding correspondingly stronger bounds. We validate the method on real-world credit, employment and housing datasets.
Double Machine Learning for Causal Inference under Shared-State Interference
Apr 10, 2025Researchers and practitioners often wish to measure treatment effects in settings where units interact via markets and recommendation systems. In these settings, units are affected by certain shared states, like prices, algorithmic recommendations or social signals. We formalize this structure, calling it shared-state interference, and argue that our formulation captures many relevant applied settings. Our key modeling assumption is that individuals' potential outcomes are independent conditional on the shared state. We then prove an extension of a double machine learning (DML) theorem providing conditions for achieving efficient inference under shared-state interference. We also instantiate our general theorem in several models of interest where it is possible to efficiently estimate the average direct effect (ADE) or global average treatment effect (GATE).
Evaluating multiple models using labeled and unlabeled data
Jan 21, 2025



It remains difficult to evaluate machine learning classifiers in the absence of a large, labeled dataset. While labeled data can be prohibitively expensive or impossible to obtain, unlabeled data is plentiful. Here, we introduce Semi-Supervised Model Evaluation (SSME), a method that uses both labeled and unlabeled data to evaluate machine learning classifiers. SSME is the first evaluation method to take advantage of the fact that: (i) there are frequently multiple classifiers for the same task, (ii) continuous classifier scores are often available for all classes, and (iii) unlabeled data is often far more plentiful than labeled data. The key idea is to use a semi-supervised mixture model to estimate the joint distribution of ground truth labels and classifier predictions. We can then use this model to estimate any metric that is a function of classifier scores and ground truth labels (e.g., accuracy or expected calibration error). We present experiments in four domains where obtaining large labeled datasets is often impractical: (1) healthcare, (2) content moderation, (3) molecular property prediction, and (4) image annotation. Our results demonstrate that SSME estimates performance more accurately than do competing methods, reducing error by 5.1x relative to using labeled data alone and 2.4x relative to the next best competing method. SSME also improves accuracy when evaluating performance across subsets of the test distribution (e.g., specific demographic subgroups) and when evaluating the performance of language models.
Competition and Diversity in Generative AI
Dec 11, 2024Recent evidence suggests that the use of generative artificial intelligence reduces the diversity of content produced. In this work, we develop a game-theoretic model to explore the downstream consequences of content homogeneity when producers use generative AI to compete with one another. At equilibrium, players indeed produce content that is less diverse than optimal. However, stronger competition mitigates homogeneity and induces more diverse production. Perhaps more surprisingly, we show that a generative AI model that performs well in isolation (i.e., according to a benchmark) may fail to do so when faced with competition, and vice versa. We validate our results empirically by using language models to play Scattergories, a word game in which players are rewarded for producing answers that are both correct and unique. We discuss how the interplay between competition and homogeneity has implications for the development, evaluation, and use of generative AI.
Integrating Expert Judgment and Algorithmic Decision Making: An Indistinguishability Framework
Oct 11, 2024
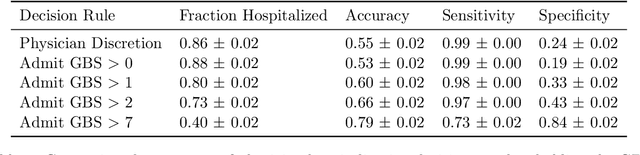


