 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTongSIM: A General Platform for Simulating Intelligent Machines
Dec 23, 2025As artificial intelligence (AI) rapidly advances, especially in multimodal large language models (MLLMs), research focus is shifting from single-modality text processing to the more complex domains of multimodal and embodied AI. Embodied intelligence focuses on training agents within realistic simulated environments, leveraging physical interaction and action feedback rather than conventionally labeled datasets. Yet, most existing simulation platforms remain narrowly designed, each tailored to specific tasks. A versatile, general-purpose training environment that can support everything from low-level embodied navigation to high-level composite activities, such as multi-agent social simulation and human-AI collaboration, remains largely unavailable. To bridge this gap, we introduce TongSIM, a high-fidelity, general-purpose platform for training and evaluating embodied agents. TongSIM offers practical advantages by providing over 100 diverse, multi-room indoor scenarios as well as an open-ended, interaction-rich outdoor town simulation, ensuring broad applicability across research needs. Its comprehensive evaluation framework and benchmarks enable precise assessment of agent capabilities, such as perception, cognition, decision-making, human-robot cooperation, and spatial and social reasoning. With features like customized scenes, task-adaptive fidelity, diverse agent types, and dynamic environmental simulation, TongSIM delivers flexibility and scalability for researchers, serving as a unified platform that accelerates training, evaluation, and advancement toward general embodied intelligence.
Factorization-in-Loop: Proximal Fill-in Minimization for Sparse Matrix Reordering
Nov 12, 2025Fill-ins are new nonzero elements in the summation of the upper and lower triangular factors generated during LU factorization. For large sparse matrices, they will increase the memory usage and computational time, and be reduced through proper row or column arrangement, namely matrix reordering. Finding a row or column permutation with the minimal fill-ins is NP-hard, and surrogate objectives are designed to derive fill-in reduction permutations or learn a reordering function. However, there is no theoretical guarantee between the golden criterion and these surrogate objectives. Here we propose to learn a reordering network by minimizing \(l_1\) norm of triangular factors of the reordered matrix to approximate the exact number of fill-ins. The reordering network utilizes a graph encoder to predict row or column node scores. For inference, it is easy and fast to derive the permutation from sorting algorithms for matrices. For gradient based optimization, there is a large gap between the predicted node scores and resultant triangular factors in the optimization objective. To bridge the gap, we first design two reparameterization techniques to obtain the permutation matrix from node scores. The matrix is reordered by multiplying the permutation matrix. Then we introduce the factorization process into the objective function to arrive at target triangular factors. The overall objective function is optimized with the alternating direction method of multipliers and proximal gradient descent. Experimental results on benchmark sparse matrix collection SuiteSparse show the fill-in number and LU factorization time reduction of our proposed method is 20% and 17.8% compared with state-of-the-art baselines.
