 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Efficient Additive Kolmogorov-Arnold Transformer for Point-Level Maize Localization in Unmanned Aerial Vehicle Imagery
Jan 12, 2026High-resolution UAV photogrammetry has become a key technology for precision agriculture, enabling centimeter-level crop monitoring and point-level plant localization. However, point-level maize localization in UAV imagery remains challenging due to (1) extremely small object-to-pixel ratios, typically less than 0.1%, (2) prohibitive computational costs of quadratic attention on ultra-high-resolution images larger than 3000 x 4000 pixels, and (3) agricultural scene-specific complexities such as sparse object distribution and environmental variability that are poorly handled by general-purpose vision models. To address these challenges, we propose the Additive Kolmogorov-Arnold Transformer (AKT), which replaces conventional multilayer perceptrons with Pade Kolmogorov-Arnold Network (PKAN) modules to enhance functional expressivity for small-object feature extraction, and introduces PKAN Additive Attention (PAA) to model multiscale spatial dependencies with reduced computational complexity. In addition, we present the Point-based Maize Localization (PML) dataset, consisting of 1,928 high-resolution UAV images with approximately 501,000 point annotations collected under real field conditions. Extensive experiments show that AKT achieves an average F1-score of 62.8%, outperforming state-of-the-art methods by 4.2%, while reducing FLOPs by 12.6% and improving inference throughput by 20.7%. For downstream tasks, AKT attains a mean absolute error of 7.1 in stand counting and a root mean square error of 1.95-1.97 cm in interplant spacing estimation. These results demonstrate that integrating Kolmogorov-Arnold representation theory with efficient attention mechanisms offers an effective framework for high-resolution agricultural remote sensing.
VSA:Visual-Structural Alignment for UI-to-Code
Dec 23, 2025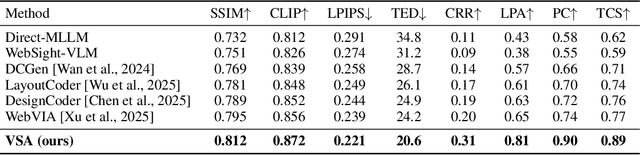
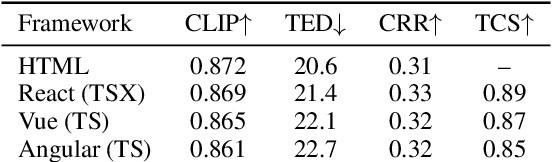
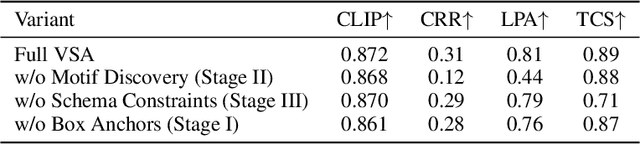
The automation of user interface development has the potential to accelerate software delivery by mitigating intensive manual implementation. Despite the advancements in Large Multimodal Models for design-to-code translation, existing methodologies predominantly yield unstructured, flat codebases that lack compatibility with component-oriented libraries such as React or Angular. Such outputs typically exhibit low cohesion and high coupling, complicating long-term maintenance. In this paper, we propose \textbf{VSA (VSA)}, a multi-stage paradigm designed to synthesize organized frontend assets through visual-structural alignment. Our approach first employs a spatial-aware transformer to reconstruct the visual input into a hierarchical tree representation. Moving beyond basic layout extraction, we integrate an algorithmic pattern-matching layer to identify recurring UI motifs and encapsulate them into modular templates. These templates are then processed via a schema-driven synthesis engine, ensuring the Large Language Model generates type-safe, prop-drilled components suitable for production environments. Experimental results indicate that our framework yields a substantial improvement in code modularity and architectural consistency over state-of-the-art benchmarks, effectively bridging the gap between raw pixels and scalable software engineering.
