 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Many Features Can a Language Model Store Under the Linear Representation Hypothesis?
Feb 11, 2026We introduce a mathematical framework for the linear representation hypothesis (LRH), which asserts that intermediate layers of language models store features linearly. We separate the hypothesis into two claims: linear representation (features are linearly embedded in neuron activations) and linear accessibility (features can be linearly decoded). We then ask: How many neurons $d$ suffice to both linearly represent and linearly access $m$ features? Classical results in compressed sensing imply that for $k$-sparse inputs, $d = O(k\log (m/k))$ suffices if we allow non-linear decoding algorithms (Candes and Tao, 2006; Candes et al., 2006; Donoho, 2006). However, the additional requirement of linear decoding takes the problem out of the classical compressed sensing, into linear compressed sensing. Our main theoretical result establishes nearly-matching upper and lower bounds for linear compressed sensing. We prove that $d = Ω_ε(\frac{k^2}{\log k}\log (m/k))$ is required while $d = O_ε(k^2\log m)$ suffices. The lower bound establishes a quantitative gap between classical and linear compressed setting, illustrating how linear accessibility is a meaningfully stronger hypothesis than linear representation alone. The upper bound confirms that neurons can store an exponential number of features under the LRH, giving theoretical evidence for the "superposition hypothesis" (Elhage et al., 2022). The upper bound proof uses standard random constructions of matrices with approximately orthogonal columns. The lower bound proof uses rank bounds for near-identity matrices (Alon, 2003) together with Turán's theorem (bounding the number of edges in clique-free graphs). We also show how our results do and do not constrain the geometry of feature representations and extend our results to allow decoders with an activation function and bias.
Correlated Errors in Large Language Models
Jun 09, 2025



Diversity in training data, architecture, and providers is assumed to mitigate homogeneity in LLMs. However, we lack empirical evidence on whether different LLMs differ meaningfully. We conduct a large-scale empirical evaluation on over 350 LLMs overall, using two popular leaderboards and a resume-screening task. We find substantial correlation in model errors -- on one leaderboard dataset, models agree 60% of the time when both models err. We identify factors driving model correlation, including shared architectures and providers. Crucially, however, larger and more accurate models have highly correlated errors, even with distinct architectures and providers. Finally, we show the effects of correlation in two downstream tasks: LLM-as-judge evaluation and hiring -- the latter reflecting theoretical predictions regarding algorithmic monoculture.
Sparse Autoencoders for Hypothesis Generation
Feb 05, 2025



We describe HypotheSAEs, a general method to hypothesize interpretable relationships between text data (e.g., headlines) and a target variable (e.g., clicks). HypotheSAEs has three steps: (1) train a sparse autoencoder on text embeddings to produce interpretable features describing the data distribution, (2) select features that predict the target variable, and (3) generate a natural language interpretation of each feature (e.g., "mentions being surprised or shocked") using an LLM. Each interpretation serves as a hypothesis about what predicts the target variable. Compared to baselines, our method better identifies reference hypotheses on synthetic datasets (at least +0.06 in F1) and produces more predictive hypotheses on real datasets (~twice as many significant findings), despite requiring 1-2 orders of magnitude less compute than recent LLM-based methods. HypotheSAEs also produces novel discoveries on two well-studied tasks: explaining partisan differences in Congressional speeches and identifying drivers of engagement with online headlines.
A No Free Lunch Theorem for Human-AI Collaboration
Nov 21, 2024
The gold standard in human-AI collaboration is complementarity -- when combined performance exceeds both the human and algorithm alone. We investigate this challenge in binary classification settings where the goal is to maximize 0-1 accuracy. Given two or more agents who can make calibrated probabilistic predictions, we show a "No Free Lunch"-style result. Any deterministic collaboration strategy (a function mapping calibrated probabilities into binary classifications) that does not essentially always defer to the same agent will sometimes perform worse than the least accurate agent. In other words, complementarity cannot be achieved "for free." The result does suggest one model of collaboration with guarantees, where one agent identifies "obvious" errors of the other agent. We also use the result to understand the necessary conditions enabling the success of other collaboration techniques, providing guidance to human-AI collaboration.