Query-Kontext: An Unified Multimodal Model for Image Generation and Editing
Sep 30, 2025
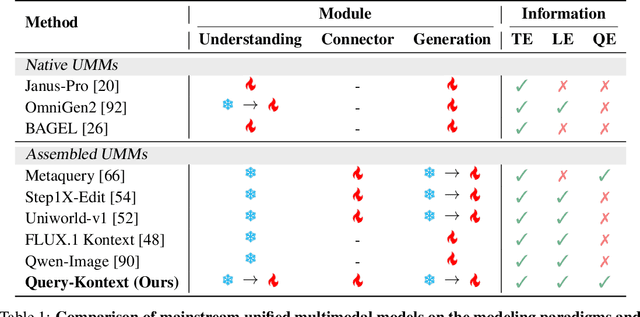
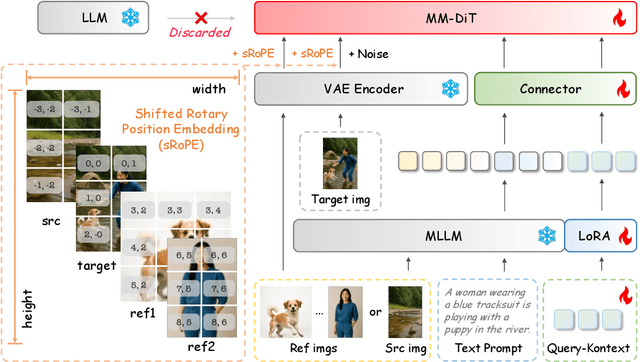
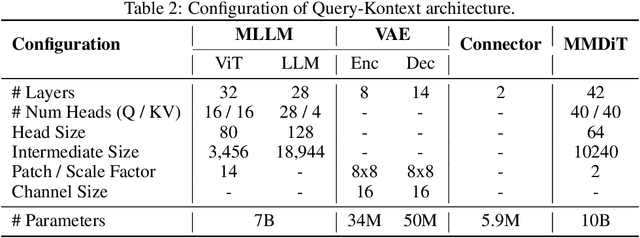
Unified Multimodal Models (UMMs) have demonstrated remarkable performance in text-to-image generation (T2I) and editing (TI2I), whether instantiated as assembled unified frameworks which couple powerful vision-language model (VLM) with diffusion-based generator, or as naive Unified Multimodal Models with an early fusion of understanding and generation modalities. We contend that in current unified frameworks, the crucial capability of multimodal generative reasoning which encompasses instruction understanding, grounding, and image referring for identity preservation and faithful reconstruction, is intrinsically entangled with high-fidelity synthesis. In this work, we introduce Query-Kontext, a novel approach that bridges the VLM and diffusion model via a multimodal ``kontext'' composed of semantic cues and coarse-grained image conditions encoded from multimodal inputs. This design delegates the complex ability of multimodal generative reasoning to powerful VLM while reserving diffusion model's role for high-quality visual synthesis. To achieve this, we propose a three-stage progressive training strategy. First, we connect the VLM to a lightweight diffusion head via multimodal kontext tokens to unleash the VLM's generative reasoning ability. Second, we scale this head to a large, pre-trained diffusion model to enhance visual detail and realism. Finally, we introduce a low-level image encoder to improve image fidelity and perform instruction tuning on downstream tasks. Furthermore, we build a comprehensive data pipeline integrating real, synthetic, and open-source datasets, covering diverse multimodal reference-to-image scenarios, including image generation, instruction-driven editing, customized generation, and multi-subject composition. Experiments show that our approach matches strong unified baselines and even outperforms task-specific state-of-the-art methods in several cases.
Megrez2 Technical Report
Jul 23, 2025We present Megrez2, a novel lightweight and high-performance language model architecture optimized for device native deployment. Megrez2 introduces a novel cross-layer expert sharing mechanism, which significantly reduces total parameter count by reusing expert modules across adjacent transformer layers while maintaining most of the model's capacity. It also incorporates pre-gated routing, enabling memory-efficient expert loading and faster inference. As the first instantiation of the Megrez2 architecture, we introduce the Megrez2-Preview model, which is pre-trained on a 5-trillion-token corpus and further enhanced through supervised fine-tuning and reinforcement learning with verifiable rewards. With only 3B activated and 7.5B stored parameters, Megrez2-Preview demonstrates competitive or superior performance compared to larger models on a wide range of tasks, including language understanding, instruction following, mathematical reasoning, and code generation. These results highlight the effectiveness of the Megrez2 architecture to achieve a balance between accuracy, efficiency, and deployability, making it a strong candidate for real-world, resource-constrained applications.
