 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCSPI-MT: Calibrated Safe Policy Improvement with Multiple Testing for Threshold Policies
Aug 21, 2024


When modifying existing policies in high-risk settings, it is often necessary to ensure with high certainty that the newly proposed policy improves upon a baseline, such as the status quo. In this work, we consider the problem of safe policy improvement, where one only adopts a new policy if it is deemed to be better than the specified baseline with at least pre-specified probability. We focus on threshold policies, a ubiquitous class of policies with applications in economics, healthcare, and digital advertising. Existing methods rely on potentially underpowered safety checks and limit the opportunities for finding safe improvements, so too often they must revert to the baseline to maintain safety. We overcome these issues by leveraging the most powerful safety test in the asymptotic regime and allowing for multiple candidates to be tested for improvement over the baseline. We show that in adversarial settings, our approach controls the rate of adopting a policy worse than the baseline to the pre-specified error level, even in moderate sample sizes. We present CSPI and CSPI-MT, two novel heuristics for selecting cutoff(s) to maximize the policy improvement from baseline. We demonstrate through both synthetic and external datasets that our approaches improve both the detection rates of safe policies and the realized improvement, particularly under stringent safety requirements and low signal-to-noise conditions.
Matched Pair Calibration for Ranking Fairness
Jun 20, 2023



We propose a test of fairness in score-based ranking systems called matched pair calibration. Our approach constructs a set of matched item pairs with minimal confounding differences between subgroups before computing an appropriate measure of ranking error over the set. The matching step ensures that we compare subgroup outcomes between identically scored items so that measured performance differences directly imply unfairness in subgroup-level exposures. We show how our approach generalizes the fairness intuitions of calibration from a binary classification setting to ranking and connect our approach to other proposals for ranking fairness measures. Moreover, our strategy shows how the logic of marginal outcome tests extends to cases where the analyst has access to model scores. Lastly, we provide an example of applying matched pair calibration to a real-word ranking data set to demonstrate its efficacy in detecting ranking bias.
Adaptive Sampling Strategies to Construct Equitable Training Datasets
Jan 31, 2022
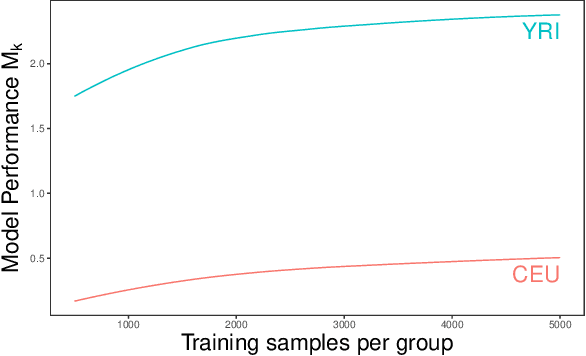
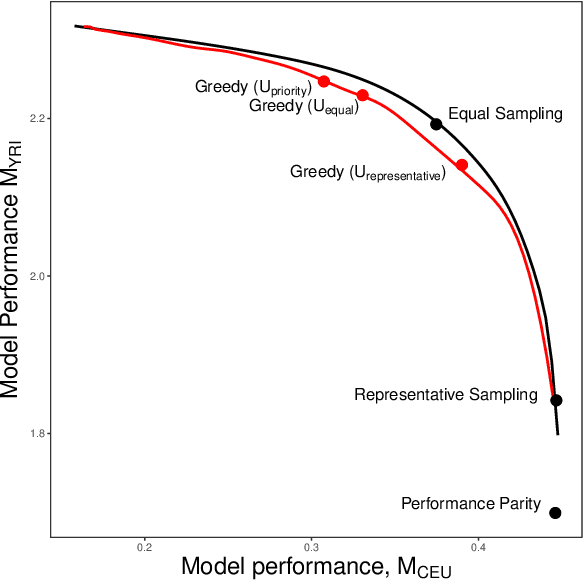
In domains ranging from computer vision to natural language processing, machine learning models have been shown to exhibit stark disparities, often performing worse for members of traditionally underserved groups. One factor contributing to these performance gaps is a lack of representation in the data the models are trained on. It is often unclear, however, how to operationalize representativeness in specific applications. Here we formalize the problem of creating equitable training datasets, and propose a statistical framework for addressing this problem. We consider a setting where a model builder must decide how to allocate a fixed data collection budget to gather training data from different subgroups. We then frame dataset creation as a constrained optimization problem, in which one maximizes a function of group-specific performance metrics based on (estimated) group-specific learning rates and costs per sample. This flexible approach incorporates preferences of model-builders and other stakeholders, as well as the statistical properties of the learning task. When data collection decisions are made sequentially, we show that under certain conditions this optimization problem can be efficiently solved even without prior knowledge of the learning rates. To illustrate our approach, we conduct a simulation study of polygenic risk scores on synthetic genomic data -- an application domain that often suffers from non-representative data collection. We find that our adaptive sampling strategy outperforms several common data collection heuristics, including equal and proportional sampling, demonstrating the value of strategic dataset design for building equitable models.
Two-sided fairness in rankings via Lorenz dominance
Oct 28, 2021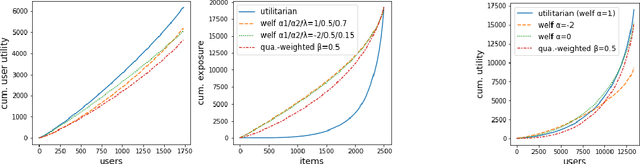