REFORMS: Reporting Standards for Machine Learning Based Science
Aug 15, 2023
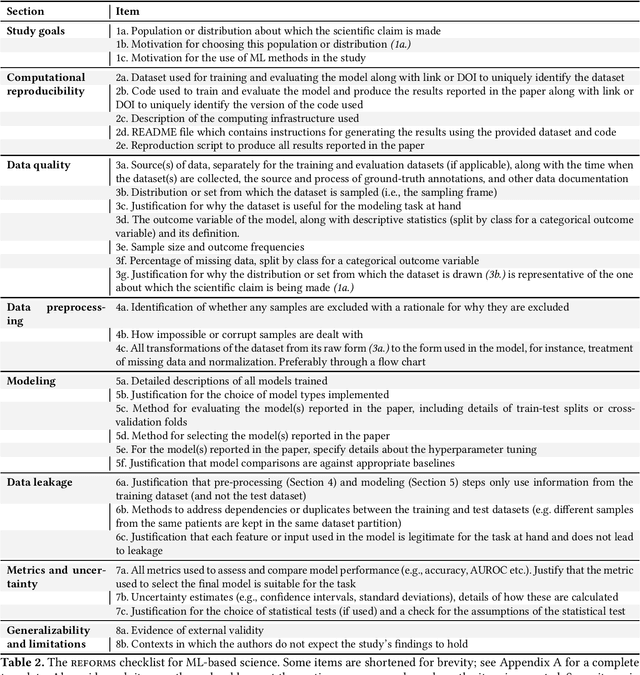
Machine learning (ML) methods are proliferating in scientific research. However, the adoption of these methods has been accompanied by failures of validity, reproducibility, and generalizability. These failures can hinder scientific progress, lead to false consensus around invalid claims, and undermine the credibility of ML-based science. ML methods are often applied and fail in similar ways across disciplines. Motivated by this observation, our goal is to provide clear reporting standards for ML-based science. Drawing from an extensive review of past literature, we present the REFORMS checklist ($\textbf{Re}$porting Standards $\textbf{For}$ $\textbf{M}$achine Learning Based $\textbf{S}$cience). It consists of 32 questions and a paired set of guidelines. REFORMS was developed based on a consensus of 19 researchers across computer science, data science, mathematics, social sciences, and biomedical sciences. REFORMS can serve as a resource for researchers when designing and implementing a study, for referees when reviewing papers, and for journals when enforcing standards for transparency and reproducibility.
Reconciling the accuracy-diversity trade-off in recommendations
Jul 27, 2023
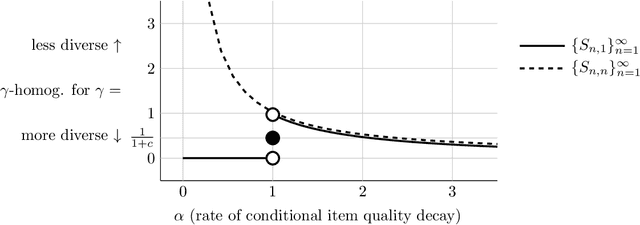
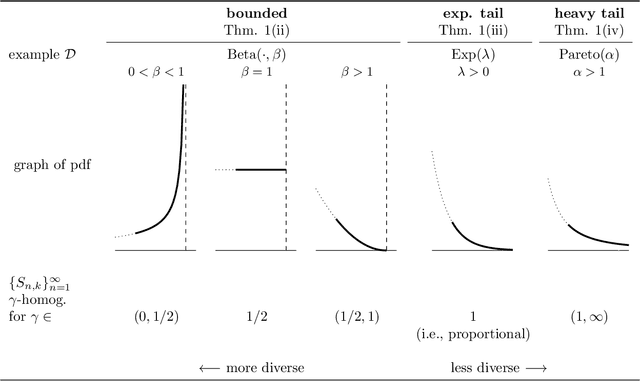
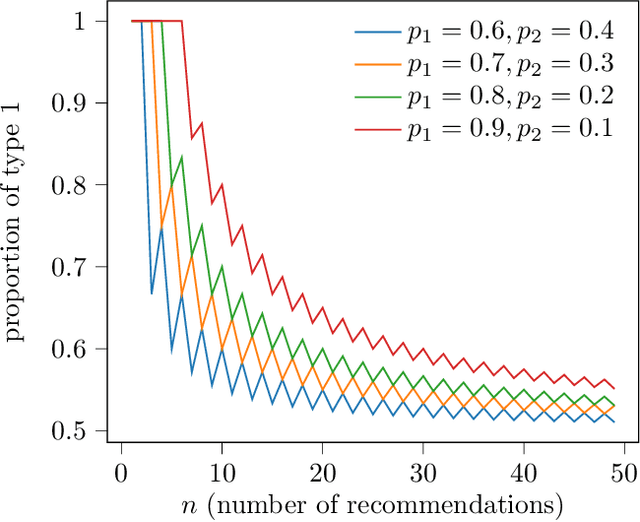
In recommendation settings, there is an apparent trade-off between the goals of accuracy (to recommend items a user is most likely to want) and diversity (to recommend items representing a range of categories). As such, real-world recommender systems often explicitly incorporate diversity separately from accuracy. This approach, however, leaves a basic question unanswered: Why is there a trade-off in the first place? We show how the trade-off can be explained via a user's consumption constraints -- users typically only consume a few of the items they are recommended. In a stylized model we introduce, objectives that account for this constraint induce diverse recommendations, while objectives that do not account for this constraint induce homogeneous recommendations. This suggests that accuracy and diversity appear misaligned because standard accuracy metrics do not consider consumption constraints. Our model yields precise and interpretable characterizations of diversity in different settings, giving practical insights into the design of diverse recommendations.
