 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Sequential Distance: Inter-Modal Distance Invariant Position Encoding
Mar 11, 2026Despite the remarkable capabilities of Multimodal Large Language Models (MLLMs), they still suffer from visual fading in long-context scenarios. Specifically, the attention to visual tokens diminishes as the text sequence lengthens, leading to text generation detached from visual constraints. We attribute this degradation to the inherent inductive bias of Multimodal RoPE, which penalizes inter-modal attention as the distance between visual and text tokens increases. To address this, we propose inter-modal Distance Invariant Position Encoding (DIPE), a simple but effective mechanism that disentangles position encoding based on modality interactions. DIPE retains the natural relative positioning for intra-modal interactions to preserve local structure, while enforcing an anchored perceptual proximity for inter-modal interactions. This strategy effectively mitigates the inter-modal distance-based penalty, ensuring that visual signals remain perceptually consistent regardless of the context length. Experimental results demonstrate that by integrating DIPE with Multimodal RoPE, the model maintains stable visual grounding in long-context scenarios, significantly alleviating visual fading while preserving performance on standard short-context benchmarks. Code is available at https://github.com/lchen1019/DIPE.
Step 3.5 Flash: Open Frontier-Level Intelligence with 11B Active Parameters
Feb 11, 2026We introduce Step 3.5 Flash, a sparse Mixture-of-Experts (MoE) model that bridges frontier-level agentic intelligence and computational efficiency. We focus on what matters most when building agents: sharp reasoning and fast, reliable execution. Step 3.5 Flash pairs a 196B-parameter foundation with 11B active parameters for efficient inference. It is optimized with interleaved 3:1 sliding-window/full attention and Multi-Token Prediction (MTP-3) to reduce the latency and cost of multi-round agentic interactions. To reach frontier-level intelligence, we design a scalable reinforcement learning framework that combines verifiable signals with preference feedback, while remaining stable under large-scale off-policy training, enabling consistent self-improvement across mathematics, code, and tool use. Step 3.5 Flash demonstrates strong performance across agent, coding, and math tasks, achieving 85.4% on IMO-AnswerBench, 86.4% on LiveCodeBench-v6 (2024.08-2025.05), 88.2% on tau2-Bench, 69.0% on BrowseComp (with context management), and 51.0% on Terminal-Bench 2.0, comparable to frontier models such as GPT-5.2 xHigh and Gemini 3.0 Pro. By redefining the efficiency frontier, Step 3.5 Flash provides a high-density foundation for deploying sophisticated agents in real-world industrial environments.
Beyond Next-Token Alignment: Distilling Multimodal Large Language Models via Token Interactions
Feb 10, 2026Multimodal Large Language Models (MLLMs) demonstrate impressive cross-modal capabilities, yet their substantial size poses significant deployment challenges. Knowledge distillation (KD) is a promising solution for compressing these models, but existing methods primarily rely on static next-token alignment, neglecting the dynamic token interactions, which embed essential capabilities for multimodal understanding and generation. To this end, we introduce Align-TI, a novel KD framework designed from the perspective of Token Interactions. Our approach is motivated by the insight that MLLMs rely on two primary interactions: vision-instruction token interactions to extract relevant visual information, and intra-response token interactions for coherent generation. Accordingly, Align-TI introduces two components: IVA enables the student model to imitate the teacher's instruction-relevant visual information extract capability by aligning on salient visual regions. TPA captures the teacher's dynamic generative logic by aligning the sequential token-to-token transition probabilities. Extensive experiments demonstrate Align-TI's superiority. Notably, our approach achieves $2.6\%$ relative improvement over Vanilla KD, and our distilled Align-TI-2B even outperforms LLaVA-1.5-7B (a much larger MLLM) by $7.0\%$, establishing a new state-of-the-art distillation framework for training parameter-efficient MLLMs. Code is available at https://github.com/lchen1019/Align-TI.
CodeSimpleQA: Scaling Factuality in Code Large Language Models
Dec 22, 2025Large language models (LLMs) have made significant strides in code generation, achieving impressive capabilities in synthesizing code snippets from natural language instructions. However, a critical challenge remains in ensuring LLMs generate factually accurate responses about programming concepts, technical implementations, etc. Most previous code-related benchmarks focus on code execution correctness, overlooking the factual accuracy of programming knowledge. To address this gap, we present CodeSimpleQA, a comprehensive bilingual benchmark designed to evaluate the factual accuracy of code LLMs in answering code-related questions, which contains carefully curated question-answer pairs in both English and Chinese, covering diverse programming languages and major computer science domains. Further, we create CodeSimpleQA-Instruct, a large-scale instruction corpus with 66M samples, and develop a post-training framework combining supervised fine-tuning and reinforcement learning. Our comprehensive evaluation of diverse LLMs reveals that even frontier LLMs struggle with code factuality. Our proposed framework demonstrates substantial improvements over the base model, underscoring the critical importance of factuality-aware alignment in developing reliable code LLMs.
