 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIn your own words: computationally identifying interpretable themes in free-text survey data
Mar 27, 2026Free-text survey responses can provide nuance often missed by structured questions, but remain difficult to statistically analyze. To address this, we introduce In Your Own Words, a computational framework for exploratory analyses of free-text survey data that identifies structured, interpretable themes in free-text responses more precisely than previous computational approaches, facilitating systematic analysis. To illustrate the benefits of this approach, we apply it to a new dataset of free-text descriptions of race, gender, and sexual orientation from 1,004 U.S. participants. The themes our approach learns have three practical applications in survey research. First, the themes can suggest structured questions to add to future surveys by surfacing salient constructs -- such as belonging and identity fluidity -- that existing surveys do not capture. Second, the themes reveal heterogeneity within standardized categories, explaining additional variation in health, well-being, and identity importance. Third, the themes illuminate systematic discordance between self-identified and perceived identities, highlighting mechanisms of misrecognition that existing measures do not reflect. More broadly, our framework can be deployed in a wide range of survey settings to identify interpretable themes from free text, complementing existing qualitative methods.
A Bayesian Model for Multi-stage Censoring
Nov 18, 2025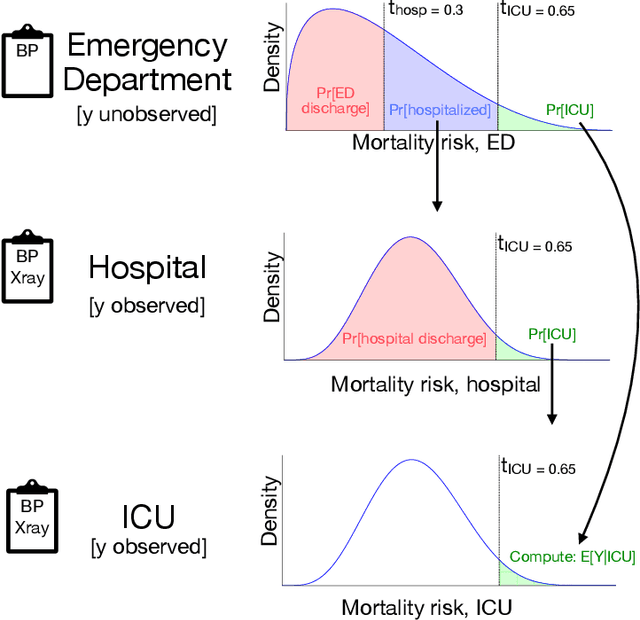
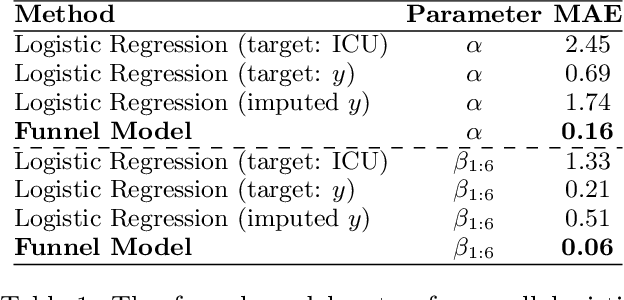

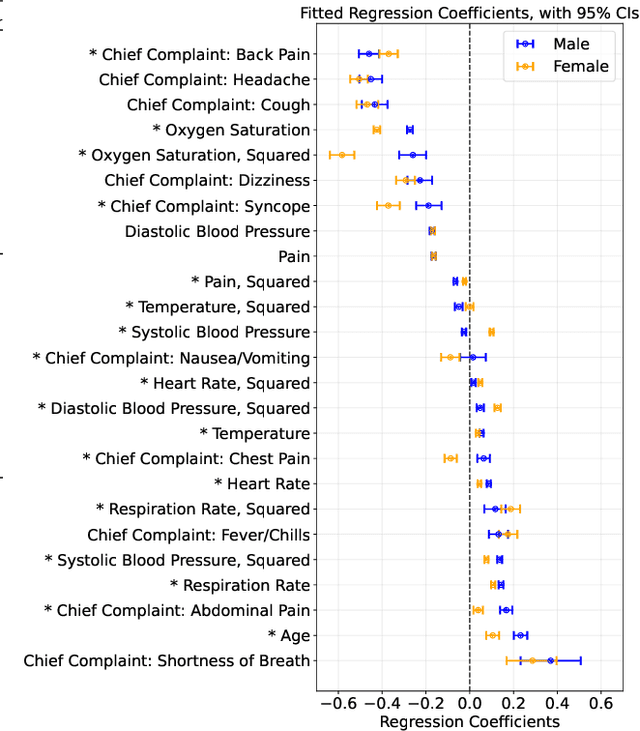
Many sequential decision settings in healthcare feature funnel structures characterized by a series of stages, such as screenings or evaluations, where the number of patients who advance to each stage progressively decreases and decisions become increasingly costly. For example, an oncologist may first conduct a breast exam, followed by a mammogram for patients with concerning exams, followed by a biopsy for patients with concerning mammograms. A key challenge is that the ground truth outcome, such as the biopsy result, is only revealed at the end of this funnel. The selective censoring of the ground truth can introduce statistical biases in risk estimation, especially in underserved patient groups, whose outcomes are more frequently censored. We develop a Bayesian model for funnel decision structures, drawing from prior work on selective labels and censoring. We first show in synthetic settings that our model is able to recover the true parameters and predict outcomes for censored patients more accurately than baselines. We then apply our model to a dataset of emergency department visits, where in-hospital mortality is observed only for those who are admitted to either the hospital or ICU. We find that there are gender-based differences in hospital and ICU admissions. In particular, our model estimates that the mortality risk threshold to admit women to the ICU is higher for women (5.1%) than for men (4.5%).