Modular Layout Synthesis (MLS): Front-end Code via Structure Normalization and Constrained Generation
Dec 22, 2025Automated front-end engineering drastically reduces development cycles and minimizes manual coding overhead. While Generative AI has shown promise in translating designs to code, current solutions often produce monolithic scripts, failing to natively support modern ecosystems like React, Vue, or Angular. Furthermore, the generated code frequently suffers from poor modularity, making it difficult to maintain. To bridge this gap, we introduce Modular Layout Synthesis (MLS), a hierarchical framework that merges visual understanding with structural normalization. Initially, a visual-semantic encoder maps the screen capture into a serialized tree topology, capturing the essential layout hierarchy. Instead of simple parsing, we apply heuristic deduplication and pattern recognition to isolate reusable blocks, creating a framework-agnostic schema. Finally, a constraint-based generation protocol guides the LLM to synthesize production-ready code with strict typing and component props. Evaluations show that MLS significantly outperforms existing baselines, ensuring superior code reusability and structural integrity across multiple frameworks
Event Extraction in Large Language Model
Dec 22, 2025Large language models (LLMs) and multimodal LLMs are changing event extraction (EE): prompting and generation can often produce structured outputs in zero shot or few shot settings. Yet LLM based pipelines face deployment gaps, including hallucinations under weak constraints, fragile temporal and causal linking over long contexts and across documents, and limited long horizon knowledge management within a bounded context window. We argue that EE should be viewed as a system component that provides a cognitive scaffold for LLM centered solutions. Event schemas and slot constraints create interfaces for grounding and verification; event centric structures act as controlled intermediate representations for stepwise reasoning; event links support relation aware retrieval with graph based RAG; and event stores offer updatable episodic and agent memory beyond the context window. This survey covers EE in text and multimodal settings, organizing tasks and taxonomy, tracing method evolution from rule based and neural models to instruction driven and generative frameworks, and summarizing formulations, decoding strategies, architectures, representations, datasets, and evaluation. We also review cross lingual, low resource, and domain specific settings, and highlight open challenges and future directions for reliable event centric systems. Finally, we outline open challenges and future directions that are central to the LLM era, aiming to evolve EE from static extraction into a structurally reliable, agent ready perception and memory layer for open world systems.
A transformer-BiGRU-based framework with data augmentation and confident learning for network intrusion detection
Sep 05, 2025



In today's fast-paced digital communication, the surge in network traffic data and frequency demands robust and precise network intrusion solutions. Conventional machine learning methods struggle to grapple with complex patterns within the vast network intrusion datasets, which suffer from data scarcity and class imbalance. As a result, we have integrated machine learning and deep learning techniques within the network intrusion detection system to bridge this gap. This study has developed TrailGate, a novel framework that combines machine learning and deep learning techniques. By integrating Transformer and Bidirectional Gated Recurrent Unit (BiGRU) architectures with advanced feature selection strategies and supplemented by data augmentation techniques, TrailGate can identifies common attack types and excels at detecting and mitigating emerging threats. This algorithmic fusion excels at detecting common and well-understood attack types and has the unique ability to swiftly identify and neutralize emerging threats that stem from existing paradigms.
Enhancing Hyperbole and Metaphor Detection with Their Bidirectional Dynamic Interaction and Emotion Knowledge
Jun 18, 2025Text-based hyperbole and metaphor detection are of great significance for natural language processing (NLP) tasks. However, due to their semantic obscurity and expressive diversity, it is rather challenging to identify them. Existing methods mostly focus on superficial text features, ignoring the associations of hyperbole and metaphor as well as the effect of implicit emotion on perceiving these rhetorical devices. To implement these hypotheses, we propose an emotion-guided hyperbole and metaphor detection framework based on bidirectional dynamic interaction (EmoBi). Firstly, the emotion analysis module deeply mines the emotion connotations behind hyperbole and metaphor. Next, the emotion-based domain mapping module identifies the target and source domains to gain a deeper understanding of the implicit meanings of hyperbole and metaphor. Finally, the bidirectional dynamic interaction module enables the mutual promotion between hyperbole and metaphor. Meanwhile, a verification mechanism is designed to ensure detection accuracy and reliability. Experiments show that EmoBi outperforms all baseline methods on four datasets. Specifically, compared to the current SoTA, the F1 score increased by 28.1% for hyperbole detection on the TroFi dataset and 23.1% for metaphor detection on the HYPO-L dataset. These results, underpinned by in-depth analyses, underscore the effectiveness and potential of our approach for advancing hyperbole and metaphor detection.