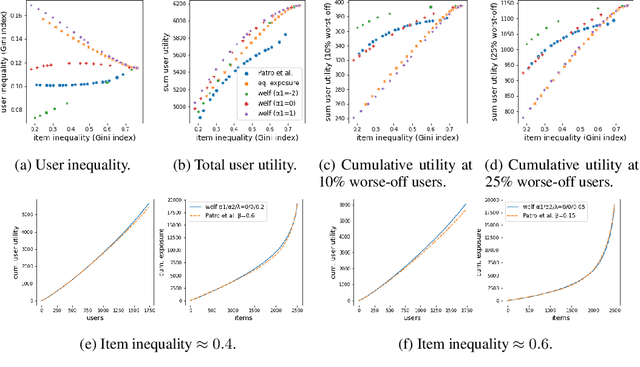

We consider the problem of generating rankings that are fair towards both users and item producers in recommender systems. We address both usual recommendation (e.g., of music or movies) and reciprocal recommendation (e.g., dating). Following concepts of distributive justice in welfare economics, our notion of fairness aims at increasing the utility of the worse-off individuals, which we formalize using the criterion of Lorenz efficiency. It guarantees that rankings are Pareto efficient, and that they maximally redistribute utility from better-off to worse-off, at a given level of overall utility. We propose to generate rankings by maximizing concave welfare functions, and develop an efficient inference procedure based on the Frank-Wolfe algorithm. We prove that unlike existing approaches based on fairness constraints, our approach always produces fair rankings. Our experiments also show that it increases the utility of the worse-off at lower costs in terms of overall utility.
Online certification of preference-based fairness for personalized recommender systems
Apr 29, 2021