What's In My Human Feedback? Learning Interpretable Descriptions of Preference Data
Oct 30, 2025Human feedback can alter language models in unpredictable and undesirable ways, as practitioners lack a clear understanding of what feedback data encodes. While prior work studies preferences over certain attributes (e.g., length or sycophancy), automatically extracting relevant features without pre-specifying hypotheses remains challenging. We introduce What's In My Human Feedback? (WIMHF), a method to explain feedback data using sparse autoencoders. WIMHF characterizes both (1) the preferences a dataset is capable of measuring and (2) the preferences that the annotators actually express. Across 7 datasets, WIMHF identifies a small number of human-interpretable features that account for the majority of the preference prediction signal achieved by black-box models. These features reveal a wide diversity in what humans prefer, and the role of dataset-level context: for example, users on Reddit prefer informality and jokes, while annotators in HH-RLHF and PRISM disprefer them. WIMHF also surfaces potentially unsafe preferences, such as that LMArena users tend to vote against refusals, often in favor of toxic content. The learned features enable effective data curation: re-labeling the harmful examples in Arena yields large safety gains (+37%) with no cost to general performance. They also allow fine-grained personalization: on the Community Alignment dataset, we learn annotator-specific weights over subjective features that improve preference prediction. WIMHF provides a human-centered analysis method for practitioners to better understand and use preference data.
Urban Incident Prediction with Graph Neural Networks: Integrating Government Ratings and Crowdsourced Reports
Jun 10, 2025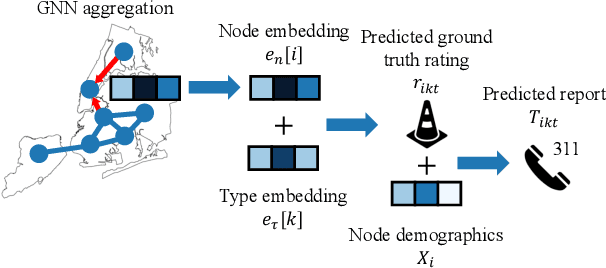

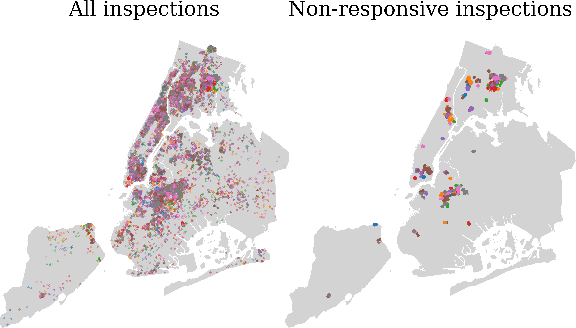
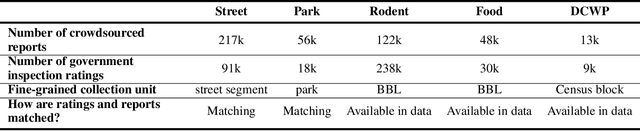
Graph neural networks (GNNs) are widely used in urban spatiotemporal forecasting, such as predicting infrastructure problems. In this setting, government officials wish to know in which neighborhoods incidents like potholes or rodent issues occur. The true state of incidents (e.g., street conditions) for each neighborhood is observed via government inspection ratings. However, these ratings are only conducted for a sparse set of neighborhoods and incident types. We also observe the state of incidents via crowdsourced reports, which are more densely observed but may be biased due to heterogeneous reporting behavior. First, for such settings, we propose a multiview, multioutput GNN-based model that uses both unbiased rating data and biased reporting data to predict the true latent state of incidents. Second, we investigate a case study of New York City urban incidents and collect, standardize, and make publicly available a dataset of 9,615,863 crowdsourced reports and 1,041,415 government inspection ratings over 3 years and across 139 types of incidents. Finally, we show on both real and semi-synthetic data that our model can better predict the latent state compared to models that use only reporting data or models that use only rating data, especially when rating data is sparse and reports are predictive of ratings. We also quantify demographic biases in crowdsourced reporting, e.g., higher-income neighborhoods report problems at higher rates. Our analysis showcases a widely applicable approach for latent state prediction using heterogeneous, sparse, and biased data.