MVU-Eval: Towards Multi-Video Understanding Evaluation for Multimodal LLMs
Nov 13, 2025
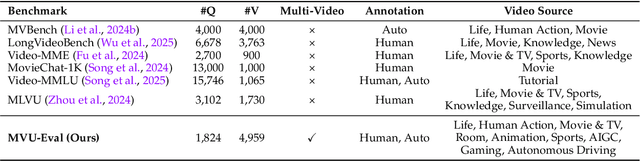
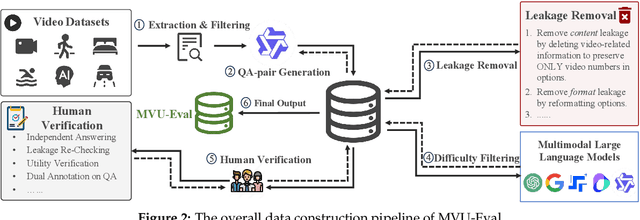

The advent of Multimodal Large Language Models (MLLMs) has expanded AI capabilities to visual modalities, yet existing evaluation benchmarks remain limited to single-video understanding, overlooking the critical need for multi-video understanding in real-world scenarios (e.g., sports analytics and autonomous driving). To address this significant gap, we introduce MVU-Eval, the first comprehensive benchmark for evaluating Multi-Video Understanding for MLLMs. Specifically, our MVU-Eval mainly assesses eight core competencies through 1,824 meticulously curated question-answer pairs spanning 4,959 videos from diverse domains, addressing both fundamental perception tasks and high-order reasoning tasks. These capabilities are rigorously aligned with real-world applications such as multi-sensor synthesis in autonomous systems and cross-angle sports analytics. Through extensive evaluation of state-of-the-art open-source and closed-source models, we reveal significant performance discrepancies and limitations in current MLLMs' ability to perform understanding across multiple videos. The benchmark will be made publicly available to foster future research.
Neurosymbolic Feature Extraction for Identifying Forced Labor in Supply Chains
Jul 09, 2025Supply chain networks are complex systems that are challenging to analyze; this problem is exacerbated when there are illicit activities involved in the supply chain, such as counterfeit parts, forced labor, or human trafficking. While machine learning (ML) can find patterns in complex systems like supply chains, traditional ML techniques require large training data sets. However, illicit supply chains are characterized by very sparse data, and the data that is available is often (purposely) corrupted or unreliable in order to hide the nature of the activities. We need to be able to automatically detect new patterns that correlate with such illegal activity over complex, even temporal data, without requiring large training data sets. We explore neurosymbolic methods for identifying instances of illicit activity in supply chains and compare the effectiveness of manual and automated feature extraction from news articles accurately describing illicit activities uncovered by authorities. We propose a question tree approach for querying a large language model (LLM) to identify and quantify the relevance of articles. This enables a systematic evaluation of the differences between human and machine classification of news articles related to forced labor in supply chains.
Blending Supervised and Reinforcement Fine-Tuning with Prefix Sampling
Jul 02, 2025Existing post-training techniques for large language models are broadly categorized into Supervised Fine-Tuning (SFT) and Reinforcement Fine-Tuning (RFT). Each paradigm presents a distinct trade-off: SFT excels at mimicking demonstration data but can lead to problematic generalization as a form of behavior cloning. Conversely, RFT can significantly enhance a model's performance but is prone to learn unexpected behaviors, and its performance is highly sensitive to the initial policy. In this paper, we propose a unified view of these methods and introduce Prefix-RFT, a hybrid approach that synergizes learning from both demonstration and exploration. Using mathematical reasoning problems as a testbed, we empirically demonstrate that Prefix-RFT is both simple and effective. It not only surpasses the performance of standalone SFT and RFT but also outperforms parallel mixed-policy RFT methods. A key advantage is its seamless integration into existing open-source frameworks, requiring only minimal modifications to the standard RFT pipeline. Our analysis highlights the complementary nature of SFT and RFT, and validates that Prefix-RFT effectively harmonizes these two learning paradigms. Furthermore, ablation studies confirm the method's robustness to variations in the quality and quantity of demonstration data. We hope this work offers a new perspective on LLM post-training, suggesting that a unified paradigm that judiciously integrates demonstration and exploration could be a promising direction for future research.
