 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmnilingual ASR: Open-Source Multilingual Speech Recognition for 1600+ Languages
Nov 12, 2025



Automatic speech recognition (ASR) has advanced in high-resource languages, but most of the world's 7,000+ languages remain unsupported, leaving thousands of long-tail languages behind. Expanding ASR coverage has been costly and limited by architectures that restrict language support, making extension inaccessible to most--all while entangled with ethical concerns when pursued without community collaboration. To transcend these limitations, we introduce Omnilingual ASR, the first large-scale ASR system designed for extensibility. Omnilingual ASR enables communities to introduce unserved languages with only a handful of data samples. It scales self-supervised pre-training to 7B parameters to learn robust speech representations and introduces an encoder-decoder architecture designed for zero-shot generalization, leveraging a LLM-inspired decoder. This capability is grounded in a massive and diverse training corpus; by combining breadth of coverage with linguistic variety, the model learns representations robust enough to adapt to unseen languages. Incorporating public resources with community-sourced recordings gathered through compensated local partnerships, Omnilingual ASR expands coverage to over 1,600 languages, the largest such effort to date--including over 500 never before served by ASR. Automatic evaluations show substantial gains over prior systems, especially in low-resource conditions, and strong generalization. We release Omnilingual ASR as a family of models, from 300M variants for low-power devices to 7B for maximum accuracy. We reflect on the ethical considerations shaping this design and conclude by discussing its societal impact. In particular, we highlight how open-sourcing models and tools can lower barriers for researchers and communities, inviting new forms of participation. Open-source artifacts are available at https://github.com/facebookresearch/omnilingual-asr.
Can We Predict Alignment Before Models Finish Thinking? Towards Monitoring Misaligned Reasoning Models
Jul 16, 2025Open-weights reasoning language models generate long chains-of-thought (CoTs) before producing a final response, which improves performance but introduces additional alignment risks, with harmful content often appearing in both the CoTs and the final outputs. In this work, we investigate if we can use CoTs to predict final response misalignment. We evaluate a range of monitoring approaches, including humans, highly-capable large language models, and text classifiers, using either CoT text or activations. First, we find that a simple linear probe trained on CoT activations can significantly outperform all text-based methods in predicting whether a final response will be safe or unsafe. CoT texts are often unfaithful and can mislead humans and classifiers, while model latents (i.e., CoT activations) offer a more reliable predictive signal. Second, the probe makes accurate predictions before reasoning completes, achieving strong performance even when applied to early CoT segments. These findings generalize across model sizes, families, and safety benchmarks, suggesting that lightweight probes could enable real-time safety monitoring and early intervention during generation.
Effects of Speaker Count, Duration, and Accent Diversity on Zero-Shot Accent Robustness in Low-Resource ASR
Jun 04, 2025To build an automatic speech recognition (ASR) system that can serve everyone in the world, the ASR needs to be robust to a wide range of accents including unseen accents. We systematically study how three different variables in training data -- the number of speakers, the audio duration per each individual speaker, and the diversity of accents -- affect ASR robustness towards unseen accents in a low-resource training regime. We observe that for a fixed number of ASR training hours, it is more beneficial to increase the number of speakers (which means each speaker contributes less) than the number of hours contributed per speaker. We also observe that more speakers enables ASR performance gains from scaling number of hours. Surprisingly, we observe minimal benefits to prioritizing speakers with different accents when the number of speakers is controlled. Our work suggests that practitioners should prioritize increasing the speaker count in ASR training data composition for new languages.
The State of Multilingual LLM Safety Research: From Measuring the Language Gap to Mitigating It
May 30, 2025This paper presents a comprehensive analysis of the linguistic diversity of LLM safety research, highlighting the English-centric nature of the field. Through a systematic review of nearly 300 publications from 2020--2024 across major NLP conferences and workshops at *ACL, we identify a significant and growing language gap in LLM safety research, with even high-resource non-English languages receiving minimal attention. We further observe that non-English languages are rarely studied as a standalone language and that English safety research exhibits poor language documentation practice. To motivate future research into multilingual safety, we make several recommendations based on our survey, and we then pose three concrete future directions on safety evaluation, training data generation, and crosslingual safety generalization. Based on our survey and proposed directions, the field can develop more robust, inclusive AI safety practices for diverse global populations.
Improving LLM First-Token Predictions in Multiple-Choice Question Answering via Prefilling Attack
May 21, 2025Large Language Models (LLMs) are increasingly evaluated on multiple-choice question answering (MCQA) tasks using *first-token probability* (FTP), which selects the answer option whose initial token has the highest likelihood. While efficient, FTP can be fragile: models may assign high probability to unrelated tokens (*misalignment*) or use a valid token merely as part of a generic preamble rather than as a clear answer choice (*misinterpretation*), undermining the reliability of symbolic evaluation. We propose a simple solution: the *prefilling attack*, a structured natural-language prefix (e.g., "*The correct option is:*") prepended to the model output. Originally explored in AI safety, we repurpose prefilling to steer the model to respond with a clean, valid option, without modifying its parameters. Empirically, the FTP with prefilling strategy substantially improves accuracy, calibration, and output consistency across a broad set of LLMs and MCQA benchmarks. It outperforms standard FTP and often matches the performance of open-ended generation approaches that require full decoding and external classifiers, while being significantly more efficient. Our findings suggest that prefilling is a simple, robust, and low-cost method to enhance the reliability of FTP-based evaluation in multiple-choice settings.
Crosslingual Reasoning through Test-Time Scaling
May 08, 2025Reasoning capabilities of large language models are primarily studied for English, even when pretrained models are multilingual. In this work, we investigate to what extent English reasoning finetuning with long chain-of-thoughts (CoTs) can generalize across languages. First, we find that scaling up inference compute for English-centric reasoning language models (RLMs) improves multilingual mathematical reasoning across many languages including low-resource languages, to an extent where they outperform models twice their size. Second, we reveal that while English-centric RLM's CoTs are naturally predominantly English, they consistently follow a quote-and-think pattern to reason about quoted non-English inputs. Third, we discover an effective strategy to control the language of long CoT reasoning, and we observe that models reason better and more efficiently in high-resource languages. Finally, we observe poor out-of-domain reasoning generalization, in particular from STEM to cultural commonsense knowledge, even for English. Overall, we demonstrate the potentials, study the mechanisms and outline the limitations of crosslingual generalization of English reasoning test-time scaling. We conclude that practitioners should let English-centric RLMs reason in high-resource languages, while further work is needed to improve reasoning in low-resource languages and out-of-domain contexts.
Sailor2: Sailing in South-East Asia with Inclusive Multilingual LLMs
Feb 18, 2025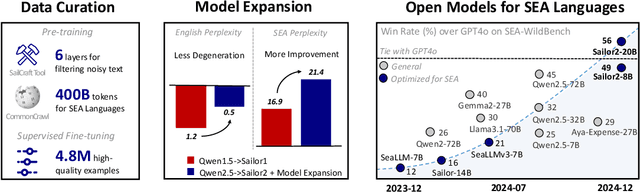