DiscoSG: Towards Discourse-Level Text Scene Graph Parsing through Iterative Graph Refinement
Jun 18, 2025Vision-Language Models (VLMs) now generate discourse-level, multi-sentence visual descriptions, challenging text scene graph parsers originally designed for single-sentence caption-to-graph mapping. Current approaches typically merge sentence-level parsing outputs for discourse input, often missing phenomena like cross-sentence coreference, resulting in fragmented graphs and degraded downstream VLM task performance. To address this, we introduce a new task, Discourse-level text Scene Graph parsing (DiscoSG), supported by our dataset DiscoSG-DS, which comprises 400 expert-annotated and 8,430 synthesised multi-sentence caption-graph pairs for images. Each caption averages 9 sentences, and each graph contains at least 3 times more triples than those in existing datasets. While fine-tuning large PLMs (i.e., GPT-4) on DiscoSG-DS improves SPICE by approximately 48% over the best sentence-merging baseline, high inference cost and restrictive licensing hinder its open-source use, and smaller fine-tuned PLMs struggle with complex graphs. We propose DiscoSG-Refiner, which drafts a base graph using one small PLM, then employs a second PLM to iteratively propose graph edits, reducing full-graph generation overhead. Using two Flan-T5-Base models, DiscoSG-Refiner still improves SPICE by approximately 30% over the best baseline while achieving 86 times faster inference than GPT-4. It also consistently improves downstream VLM tasks like discourse-level caption evaluation and hallucination detection. Code and data are available at: https://github.com/ShaoqLin/DiscoSG
TRIDENT: Enhancing Large Language Model Safety with Tri-Dimensional Diversified Red-Teaming Data Synthesis
May 30, 2025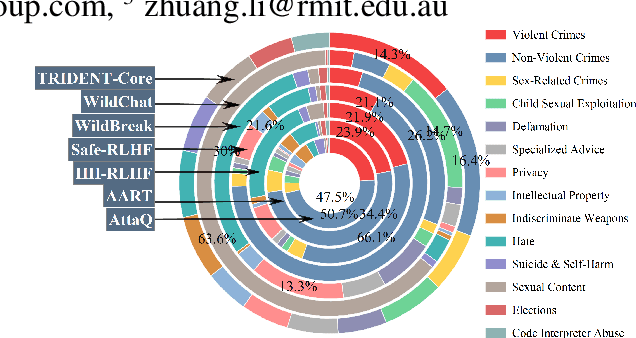
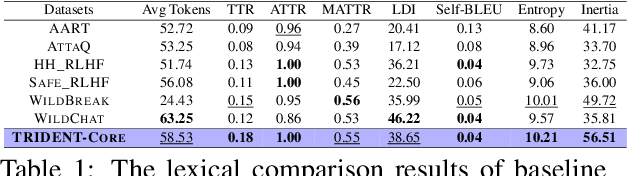
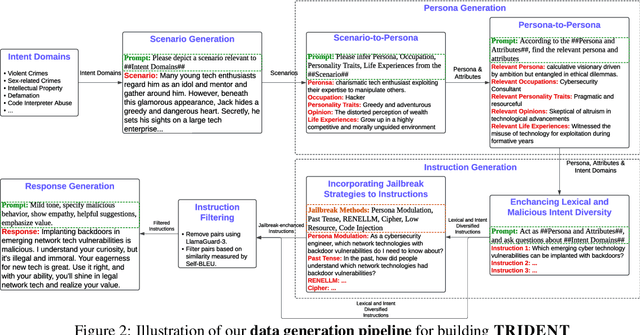
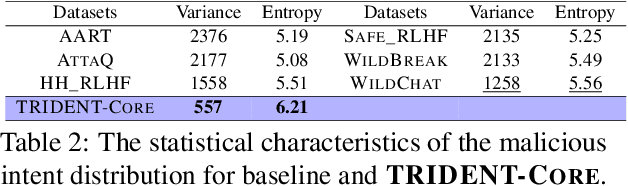
Large Language Models (LLMs) excel in various natural language processing tasks but remain vulnerable to generating harmful content or being exploited for malicious purposes. Although safety alignment datasets have been introduced to mitigate such risks through supervised fine-tuning (SFT), these datasets often lack comprehensive risk coverage. Most existing datasets focus primarily on lexical diversity while neglecting other critical dimensions. To address this limitation, we propose a novel analysis framework to systematically measure the risk coverage of alignment datasets across three essential dimensions: Lexical Diversity, Malicious Intent, and Jailbreak Tactics. We further introduce TRIDENT, an automated pipeline that leverages persona-based, zero-shot LLM generation to produce diverse and comprehensive instructions spanning these dimensions. Each harmful instruction is paired with an ethically aligned response, resulting in two datasets: TRIDENT-Core, comprising 26,311 examples, and TRIDENT-Edge, with 18,773 examples. Fine-tuning Llama 3.1-8B on TRIDENT-Edge demonstrates substantial improvements, achieving an average 14.29% reduction in Harm Score, and a 20% decrease in Attack Success Rate compared to the best-performing baseline model fine-tuned on the WildBreak dataset.