Bayesian Modeling of Zero-Shot Classifications for Urban Flood Detection
Mar 18, 2025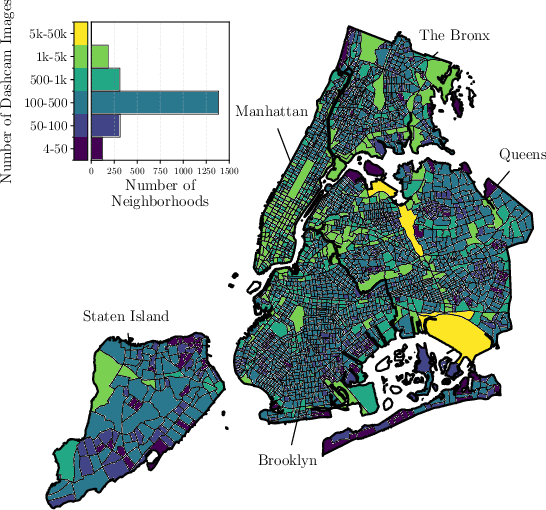
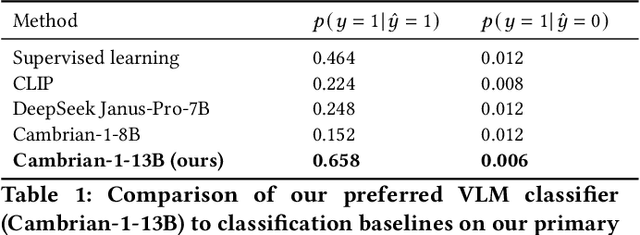

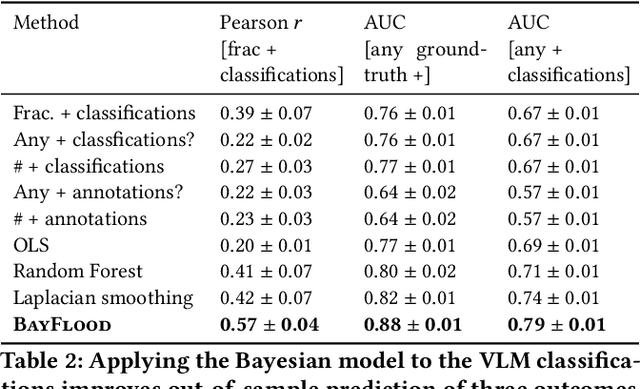
Street scene datasets, collected from Street View or dashboard cameras, offer a promising means of detecting urban objects and incidents like street flooding. However, a major challenge in using these datasets is their lack of reliable labels: there are myriad types of incidents, many types occur rarely, and ground-truth measures of where incidents occur are lacking. Here, we propose BayFlood, a two-stage approach which circumvents this difficulty. First, we perform zero-shot classification of where incidents occur using a pretrained vision-language model (VLM). Second, we fit a spatial Bayesian model on the VLM classifications. The zero-shot approach avoids the need to annotate large training sets, and the Bayesian model provides frequent desiderata in urban settings - principled measures of uncertainty, smoothing across locations, and incorporation of external data like stormwater accumulation zones. We comprehensively validate this two-stage approach, showing that VLMs provide strong zero-shot signal for floods across multiple cities and time periods, the Bayesian model improves out-of-sample prediction relative to baseline methods, and our inferred flood risk correlates with known external predictors of risk. Having validated our approach, we show it can be used to improve urban flood detection: our analysis reveals 113,738 people who are at high risk of flooding overlooked by current methods, identifies demographic biases in existing methods, and suggests locations for new flood sensors. More broadly, our results showcase how Bayesian modeling of zero-shot LM annotations represents a promising paradigm because it avoids the need to collect large labeled datasets and leverages the power of foundation models while providing the expressiveness and uncertainty quantification of Bayesian models.
