 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFLARE-AI: Flaw Reporting for AI
Jun 30, 2026Flaw reporting for deployed AI systems is fundamental to identifying system failures and improving AI safety. Yet the AI reporting ecosystem is fragmented: researchers who identify flaws often do not know what or where to report, and groups who receive reports rarely share them with other relevant stakeholders. As a result, good-faith reporters duplicate effort by submitting many different forms, and recipients lack standardized, triage-ready information. We audit 12 reporting systems published by AI developers, cybersecurity groups, and AI flaw aggregators, identifying five recurring design challenges spanning discoverability, scope, information collection, coordination, and guidance for strict-liability cases. Building on this analysis and feedback from 49 experts across 32 organizations representing developers, security researchers, and ecosystem coordinators, we introduce FLARE-AI, an open-source AI flaw reporting system designed for interoperability with existing systems. FLARE-AI streamlines flaw report creation by collecting triage-relevant information through conditional logic and early classification, then enables optional dissemination of standardized, machine-readable reports to multiple developers, coordinators, and incident registries from a single submission. By lowering barriers to reporting AI flaws and improving interoperability across stakeholders, FLARE-AI helps break down silos and accelerate remediation across the AI ecosystem.
Life After Benchmark Saturation: A Case Study of CORE-Bench
Jun 23, 2026When a benchmark's accuracy saturates, it is often retired and replaced with a more challenging version. We show that this approach privileges accuracy and misses the opportunity to study six other key dimensions of agent performance: construct validity issues such as shortcuts, out-of-distribution generalizability, efficiency, reliability, the relative importance of the model versus the scaffold, and uplift from human-agent collaboration. We use CORE-Bench Hard, a benchmark for computational reproducibility of scientific code, as a case study to demonstrate that measuring agents along these dimensions yields meaningful insights into agent performance even after accuracy saturates. First, we surface threats to construct validity in CORE-Bench Hard that are difficult to anticipate with less capable agents. We introduce an improved benchmark, CORE-Bench v1.1, and an out-of-distribution task suite, CORE-Bench OOD. Second, we find that despite accuracy saturation, CORE-Bench v1.1 remains useful for measuring efficiency, reliability, model performance, and scaffold performance. Finally, we conduct a small-scale randomized experiment to measure uplift from human-agent collaboration on real-world computational reproducibility tasks. We find a statistically significant speedup by about a factor of two -- likely underestimated due to one-fifth of human-only reproductions reaching the time limit before completing -- and describe various other findings. Together, our contributions present a more rigorous alternative to the dominant accuracy-centric evaluation paradigm.
Open-World Evaluations for Measuring Frontier AI Capabilities
May 19, 2026Benchmark-based evaluation remains important for tracking frontier AI progress. But it can both overstate and understate deployed capability because it privileges tasks that can be precisely specified, automatically graded, easy to optimize for, and run with low budgets and short time horizons. We advocate for a complementary class of evaluations, which we term open-world evaluations: long-horizon, messy, real-world tasks assessed through small-sample qualitative analysis rather than benchmark-scale automation. In this paper we survey recent open-world evaluations, identify their strengths and limitations, and introduce CRUX (Collaborative Research for Updating AI eXpectations), a project for conducting such evaluations regularly. As a first instance, we task an AI agent with developing and publishing a simple iOS application to the Apple App Store. The agent completed the task with only a single avoidable manual intervention, suggesting that open-world evaluations can provide early warning of capabilities that may soon become widespread. We conclude with recommendations for designing and reporting open-world evals.
Towards a Science of AI Agent Reliability
Feb 18, 2026AI agents are increasingly deployed to execute important tasks. While rising accuracy scores on standard benchmarks suggest rapid progress, many agents still continue to fail in practice. This discrepancy highlights a fundamental limitation of current evaluations: compressing agent behavior into a single success metric obscures critical operational flaws. Notably, it ignores whether agents behave consistently across runs, withstand perturbations, fail predictably, or have bounded error severity. Grounded in safety-critical engineering, we provide a holistic performance profile by proposing twelve concrete metrics that decompose agent reliability along four key dimensions: consistency, robustness, predictability, and safety. Evaluating 14 agentic models across two complementary benchmarks, we find that recent capability gains have only yielded small improvements in reliability. By exposing these persistent limitations, our metrics complement traditional evaluations while offering tools for reasoning about how agents perform, degrade, and fail.