Large language models shape and are shaped by society: A survey of arXiv publication patterns
Jul 20, 2023There has been a steep recent increase in the number of large language model (LLM) papers, producing a dramatic shift in the scientific landscape which remains largely undocumented through bibliometric analysis. Here, we analyze 388K papers posted on the CS and Stat arXivs, focusing on changes in publication patterns in 2023 vs. 2018-2022. We analyze how the proportion of LLM papers is increasing; the LLM-related topics receiving the most attention; the authors writing LLM papers; how authors' research topics correlate with their backgrounds; the factors distinguishing highly cited LLM papers; and the patterns of international collaboration. We show that LLM research increasingly focuses on societal impacts: there has been an 18x increase in the proportion of LLM-related papers on the Computers and Society sub-arXiv, and authors newly publishing on LLMs are more likely to focus on applications and societal impacts than more experienced authors. LLM research is also shaped by social dynamics: we document gender and academic/industry disparities in the topics LLM authors focus on, and a US/China schism in the collaboration network. Overall, our analysis documents the profound ways in which LLM research both shapes and is shaped by society, attesting to the necessity of sociotechnical lenses.
Mitigating dataset harms requires stewardship: Lessons from 1000 papers
Aug 06, 2021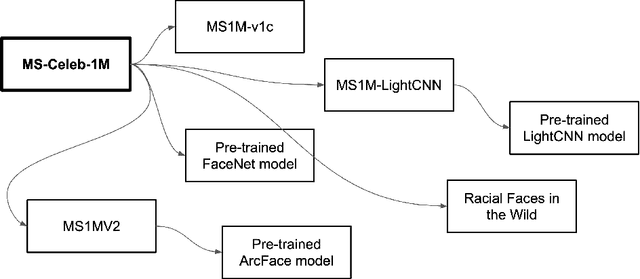


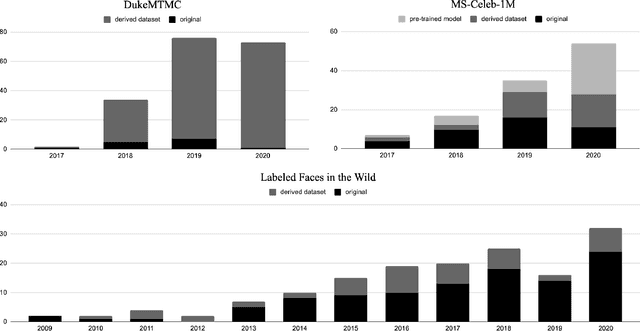
Concerns about privacy, bias, and harmful applications have shone a light on the ethics of machine learning datasets, even leading to the retraction of prominent datasets including DukeMTMC, MS-Celeb-1M, TinyImages, and VGGFace2. In response, the machine learning community has called for higher ethical standards, transparency efforts, and technical fixes in the dataset creation process. The premise of our work is that these efforts can be more effective if informed by an understanding of how datasets are used in practice in the research community. We study three influential face and person recognition datasets - DukeMTMC, MS-Celeb-1M, and Labeled Faces in the Wild (LFW) - by analyzing nearly 1000 papers that cite them. We found that the creation of derivative datasets and models, broader technological and social change, the lack of clarity of licenses, and dataset management practices can introduce a wide range of ethical concerns. We conclude by suggesting a distributed approach that can mitigate these harms, making recommendations to dataset creators, conference program committees, dataset users, and the broader research community.