Can Mixture-of-Experts Surpass Dense LLMs Under Strictly Equal Resources?
Jun 13, 2025Mixture-of-Experts (MoE) language models dramatically expand model capacity and achieve remarkable performance without increasing per-token compute. However, can MoEs surpass dense architectures under strictly equal resource constraints - that is, when the total parameter count, training compute, and data budget are identical? This question remains under-explored despite its significant practical value and potential. In this paper, we propose a novel perspective and methodological framework to study this question thoroughly. First, we comprehensively investigate the architecture of MoEs and achieve an optimal model design that maximizes the performance. Based on this, we subsequently find that an MoE model with activation rate in an optimal region is able to outperform its dense counterpart under the same total parameter, training compute and data resource. More importantly, this optimal region remains consistent across different model sizes. Although additional amount of data turns out to be a trade-off for the enhanced performance, we show that this can be resolved via reusing data. We validate our findings through extensive experiments, training nearly 200 language models at 2B scale and over 50 at 7B scale, cumulatively processing 50 trillion tokens. All models will be released publicly.
Farseer: A Refined Scaling Law in Large Language Models
Jun 12, 2025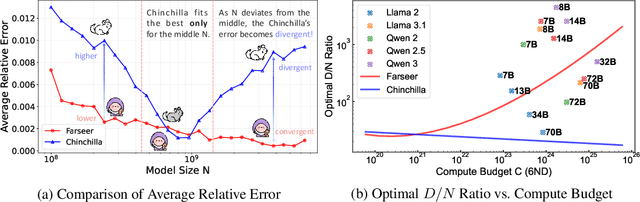
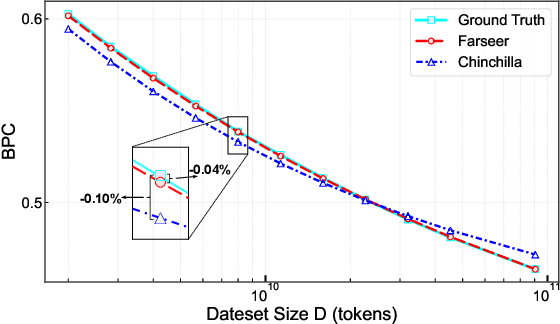

Training Large Language Models (LLMs) is prohibitively expensive, creating a critical scaling gap where insights from small-scale experiments often fail to transfer to resource-intensive production systems, thereby hindering efficient innovation. To bridge this, we introduce Farseer, a novel and refined scaling law offering enhanced predictive accuracy across scales. By systematically constructing a model loss surface $L(N,D)$, Farseer achieves a significantly better fit to empirical data than prior laws (e.g., Chinchilla's law). Our methodology yields accurate, robust, and highly generalizable predictions, demonstrating excellent extrapolation capabilities, improving upon Chinchilla's law by reducing extrapolation error by 433\%. This allows for the reliable evaluation of competing training strategies across all $(N,D)$ settings, enabling conclusions from small-scale ablation studies to be confidently extrapolated to predict large-scale performance. Furthermore, Farseer provides new insights into optimal compute allocation, better reflecting the nuanced demands of modern LLM training. To validate our approach, we trained an extensive suite of approximately 1,000 LLMs across diverse scales and configurations, consuming roughly 3 million NVIDIA H100 GPU hours. We are comprehensively open-sourcing all models, data, results, and logs at https://github.com/Farseer-Scaling-Law/Farseer to foster further research.
Faster and Better LLMs via Latency-Aware Test-Time Scaling
May 26, 2025Test-Time Scaling (TTS) has proven effective in improving the performance of Large Language Models (LLMs) during inference. However, existing research has overlooked the efficiency of TTS from a latency-sensitive perspective. Through a latency-aware evaluation of representative TTS methods, we demonstrate that a compute-optimal TTS does not always result in the lowest latency in scenarios where latency is critical. To address this gap and achieve latency-optimal TTS, we propose two key approaches by optimizing the concurrency configurations: (1) branch-wise parallelism, which leverages multiple concurrent inference branches, and (2) sequence-wise parallelism, enabled by speculative decoding. By integrating these two approaches and allocating computational resources properly to each, our latency-optimal TTS enables a 32B model to reach 82.3% accuracy on MATH-500 within 1 minute and a smaller 3B model to achieve 72.4% within 10 seconds. Our work emphasizes the importance of latency-aware TTS and demonstrates its ability to deliver both speed and accuracy in latency-sensitive scenarios.