 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBaichuan-Omni-1.5 Technical Report
Jan 26, 2025



We introduce Baichuan-Omni-1.5, an omni-modal model that not only has omni-modal understanding capabilities but also provides end-to-end audio generation capabilities. To achieve fluent and high-quality interaction across modalities without compromising the capabilities of any modality, we prioritized optimizing three key aspects. First, we establish a comprehensive data cleaning and synthesis pipeline for multimodal data, obtaining about 500B high-quality data (text, audio, and vision). Second, an audio-tokenizer (Baichuan-Audio-Tokenizer) has been designed to capture both semantic and acoustic information from audio, enabling seamless integration and enhanced compatibility with MLLM. Lastly, we designed a multi-stage training strategy that progressively integrates multimodal alignment and multitask fine-tuning, ensuring effective synergy across all modalities. Baichuan-Omni-1.5 leads contemporary models (including GPT4o-mini and MiniCPM-o 2.6) in terms of comprehensive omni-modal capabilities. Notably, it achieves results comparable to leading models such as Qwen2-VL-72B across various multimodal medical benchmarks.
Ocean-OCR: Towards General OCR Application via a Vision-Language Model
Jan 26, 2025



Multimodal large language models (MLLMs) have shown impressive capabilities across various domains, excelling in processing and understanding information from multiple modalities. Despite the rapid progress made previously, insufficient OCR ability hinders MLLMs from excelling in text-related tasks. In this paper, we present \textbf{Ocean-OCR}, a 3B MLLM with state-of-the-art performance on various OCR scenarios and comparable understanding ability on general tasks. We employ Native Resolution ViT to enable variable resolution input and utilize a substantial collection of high-quality OCR datasets to enhance the model performance. We demonstrate the superiority of Ocean-OCR through comprehensive experiments on open-source OCR benchmarks and across various OCR scenarios. These scenarios encompass document understanding, scene text recognition, and handwritten recognition, highlighting the robust OCR capabilities of Ocean-OCR. Note that Ocean-OCR is the first MLLM to outperform professional OCR models such as TextIn and PaddleOCR.
Marco-LLM: Bridging Languages via Massive Multilingual Training for Cross-Lingual Enhancement
Dec 05, 2024Large Language Models (LLMs) have achieved remarkable progress in recent years; however, their excellent performance is still largely limited to major world languages, primarily English. Many LLMs continue to face challenges with multilingual tasks, especially when it comes to low-resource languages. To address this issue, we introduced Marco-LLM: Massive multilingual training for cross-lingual enhancement LLM. We have collected a substantial amount of multilingual data for several low-resource languages and conducted extensive continual pre-training using the Qwen2 models. This effort has resulted in a multilingual LLM named Marco-LLM. Through comprehensive evaluations on various multilingual benchmarks, including MMMLU, AGIEval, Belebele, Flores-200, XCOPA and many others, Marco-LLM has demonstrated substantial improvements over state-of-the-art LLMs. Furthermore, Marco-LLM achieved substantial enhancements in any-to-any machine translation tasks, showing the effectiveness of our multilingual LLM. Marco-LLM is a pioneering multilingual LLM designed to not only perform exceptionally well in multilingual tasks, including low-resource languages, but also maintain strong performance in English and other major languages, closing the performance gap between high- and low-resource language capabilities. By bridging languages, this effort demonstrates our dedication to ensuring LLMs work accurately across various languages.
M3GIA: A Cognition Inspired Multilingual and Multimodal General Intelligence Ability Benchmark
Jun 08, 2024

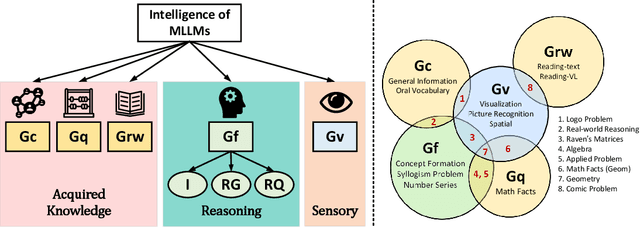

As recent multi-modality large language models (MLLMs) have shown formidable proficiency on various complex tasks, there has been increasing attention on debating whether these models could eventually mirror human intelligence. However, existing benchmarks mainly focus on evaluating solely on task performance, such as the accuracy of identifying the attribute of an object. Combining well-developed cognitive science to understand the intelligence of MLLMs beyond superficial achievements remains largely unexplored. To this end, we introduce the first cognitive-driven multi-lingual and multi-modal benchmark to evaluate the general intelligence ability of MLLMs, dubbed M3GIA. Specifically, we identify five key cognitive factors based on the well-recognized Cattell-Horn-Carrol (CHC) model of intelligence and propose a novel evaluation metric. In addition, since most MLLMs are trained to perform in different languages, a natural question arises: is language a key factor influencing the cognitive ability of MLLMs? As such, we go beyond English to encompass other languages based on their popularity, including Chinese, French, Spanish, Portuguese and Korean, to construct our M3GIA. We make sure all the data relevant to the cultural backgrounds are collected from their native context to avoid English-centric bias. We collected a significant corpus of data from human participants, revealing that the most advanced MLLM reaches the lower boundary of human intelligence in English. Yet, there remains a pronounced disparity in the other five languages assessed. We also reveals an interesting winner takes all phenomenon that are aligned with the discovery in cognitive studies. Our benchmark will be open-sourced, with the aspiration of facilitating the enhancement of cognitive capabilities in MLLMs.
Realistic Safety-critical Scenarios Search for Autonomous Driving System via Behavior Tree
May 11, 2023The simulation-based testing of Autonomous Driving Systems (ADSs) has gained significant attention. However, current approaches often fall short of accurately assessing ADSs for two reasons: over-reliance on expert knowledge and the utilization of simplistic evaluation metrics. That leads to discrepancies between simulated scenarios and naturalistic driving environments. To address this, we propose the Matrix-Fuzzer, a behavior tree-based testing framework, to automatically generate realistic safety-critical test scenarios. Our approach involves the $log2BT$ method, which abstracts logged road-users' trajectories to behavior sequences. Furthermore, we vary the properties of behaviors from real-world driving distributions and then use an adaptive algorithm to explore the input space. Meanwhile, we design a general evaluation engine that guides the algorithm toward critical areas, thus reducing the generation of invalid scenarios. Our approach is demonstrated in our Matrix Simulator. The experimental results show that: (1) Our $log2BT$ achieves satisfactory trajectory reconstructions. (2) Our approach is able to find the most types of safety-critical scenarios, but only generating around 30% of the total scenarios compared with the baseline algorithm. Specifically, it improves the ratio of the critical violations to total scenarios and the ratio of the types to total scenarios by at least 10x and 5x, respectively, while reducing the ratio of the invalid scenarios to total scenarios by at least 58% in two case studies.