Sparse Autoencoders for Hypothesis Generation
Feb 05, 2025



We describe HypotheSAEs, a general method to hypothesize interpretable relationships between text data (e.g., headlines) and a target variable (e.g., clicks). HypotheSAEs has three steps: (1) train a sparse autoencoder on text embeddings to produce interpretable features describing the data distribution, (2) select features that predict the target variable, and (3) generate a natural language interpretation of each feature (e.g., "mentions being surprised or shocked") using an LLM. Each interpretation serves as a hypothesis about what predicts the target variable. Compared to baselines, our method better identifies reference hypotheses on synthetic datasets (at least +0.06 in F1) and produces more predictive hypotheses on real datasets (~twice as many significant findings), despite requiring 1-2 orders of magnitude less compute than recent LLM-based methods. HypotheSAEs also produces novel discoveries on two well-studied tasks: explaining partisan differences in Congressional speeches and identifying drivers of engagement with online headlines.
Evaluating multiple models using labeled and unlabeled data
Jan 21, 2025



It remains difficult to evaluate machine learning classifiers in the absence of a large, labeled dataset. While labeled data can be prohibitively expensive or impossible to obtain, unlabeled data is plentiful. Here, we introduce Semi-Supervised Model Evaluation (SSME), a method that uses both labeled and unlabeled data to evaluate machine learning classifiers. SSME is the first evaluation method to take advantage of the fact that: (i) there are frequently multiple classifiers for the same task, (ii) continuous classifier scores are often available for all classes, and (iii) unlabeled data is often far more plentiful than labeled data. The key idea is to use a semi-supervised mixture model to estimate the joint distribution of ground truth labels and classifier predictions. We can then use this model to estimate any metric that is a function of classifier scores and ground truth labels (e.g., accuracy or expected calibration error). We present experiments in four domains where obtaining large labeled