We introduce a novel framework for human-AI collaboration in prediction and decision tasks. Our approach leverages human judgment to distinguish inputs which are algorithmically indistinguishable, or "look the same" to any feasible predictive algorithm. We argue that this framing clarifies the problem of human-AI collaboration in prediction and decision tasks, as experts often form judgments by drawing on information which is not encoded in an algorithm's training data. Algorithmic indistinguishability yields a natural test for assessing whether experts incorporate this kind of "side information", and further provides a simple but principled method for selectively incorporating human feedback into algorithmic predictions. We show that this method provably improves the performance of any feasible algorithmic predictor and precisely quantify this improvement. We demonstrate the utility of our framework in a case study of emergency room triage decisions, where we find that although algorithmic risk scores are highly competitive with physicians, there is strong evidence that physician judgments provide signal which could not be replicated by any predictive algorithm. This insight yields a range of natural decision rules which leverage the complementary strengths of human experts and predictive algorithms.
Unstable Unlearning: The Hidden Risk of Concept Resurgence in Diffusion Models
Oct 10, 2024
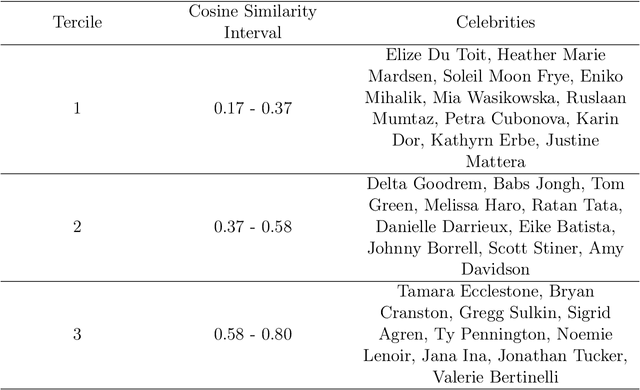
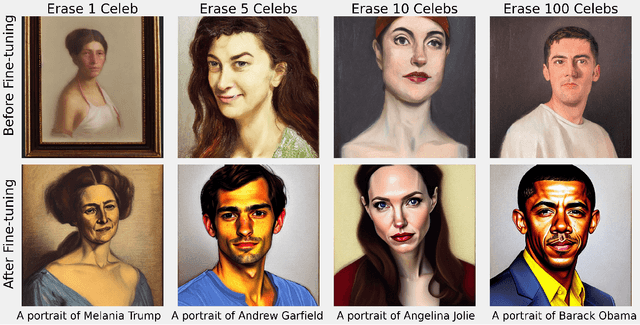
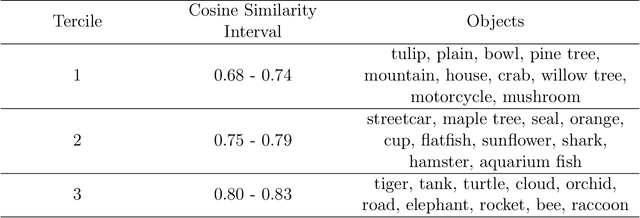
Text-to-image diffusion models rely on massive, web-scale datasets. Training them from scratch is computationally expensive, and as a result, developers often prefer to make incremental updates to existing models. These updates often compose fine-tuning steps (to learn new concepts or improve model performance) with "unlearning" steps (to "forget" existing concepts, such as copyrighted works or explicit content). In this work, we demonstrate a critical and previously unknown vulnerability that arises in this paradigm: even under benign, non-adversarial conditions, fine-tuning a text-to-image diffusion model on seemingly unrelated images can cause it to "relearn" concepts that were previously "unlearned." We comprehensively investigate the causes and scope of this phenomenon, which we term concept resurgence, by performing a series of experiments which compose "mass concept erasure" (the current state of the art for unlearning in text-to-image diffusion models (Lu et al., 2024)) with subsequent fine-tuning of Stable Diffusion v1.4. Our findings underscore the fragility of composing incremental model updates, and raise serious new concerns about current approaches to ensuring the safety and alignment of text-to-image diffusion models.
Distinguishing the Indistinguishable: Human Expertise in Algorithmic Prediction
Feb 01, 2024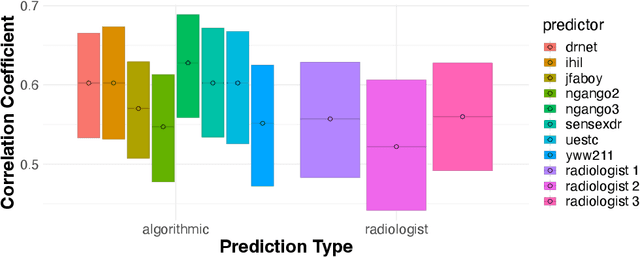
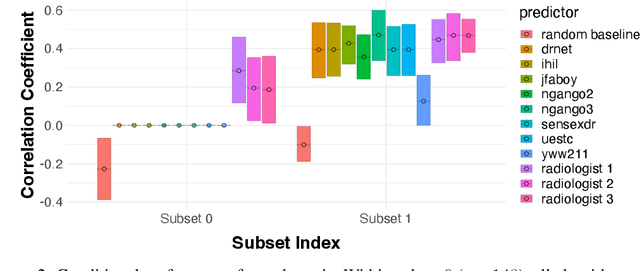
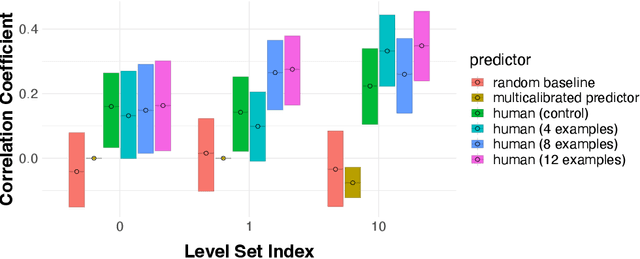

We introduce a novel framework for incorporating human expertise into algorithmic predictions. Our approach focuses on the use of human judgment to distinguish inputs which `look the same' to any feasible predictive algorithm. We argue that this framing clarifies the problem of human/AI collaboration in prediction tasks, as experts often have access to information -- particularly subjective information -- which is not encoded in the algorithm's training data. We use this insight to develop a set of principled algorithms for selectively incorporating human feedback only when it improves the performance of any feasible predictor. We find empirically that although algorithms often outperform their human counterparts on average, human judgment can significantly improve algorithmic predictions on specific instances (which can be identified ex-ante). In an X-ray classification task, we find that this subset constitutes nearly 30% of the patient population. Our approach provides a natural way of uncovering this heterogeneity and thus enabling effective human-AI collaboration.