 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUAF: A Unified Audio Front-end LLM for Full-Duplex Speech Interaction
Apr 21, 2026Full-duplex speech interaction, as the most natural and intuitive mode of human communication, is driving artificial intelligence toward more human-like conversational systems. Traditional cascaded speech processing pipelines suffer from critical limitations, including accumulated latency, information loss, and error propagation across modules. To address these issues, recent efforts focus on the end-to-end audio large language models (LLMs) like GPT-4o, which primarily unify speech understanding and generation task. However, most of these models are inherently half-duplex, and rely on a suite of separate, task-specific front-end components, such as voice activity detection (VAD) and turn-taking detection (TD). In our development of speech assistant, we observed that optimizing the speech front-end is equally crucial as advancing the back-end unified model for achieving seamless, responsive interactions. To bridge this gap, we propose the first unified audio front-end LLM (UAF) tailored for full-duplex speech systems. Our model reformulates diverse audio front-end tasks into a single auto-regressive sequence prediction problem, including VAD, TD, speaker recognition (SR), automatic speech recognition (ASR) and question answer (QA). It takes streaming fixed-duration audio chunk (e.g., 600 ms) as input, leverages a reference audio prompt to anchor the target speaker at the beginning, and regressively generates discrete tokens encoding both semantic content and system-level state controls (e.g., interruption signals). Experiments demonstrate that our model achieves leading performance across multiple audio front-end tasks and significantly enhances response latency and interruption accuracy in real-world interaction scenarios.
Learning How Much to Think: Difficulty-Aware Dynamic MoEs for Graph Node Classification
Apr 13, 2026Mixture-of-Experts (MoE) architectures offer a scalable path for Graph Neural Networks (GNNs) in node classification tasks but typically rely on static and rigid routing strategies that enforce a uniform expert budget or coarse-grained expert toggles on all nodes. This limitation overlooks the varying discriminative difficulty of nodes and leads to under-fitting for hard nodes and redundant computation for easy ones. To resolve this issue, we propose D2MoE, a novel framework that shifts the focus from static expert selection to node-wise expert resource allocation. By using predictive entropy as a real-time proxy for difficulty, D2MoE employs a difficulty-driven top-p routing mechanism to adaptively concentrate expert resources on hard nodes while reducing overhead for easy ones, achieving continuous and fine-grained expert budget scaling for node classification. Experiments on 13 benchmarks demonstrate that D2MoE achieves consistent state-of-the-art performance, surpassing leading baselines by up to 7.92% in accuracy on heterophilous graphs. Notably, on large-scale graphs, it reduces memory consumption by up to 73.07% and training time by 46.53% compared to the best-performing Graph MoE, thereby validating its superior efficiency.
CrossHGL: A Text-Free Foundation Model for Cross-Domain Heterogeneous Graph Learning
Mar 29, 2026Heterogeneous graph representation learning (HGRL) is essential for modeling complex systems with diverse node and edge types. However, most existing methods are limited to closed-world settings with shared schemas and feature spaces, hindering cross-domain generalization. While recent graph foundation models improve transferability, they often target homogeneous graphs, rely on domain-specific schemas, or require rich textual attributes. Consequently, text-free and few-shot cross-domain HGRL remains underexplored. To address this, we propose CrossHGL, a foundation framework that preserves and transfers multi-relational structural semantics without external textual supervision. Specifically, a semantic-preserving transformation strategy homogenizes heterogeneous graphs while encoding interaction semantics into edge features. Based on this, a prompt-aware multi-domain pre-training framework with a Tri-Prompt mechanism captures transferable knowledge across feature, edge, and structure perspectives via self-supervised contrastive learning. For target-domain adaptation, we develop a parameter-efficient fine-tuning strategy that freezes the pre-trained backbone and performs few-shot classification via prompt composition and prototypical learning. Experiments on node-level and graph-level tasks show that CrossHGL consistently outperforms state-of-the-art baselines, yielding average relative improvements of 25.1% and 7.6% in Micro-F1 for node and graph classification, respectively, while remaining competitive in challenging feature-degenerated settings.
UCPO: Uncertainty-Aware Policy Optimization
Jan 30, 2026The key to building trustworthy Large Language Models (LLMs) lies in endowing them with inherent uncertainty expression capabilities to mitigate the hallucinations that restrict their high-stakes applications. However, existing RL paradigms such as GRPO often suffer from Advantage Bias due to binary decision spaces and static uncertainty rewards, inducing either excessive conservatism or overconfidence. To tackle this challenge, this paper unveils the root causes of reward hacking and overconfidence in current RL paradigms incorporating uncertainty-based rewards, based on which we propose the UnCertainty-Aware Policy Optimization (UCPO) framework. UCPO employs Ternary Advantage Decoupling to separate and independently normalize deterministic and uncertain rollouts, thereby eliminating advantage bias. Furthermore, a Dynamic Uncertainty Reward Adjustment mechanism is introduced to calibrate uncertainty weights in real-time according to model evolution and instance difficulty. Experimental results in mathematical reasoning and general tasks demonstrate that UCPO effectively resolves the reward imbalance, significantly improving the reliability and calibration of the model beyond their knowledge boundaries.