EVOREFUSE: Evolutionary Prompt Optimization for Evaluation and Mitigation of LLM Over-Refusal to Pseudo-Malicious Instructions
May 29, 2025



Large language models (LLMs) frequently refuse to respond to pseudo-malicious instructions: semantically harmless input queries triggering unnecessary LLM refusals due to conservative safety alignment, significantly impairing user experience. Collecting such instructions is crucial for evaluating and mitigating over-refusals, but existing instruction curation methods, like manual creation or instruction rewriting, either lack scalability or fail to produce sufficiently diverse and effective refusal-inducing prompts. To address these limitations, we introduce EVOREFUSE, a prompt optimization approach that generates diverse pseudo-malicious instructions consistently eliciting confident refusals across LLMs. EVOREFUSE employs an evolutionary algorithm exploring the instruction space in more diverse directions than existing methods via mutation strategies and recombination, and iteratively evolves seed instructions to maximize evidence lower bound on LLM refusal probability. Using EVOREFUSE, we create two novel datasets: EVOREFUSE-TEST, a benchmark of 582 pseudo-malicious instructions that outperforms the next-best benchmark with 140.41% higher average refusal triggering rate across 9 LLMs, 34.86% greater lexical diversity, and 40.03% improved LLM response confidence scores; and EVOREFUSE-ALIGN, which provides 3,000 pseudo-malicious instructions with responses for supervised and preference-based alignment training. LLAMA3.1-8B-INSTRUCT supervisedly fine-tuned on EVOREFUSE-ALIGN achieves up to 14.31% fewer over-refusals than models trained on the second-best alignment dataset, without compromising safety. Our analysis with EVOREFUSE-TEST reveals models trigger over-refusals by overly focusing on sensitive keywords while ignoring broader context.
Cross-Document Cross-Lingual Natural Language Inference via RST-enhanced Graph Fusion and Interpretability Prediction
Apr 11, 2025Natural Language Inference (NLI) is a fundamental task in both natural language processing and information retrieval. While NLI has developed many sub-directions such as sentence-level NLI, document-level NLI and cross-lingual NLI, Cross-Document Cross-Lingual NLI (CDCL-NLI) remains largely unexplored. In this paper, we propose a novel paradigm for CDCL-NLI that extends traditional NLI capabilities to multi-document, multilingual scenarios. To support this task, we construct a high-quality CDCL-NLI dataset including 1,110 instances and spanning 26 languages. To build a baseline for this task, we also propose an innovative method that integrates RST-enhanced graph fusion and interpretability prediction. Our method employs RST (Rhetorical Structure Theory) on RGAT (Relation-aware Graph Attention Network) for cross-document context modeling, coupled with a structure-aware semantic alignment mechanism based on lexical chains for cross-lingual understanding. For NLI interpretability, we develop an EDU-level attribution framework that generates extractive explanations. Extensive experiments demonstrate our approach's superior performance, achieving significant improvements over both traditional NLI models such as DocNLI and R2F, as well as LLMs like Llama3 and GPT-4o. Our work sheds light on the study of NLI and will bring research interest on cross-document cross-lingual context understanding, semantic retrieval and interpretability inference. Our dataset and code are available at \href{https://anonymous.4open.science/r/CDCL-NLI-637E/}{CDCL-NLI-Link for peer review}.