Localized Cultural Knowledge is Conserved and Controllable in Large Language Models
Apr 14, 2025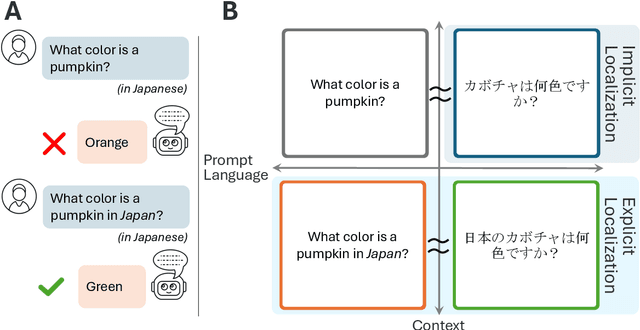

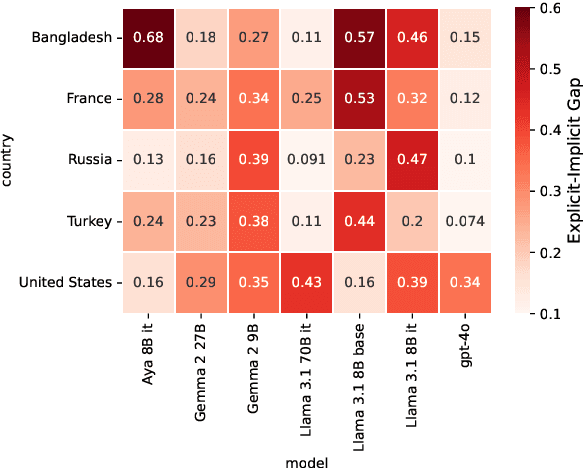
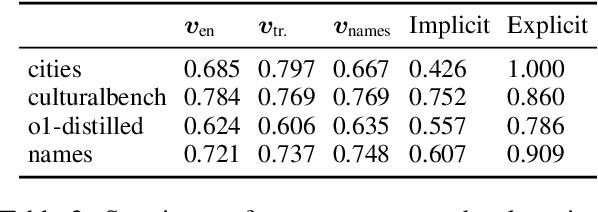
Just as humans display language patterns influenced by their native tongue when speaking new languages, LLMs often default to English-centric responses even when generating in other languages. Nevertheless, we observe that local cultural information persists within the models and can be readily activated for cultural customization. We first demonstrate that explicitly providing cultural context in prompts significantly improves the models' ability to generate culturally localized responses. We term the disparity in model performance with versus without explicit cultural context the explicit-implicit localization gap, indicating that while cultural knowledge exists within LLMs, it may not naturally surface in multilingual interactions if cultural context is not explicitly provided. Despite the explicit prompting benefit, however, the answers reduce in diversity and tend toward stereotypes. Second, we identify an explicit cultural customization vector, conserved across all non-English languages we explore, which enables LLMs to be steered from the synthetic English cultural world-model toward each non-English cultural world. Steered responses retain the diversity of implicit prompting and reduce stereotypes to dramatically improve the potential for customization. We discuss the implications of explicit cultural customization for understanding the conservation of alternative cultural world models within LLMs, and their controllable utility for translation, cultural customization, and the possibility of making the explicit implicit through soft control for expanded LLM function and appeal.
International AI Safety Report
Jan 29, 2025



The first International AI Safety Report comprehensively synthesizes the current evidence on the capabilities, risks, and safety of advanced AI systems. The report was mandated by the nations attending the AI Safety Summit in Bletchley, UK. Thirty nations, the UN, the OECD, and the EU each nominated a representative to the report's Expert Advisory Panel. A total of 100 AI experts contributed, representing diverse perspectives and disciplines. Led by the report's Chair, these independent experts collectively had full discretion over the report's content.