datasets is often impractical: (1) healthcare, (2) content moderation, (3) molecular property prediction, and (4) image annotation. Our results demonstrate that SSME estimates performance more accurately than do competing methods, reducing error by 5.1x relative to using labeled data alone and 2.4x relative to the next best competing method. SSME also improves accuracy when evaluating performance across subsets of the test distribution (e.g., specific demographic subgroups) and when evaluating the performance of language models.
Learning Disease Progression Models That Capture Health Disparities
Dec 20, 2024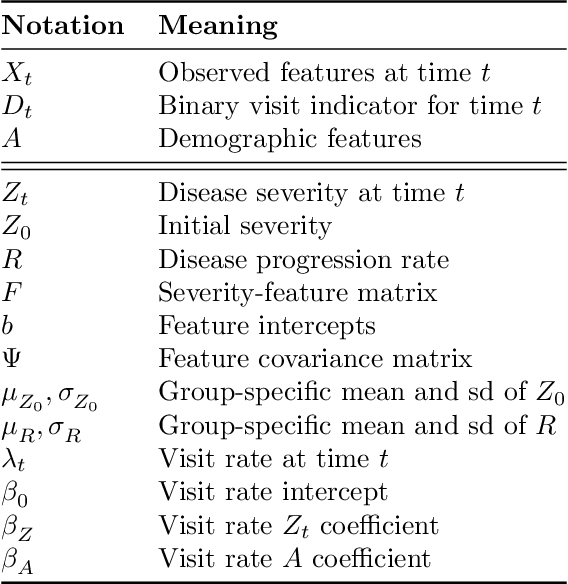
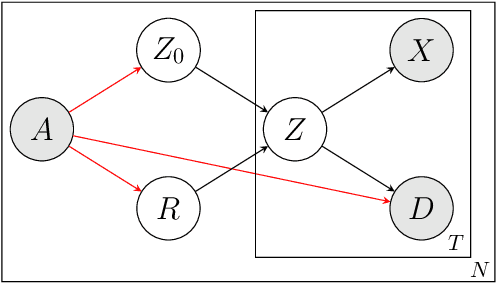
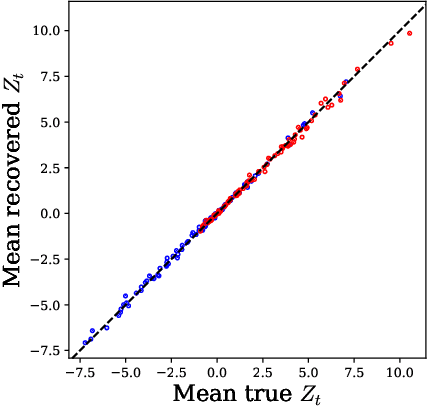
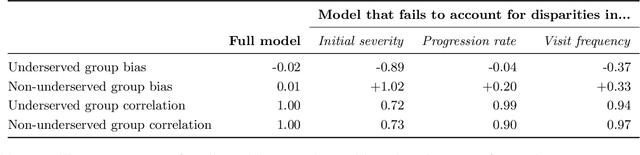
Disease progression models are widely used to inform the diagnosis and treatment of many progressive diseases. However, a significant limitation of existing models is that they do not account for health disparities that can bias the observed data. To address this, we develop an interpretable Bayesian disease progression model that captures three key health disparities: certain patient populations may (1) start receiving care only when their disease is more severe, (2) experience faster disease progression even while receiving care, or (3) receive follow-up care less frequently conditional on disease severity. We show theoretically and empirically that failing to account for disparities produces biased estimates of severity (underestimating severity for disadvantaged groups, for example). On a dataset of heart failure patients, we show that our model can identify groups that face each type of health disparity, and that accounting for these disparities meaningfully shifts which patients are considered high-risk.
Generative AI in Medicine
Dec 13, 2024

The increased capabilities of generative AI have dramatically expanded its possible use cases in medicine. We provide a comprehensive overview of generative AI use cases for clinicians, patients, clinical trial organizers, researchers, and trainees. We then discuss the many challenges -- including maintaining privacy and security, improving transparency and interpretability, upholding equity, and rigorously evaluating models -- which must be overcome to realize this potential, and the open research directions they give rise to.