StarCraft+: Benchmarking Multi-agent Algorithms in Adversary Paradigm
Dec 18, 2025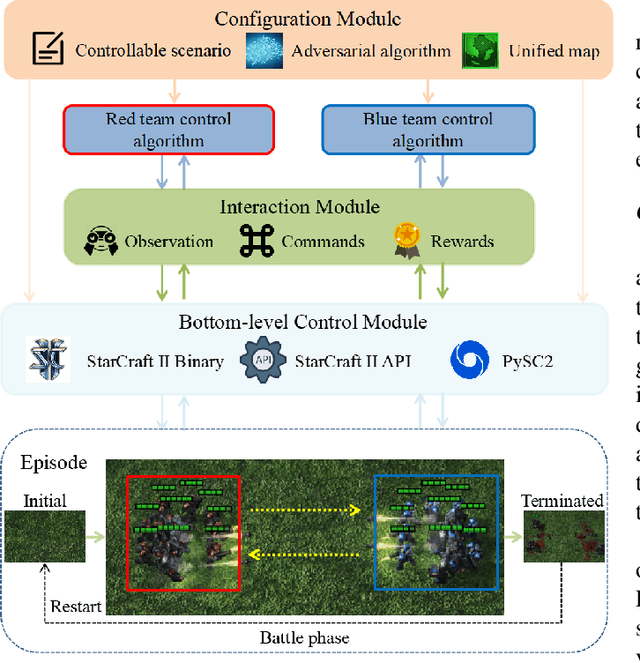
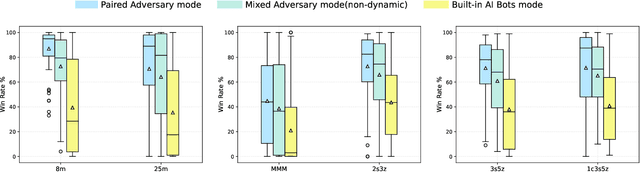
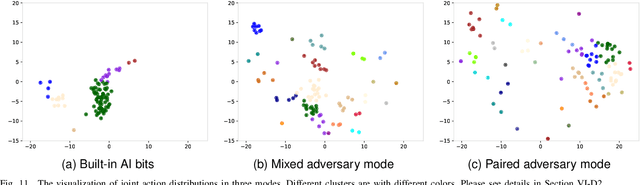
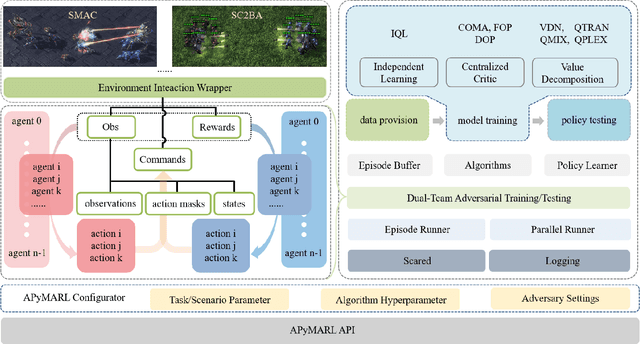
Deep multi-agent reinforcement learning (MARL) algorithms are booming in the field of collaborative intelligence, and StarCraft multi-agent challenge (SMAC) is widely-used as the benchmark therein. However, imaginary opponents of MARL algorithms are practically configured and controlled in a fixed built-in AI mode, which causes less diversity and versatility in algorithm evaluation. To address this issue, in this work, we establish a multi-agent algorithm-vs-algorithm environment, named StarCraft II battle arena (SC2BA), to refresh the benchmarking of MARL algorithms in an adversary paradigm. Taking StarCraft as infrastructure, the SC2BA environment is specifically created for inter-algorithm adversary with the consideration of fairness, usability and customizability, and meantime an adversarial PyMARL (APyMARL) library is developed with easy-to-use interfaces/modules. Grounding in SC2BA, we benchmark those classic MARL algorithms in two types of adversarial modes: dual-algorithm paired adversary and multi-algorithm mixed adversary, where the former conducts the adversary of pairwise algorithms while the latter focuses on the adversary to multiple behaviors from a group of algorithms. The extensive benchmark experiments exhibit some thought-provoking observations/problems in the effectivity, sensibility and scalability of these completed algorithms. The SC2BA environment as well as reproduced experiments are released in \href{https://github.com/dooliu/SC2BA}{Github}, and we believe that this work could mark a new step for the MARL field in the coming years.