Inference Scaling fLaws: The Limits of LLM Resampling with Imperfect Verifiers
Dec 02, 2024



Recent research has generated hope that inference scaling could allow weaker language models to match or exceed the accuracy of stronger models, such as by repeatedly sampling solutions to a coding problem until it passes unit tests. The central thesis of this paper is that there is no free lunch for inference scaling: indefinite accuracy improvement through resampling can only be realized if the "verifier" (in this case, a set of unit tests) is perfect. When the verifier is imperfect, as it almost always is in domains such as reasoning or coding (for example, unit tests have imperfect coverage), there is a nonzero probability of false positives: incorrect solutions that pass the verifier. Resampling cannot decrease this probability, so it imposes an upper bound to the accuracy of resampling-based inference scaling even with an infinite compute budget. We find that there is a very strong correlation between the model's single-sample accuracy (i.e. accuracy without unit tests) and its false positive rate on coding benchmarks HumanEval and MBPP, whose unit tests have limited coverage. Therefore, no amount of inference scaling of weaker models can enable them to match the single-sample accuracy of a sufficiently strong model (Fig. 1a). When we consider that false positives have a negative utility compared to abstaining from producing a solution, it bends the inference scaling curve further downward. Empirically, we find that the optimal number of samples can be less than 10 under realistic assumptions (Fig. 1b). Finally, we show that beyond accuracy, false positives may have other undesirable qualities, such as poor adherence to coding style conventions.
Inference Scaling $\scriptsize\mathtt{F}$Laws: The Limits of LLM Resampling with Imperfect Verifiers
Nov 26, 2024Recent research has generated hope that inference scaling could allow weaker language models to match or exceed the accuracy of stronger models, such as by repeatedly sampling solutions to a coding problem until it passes unit tests. The central thesis of this paper is that there is no free lunch for inference scaling: indefinite accuracy improvement through resampling can only be realized if the "verifier" (in this case, a set of unit tests) is perfect. When the verifier is imperfect, as it almost always is in domains such as reasoning or coding (for example, unit tests have imperfect coverage), there is a nonzero probability of false positives: incorrect solutions that pass the verifier. Resampling cannot decrease this probability, so it imposes an upper bound to the accuracy of resampling-based inference scaling even with an infinite compute budget. We find that there is a very strong correlation between the model's single-sample accuracy (i.e. accuracy without unit tests) and its false positive rate on coding benchmarks HumanEval and MBPP, whose unit tests have limited coverage. Therefore, no amount of inference scaling of weaker models can enable them to match the single-sample accuracy of a sufficiently strong model (Fig. 1a). When we consider that false positives have a negative utility compared to abstaining from producing a solution, it bends the inference scaling curve further downward. Empirically, we find that the optimal number of samples can be less than 10 under realistic assumptions (Fig. 1b). Finally, we show that beyond accuracy, false positives may have other undesirable qualities, such as poor adherence to coding style conventions.
CORE-Bench: Fostering the Credibility of Published Research Through a Computational Reproducibility Agent Benchmark
Sep 17, 2024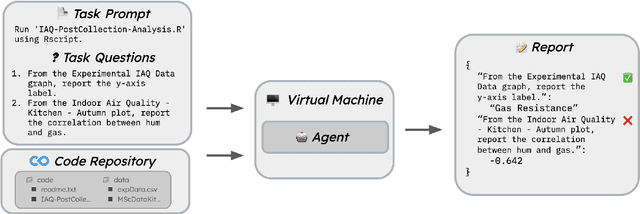
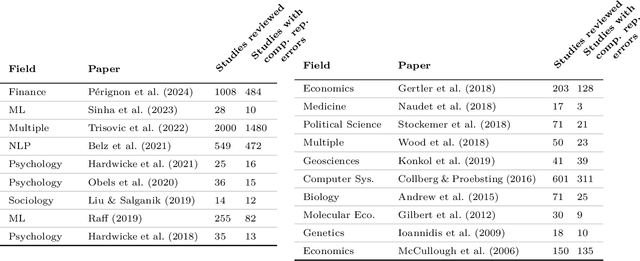

AI agents have the potential to aid users on a variety of consequential tasks, including conducting scientific research. To spur the development of useful agents, we need benchmarks that are challenging, but more crucially, directly correspond to real-world tasks of interest. This paper introduces such a benchmark, designed to measure the accuracy of AI agents in tackling a crucial yet surprisingly challenging aspect of scientific research: computational reproducibility. This task, fundamental to the scientific process, involves reproducing the results of a study using the provided code and data. We introduce CORE-Bench (Computational Reproducibility Agent Benchmark), a benchmark consisting of 270 tasks based on 90 scientific papers across three disciplines (computer science, social science, and medicine). Tasks in CORE-Bench consist of three difficulty levels and include both language-only and vision-language tasks. We provide an evaluation system to measure the accuracy of agents in a fast and parallelizable way, saving days of evaluation time for each run compared to a sequential implementation. We evaluated two baseline agents: the general-purpose AutoGPT and a task-specific agent called CORE-Agent. We tested both variants using two underlying language models: GPT-4o and GPT-4o-mini. The best agent achieved an accuracy of 21% on the hardest task, showing the vast scope for improvement in automating routine scientific tasks. Having agents that can reproduce existing work is a necessary step towards building agents that can conduct novel research and could verify and improve the performance of other research agents. We hope that CORE-Bench can improve the state of reproducibility and spur the development of future research agents.