Shaping AI's Impact on Billions of Lives
Dec 03, 2024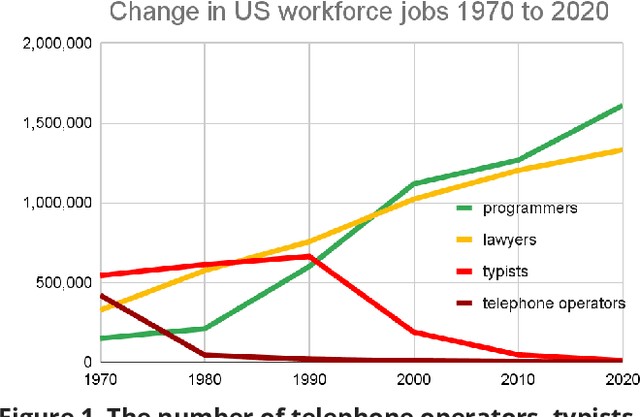
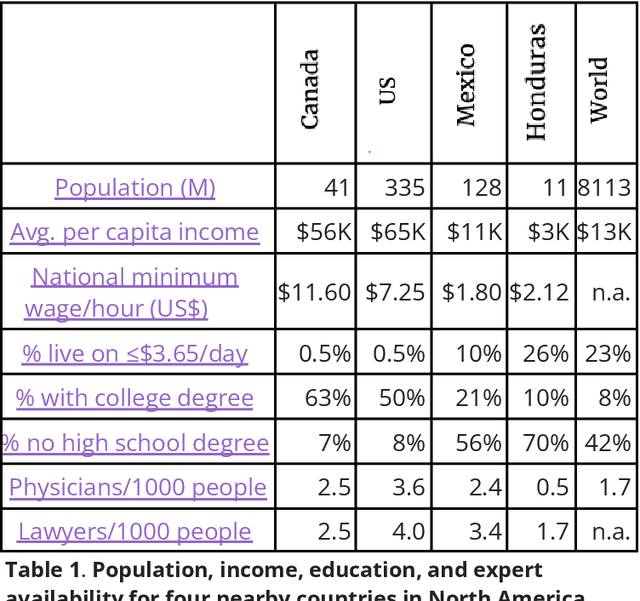
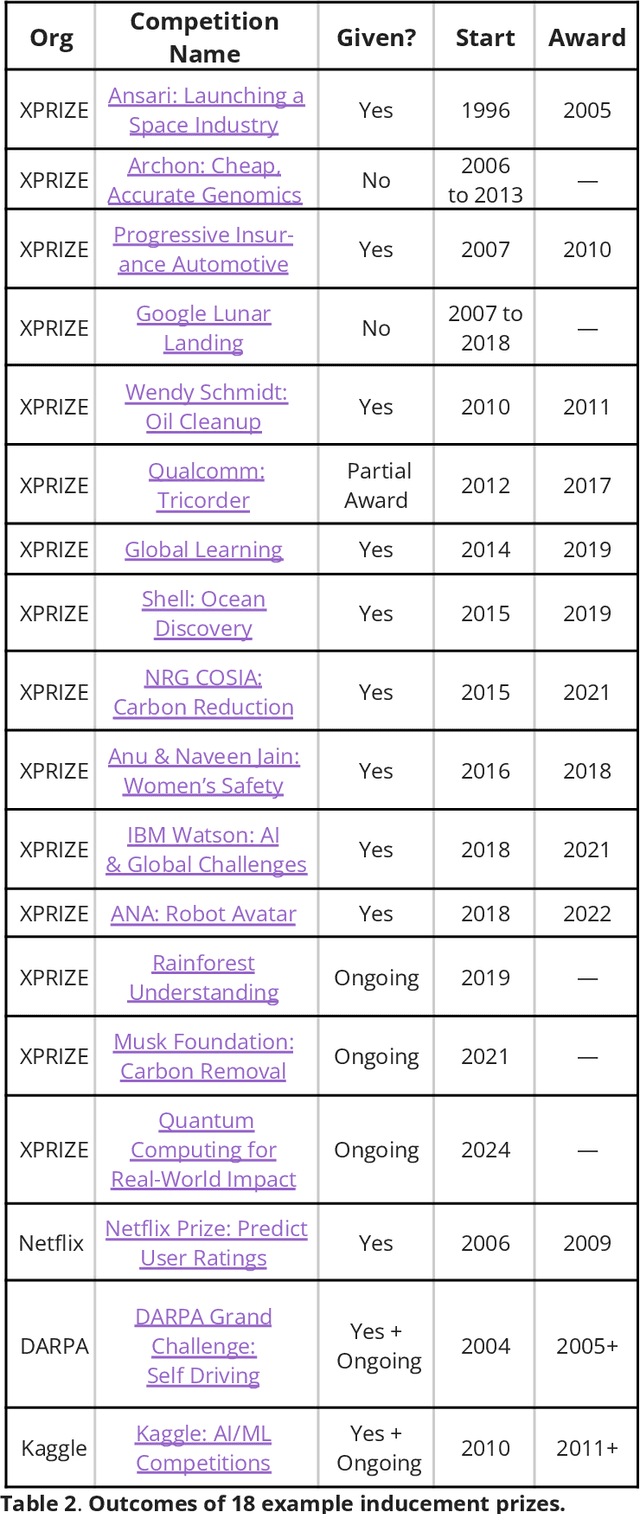
Artificial Intelligence (AI), like any transformative technology, has the potential to be a double-edged sword, leading either toward significant advancements or detrimental outcomes for society as a whole. As is often the case when it comes to widely-used technologies in market economies (e.g., cars and semiconductor chips), commercial interest tends to be the predominant guiding factor. The AI community is at risk of becoming polarized to either take a laissez-faire attitude toward AI development, or to call for government overregulation. Between these two poles we argue for the community of AI practitioners to consciously and proactively work for the common good. This paper offers a blueprint for a new type of innovation infrastructure including 18 concrete milestones to guide AI research in that direction. Our view is that we are still in the early days of practical AI, and focused efforts by practitioners, policymakers, and other stakeholders can still maximize the upsides of AI and minimize its downsides. We talked to luminaries such as recent Nobelist John Jumper on science, President Barack Obama on governance, former UN Ambassador and former National Security Advisor Susan Rice on security, philanthropist Eric Schmidt on several topics, and science fiction novelist Neal Stephenson on entertainment. This ongoing dialogue and collaborative effort has produced a comprehensive, realistic view of what the actual impact of AI could be, from a diverse assembly of thinkers with deep understanding of this technology and these domains. From these exchanges, five recurring guidelines emerged, which form the cornerstone of a framework for beginning to harness AI in service of the public good. They not only guide our efforts in discovery but also shape our approach to deploying this transformative technology responsibly and ethically.