Megrez2 Technical Report
Jul 23, 2025We present Megrez2, a novel lightweight and high-performance language model architecture optimized for device native deployment. Megrez2 introduces a novel cross-layer expert sharing mechanism, which significantly reduces total parameter count by reusing expert modules across adjacent transformer layers while maintaining most of the model's capacity. It also incorporates pre-gated routing, enabling memory-efficient expert loading and faster inference. As the first instantiation of the Megrez2 architecture, we introduce the Megrez2-Preview model, which is pre-trained on a 5-trillion-token corpus and further enhanced through supervised fine-tuning and reinforcement learning with verifiable rewards. With only 3B activated and 7.5B stored parameters, Megrez2-Preview demonstrates competitive or superior performance compared to larger models on a wide range of tasks, including language understanding, instruction following, mathematical reasoning, and code generation. These results highlight the effectiveness of the Megrez2 architecture to achieve a balance between accuracy, efficiency, and deployability, making it a strong candidate for real-world, resource-constrained applications.
DualToken: Towards Unifying Visual Understanding and Generation with Dual Visual Vocabularies
Mar 19, 2025The differing representation spaces required for visual understanding and generation pose a challenge in unifying them within the autoregressive paradigm of large language models. A vision tokenizer trained for reconstruction excels at capturing low-level perceptual details, making it well-suited for visual generation but lacking high-level semantic representations for understanding tasks. Conversely, a vision encoder trained via contrastive learning aligns well with language but struggles to decode back into the pixel space for generation tasks. To bridge this gap, we propose DualToken, a method that unifies representations for both understanding and generation within a single tokenizer. However, directly integrating reconstruction and semantic objectives in a single tokenizer creates conflicts, leading to degraded performance in both reconstruction quality and semantic performance. Instead of forcing a single codebook to handle both semantic and perceptual information, DualToken disentangles them by introducing separate codebooks for high and low-level features, effectively transforming their inherent conflict into a synergistic relationship. As a result, DualToken achieves state-of-the-art performance in both reconstruction and semantic tasks while demonstrating remarkable effectiveness in downstream MLLM understanding and generation tasks. Notably, we also show that DualToken, as a unified tokenizer, surpasses the naive combination of two distinct types vision encoders, providing superior performance within a unified MLLM.
Megrez-Omni Technical Report
Feb 19, 2025



In this work, we present the Megrez models, comprising a language model (Megrez-3B-Instruct) and a multimodal model (Megrez-3B-Omni). These models are designed to deliver fast inference, compactness, and robust edge-side intelligence through a software-hardware co-design approach. Megrez-3B-Instruct offers several advantages, including high accuracy, high speed, ease of use, and a wide range of applications. Building on Megrez-3B-Instruct, Megrez-3B-Omni is an on-device multimodal understanding LLM that supports image, text, and audio analysis. It achieves state-of-the-art accuracy across all three modalities and demonstrates strong versatility and robustness, setting a new benchmark for multimodal AI models.
Ocean-OCR: Towards General OCR Application via a Vision-Language Model
Jan 26, 2025



Multimodal large language models (MLLMs) have shown impressive capabilities across various domains, excelling in processing and understanding information from multiple modalities. Despite the rapid progress made previously, insufficient OCR ability hinders MLLMs from excelling in text-related tasks. In this paper, we present \textbf{Ocean-OCR}, a 3B MLLM with state-of-the-art performance on various OCR scenarios and comparable understanding ability on general tasks. We employ Native Resolution ViT to enable variable resolution input and utilize a substantial collection of high-quality OCR datasets to enhance the model performance. We demonstrate the superiority of Ocean-OCR through comprehensive experiments on open-source OCR benchmarks and across various OCR scenarios. These scenarios encompass document understanding, scene text recognition, and handwritten recognition, highlighting the robust OCR capabilities of Ocean-OCR. Note that Ocean-OCR is the first MLLM to outperform professional OCR models such as TextIn and PaddleOCR.
Baichuan-Omni-1.5 Technical Report
Jan 26, 2025



We introduce Baichuan-Omni-1.5, an omni-modal model that not only has omni-modal understanding capabilities but also provides end-to-end audio generation capabilities. To achieve fluent and high-quality interaction across modalities without compromising the capabilities of any modality, we prioritized optimizing three key aspects. First, we establish a comprehensive data cleaning and synthesis pipeline for multimodal data, obtaining about 500B high-quality data (text, audio, and vision). Second, an audio-tokenizer (Baichuan-Audio-Tokenizer) has been designed to capture both semantic and acoustic information from audio, enabling seamless integration and enhanced compatibility with MLLM. Lastly, we designed a multi-stage training strategy that progressively integrates multimodal alignment and multitask fine-tuning, ensuring effective synergy across all modalities. Baichuan-Omni-1.5 leads contemporary models (including GPT4o-mini and MiniCPM-o 2.6) in terms of comprehensive omni-modal capabilities. Notably, it achieves results comparable to leading models such as Qwen2-VL-72B across various multimodal medical benchmarks.