We propose to assess the fairness of personalized recommender systems in the sense of envy-freeness: every (group of) user(s) should prefer their recommendations to the recommendations of other (groups of) users. Auditing for envy-freeness requires probing user preferences to detect potential blind spots, which may deteriorate recommendation performance. To control the cost of exploration, we propose an auditing algorithm based on pure exploration and conservative constraints in multi-armed bandits. We study, both theoretically and empirically, the trade-offs achieved by this algorithm.
Fairness On The Ground: Applying Algorithmic Fairness Approaches to Production Systems
Mar 24, 2021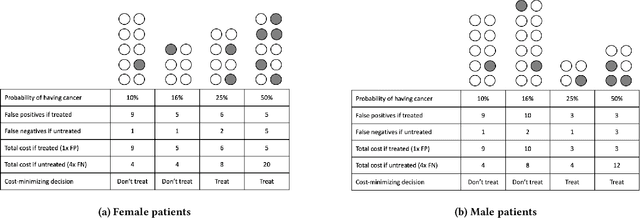
Many technical approaches have been proposed for ensuring that decisions made by machine learning systems are fair, but few of these proposals have been stress-tested in real-world systems. This paper presents an example of one team's approach to the challenge of applying algorithmic fairness approaches to complex production systems within the context of a large technology company. We discuss how we disentangle normative questions of product and policy design (like, "how should the system trade off between different stakeholders' interests and needs?") from empirical questions of system implementation (like, "is the system achieving the desired tradeoff in practice?"). We also present an approach for answering questions of the latter sort, which allows us to measure how machine learning systems and human labelers are making these tradeoffs across different relevant groups. We hope our experience integrating fairness tools and approaches into large-scale and complex production systems will be useful to other practitioners facing similar challenges, and illuminating to academics and researchers looking to better address the needs of practitioners.
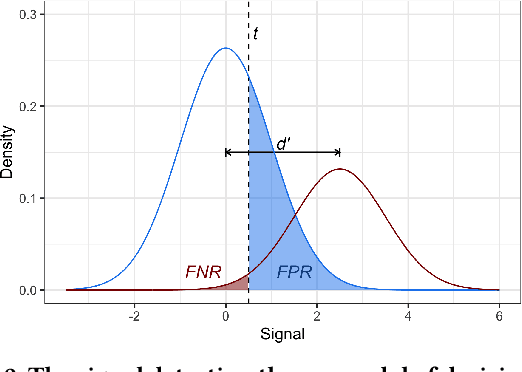
Fast Threshold Tests for Detecting Discrimination
Mar 10, 2018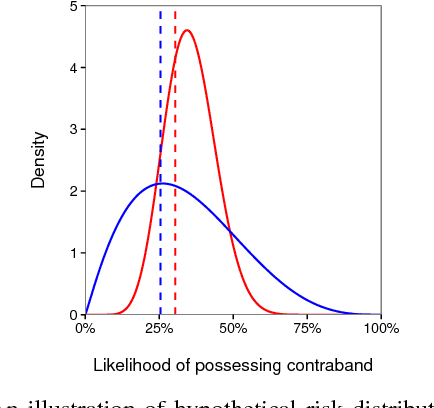

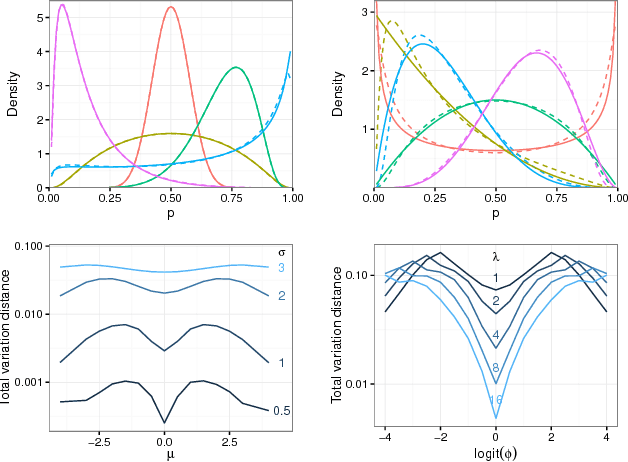
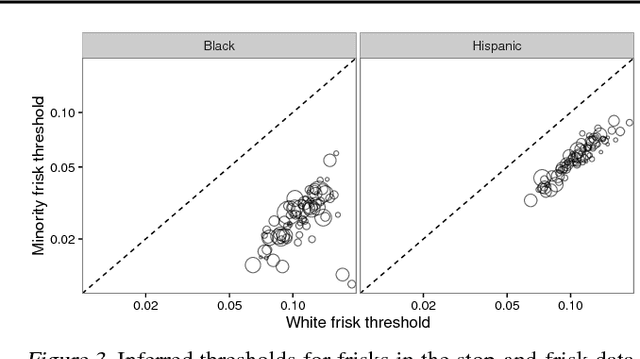
Threshold tests have recently been proposed as a useful method for detecting bias in lending, hiring, and policing decisions. For example, in the case of credit extensions, these tests aim to estimate the bar for granting loans to white and minority applicants, with a higher inferred threshold for minorities indicative of discrimination. This technique, however, requires fitting a complex Bayesian latent variable model for which inference is often computationally challenging. Here we develop a method for fitting threshold tests that is two orders of magnitude faster than the existing approach, reducing computation from hours to minutes. To achieve these performance gains, we introduce and analyze a flexible family of probability distributions on the interval [0, 1] -- which we call discriminant distributions -- that is computationally efficient to work with. We demonstrate our technique by analyzing 2.7 million police stops of pedestrians in New York City.