Sailor2 is a family of cutting-edge multilingual language models for South-East Asian (SEA) languages, available in 1B, 8B, and 20B sizes to suit diverse applications. Building on Qwen2.5, Sailor2 undergoes continuous pre-training on 500B tokens (400B SEA-specific and 100B replay tokens) to support 13 SEA languages while retaining proficiency in Chinese and English. Sailor2-20B model achieves a 50-50 win rate against GPT-4o across SEA languages. We also deliver a comprehensive cookbook on how to develop the multilingual model in an efficient manner, including five key aspects: data curation, pre-training, post-training, model customization and evaluation. We hope that Sailor2 model (Apache 2.0 license) will drive language development in the SEA region, and Sailor2 cookbook will inspire researchers to build more inclusive LLMs for other under-served languages.
Humanity's Last Exam
Jan 24, 2025Benchmarks are important tools for tracking the rapid advancements in large language model (LLM) capabilities. However, benchmarks are not keeping pace in difficulty: LLMs now achieve over 90\% accuracy on popular benchmarks like MMLU, limiting informed measurement of state-of-the-art LLM capabilities. In response, we introduce Humanity's Last Exam (HLE), a multi-modal benchmark at the frontier of human knowledge, designed to be the final closed-ended academic benchmark of its kind with broad subject coverage. HLE consists of 3,000 questions across dozens of subjects, including mathematics, humanities, and the natural sciences. HLE is developed globally by subject-matter experts and consists of multiple-choice and short-answer questions suitable for automated grading. Each question has a known solution that is unambiguous and easily verifiable, but cannot be quickly answered via internet retrieval. State-of-the-art LLMs demonstrate low accuracy and calibration on HLE, highlighting a significant gap between current LLM capabilities and the expert human frontier on closed-ended academic questions. To inform research and policymaking upon a clear understanding of model capabilities, we publicly release HLE at https://lastexam.ai.
Towards Understanding the Fragility of Multilingual LLMs against Fine-Tuning Attacks
Oct 23, 2024Recent advancements in Large Language Models (LLMs) have sparked widespread concerns about their safety. Recent work demonstrates that safety alignment of LLMs can be easily removed by fine-tuning with a few adversarially chosen instruction-following examples, i.e., fine-tuning attacks. We take a further step to understand fine-tuning attacks in multilingual LLMs. We first discover cross-lingual generalization of fine-tuning attacks: using a few adversarially chosen instruction-following examples in one language, multilingual LLMs can also be easily compromised (e.g., multilingual LLMs fail to refuse harmful prompts in other languages). Motivated by this finding, we hypothesize that safety-related information is language-agnostic and propose a new method termed Safety Information Localization (SIL) to identify the safety-related information in the model parameter space. Through SIL, we validate this hypothesis and find that only changing 20% of weight parameters in fine-tuning attacks can break safety alignment across all languages. Furthermore, we provide evidence to the alternative pathways hypothesis for why freezing safety-related parameters does not prevent fine-tuning attacks, and we demonstrate that our attack vector can still jailbreak LLMs adapted to new languages.
Preference Tuning For Toxicity Mitigation Generalizes Across Languages
Jun 23, 2024



Detoxifying multilingual Large Language Models (LLMs) has become crucial due to their increasing global use. In this work, we explore zero-shot cross-lingual generalization of preference tuning in detoxifying LLMs. Unlike previous studies that show limited cross-lingual generalization for other safety tasks, we demonstrate that Direct Preference Optimization (DPO) training with only English data can significantly reduce toxicity in multilingual open-ended generations. For example, the probability of mGPT-1.3B generating toxic continuations drops from 46.8% to 3.9% across 17 different languages after training. Our results also extend to other multilingual LLMs, such as BLOOM, Llama3, and Aya-23. Using mechanistic interpretability tools like causal intervention and activation analysis, we identified the dual multilinguality property of MLP layers in LLMs, which explains the cross-lingual generalization of DPO. Finally, we show that bilingual sentence retrieval can predict the cross-lingual transferability of DPO preference tuning.