AI Agents That Matter
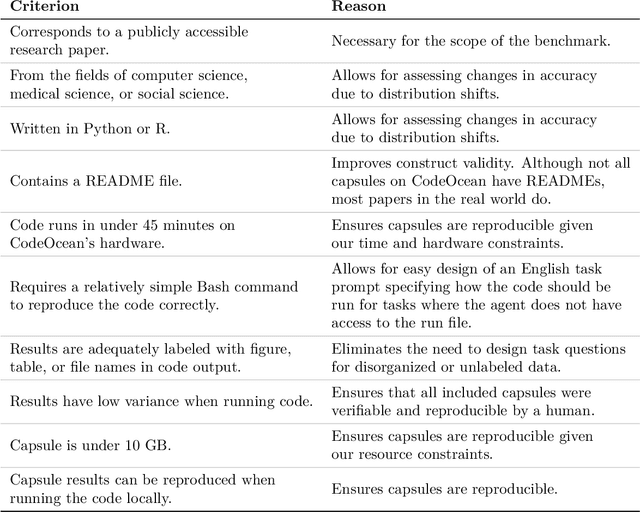
Jul 01, 2024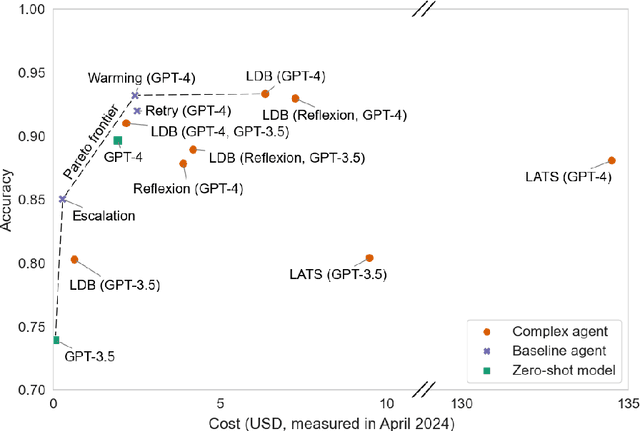

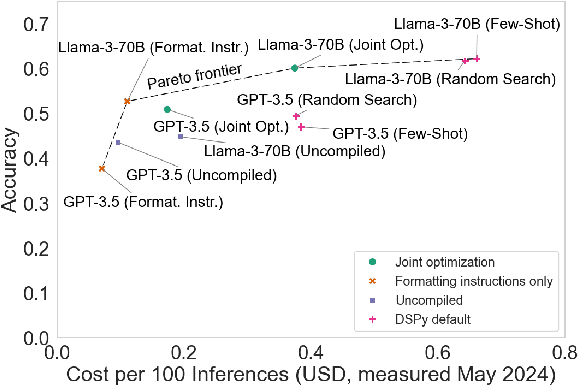
AI agents are an exciting new research direction, and agent development is driven by benchmarks. Our analysis of current agent benchmarks and evaluation practices reveals several shortcomings that hinder their usefulness in real-world applications. First, there is a narrow focus on accuracy without attention to other metrics. As a result, SOTA agents are needlessly complex and costly, and the community has reached mistaken conclusions about the sources of accuracy gains. Our focus on cost in addition to accuracy motivates the new goal of jointly optimizing the two metrics. We design and implement one such optimization, showing its potential to greatly reduce cost while maintaining accuracy. Second, the benchmarking needs of model and downstream developers have been conflated, making it hard to identify which agent would be best suited for a particular application. Third, many agent benchmarks have inadequate holdout sets, and sometimes none at all. This has led to agents that are fragile because they take shortcuts and overfit to the benchmark in various ways. We prescribe a principled framework for avoiding overfitting. Finally, there is a lack of standardization in evaluation practices, leading to a pervasive lack of reproducibility. We hope that the steps we introduce for addressing these shortcomings will spur the development of agents that are useful in the real world and not just accurate on benchmarks.