A Simple Linear Patch Revives Layer-Pruned Large Language Models
May 30, 2025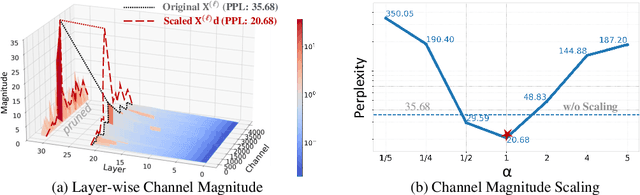
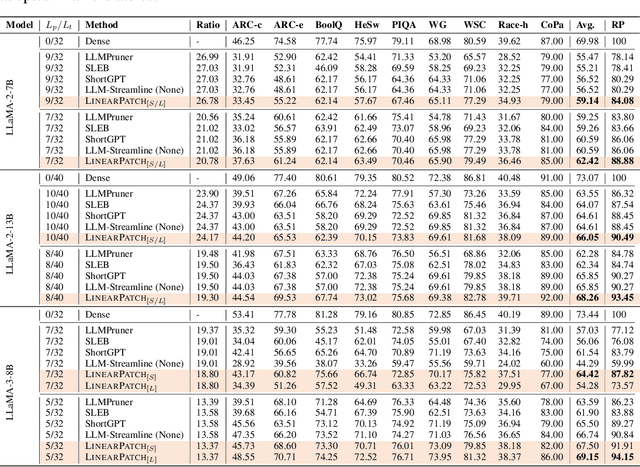
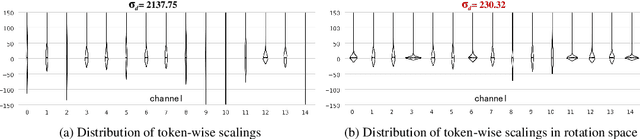
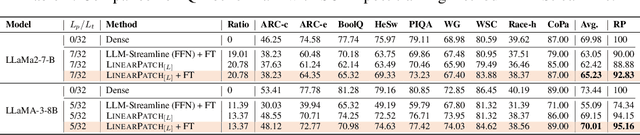
Layer pruning has become a popular technique for compressing large language models (LLMs) due to its simplicity. However, existing layer pruning methods often suffer from significant performance drops. We identify that this degradation stems from the mismatch of activation magnitudes across layers and tokens at the pruning interface. To address this, we propose LinearPatch, a simple plug-and-play technique to revive the layer-pruned LLMs. The proposed method adopts Hadamard transformation to suppress massive outliers in particular tokens, and channel-wise scaling to align the activation magnitudes. These operations can be fused into a single matrix, which functions as a patch to bridge the pruning interface with negligible inference overhead. LinearPatch retains up to 94.15% performance of the original model when pruning 5 layers of LLaMA-3-8B on the question answering benchmark, surpassing existing state-of-the-art methods by 4%. In addition, the patch matrix can be further optimized with memory efficient offline knowledge distillation. With only 5K samples, the retained performance of LinearPatch can be further boosted to 95.16% within 30 minutes on a single computing card.
Pangu Light: Weight Re-Initialization for Pruning and Accelerating LLMs
May 26, 2025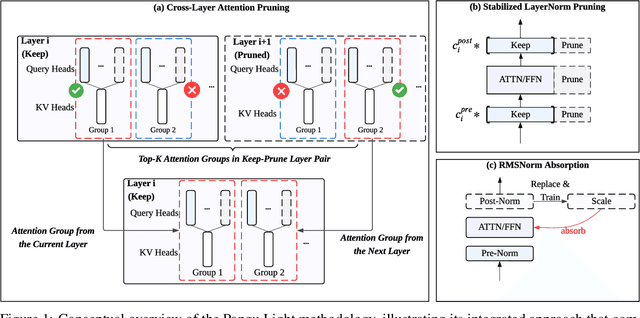

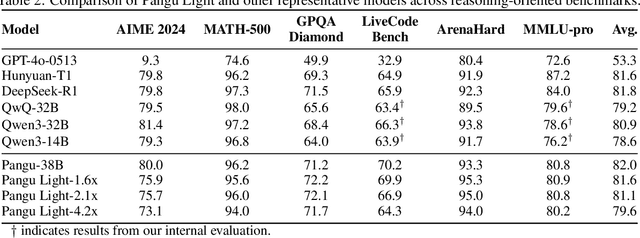
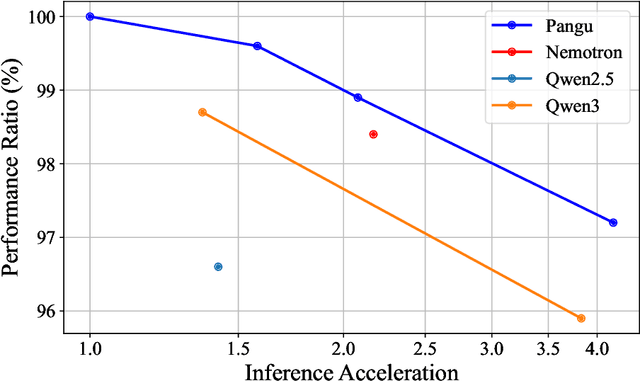
Large Language Models (LLMs) deliver state-of-the-art capabilities across numerous tasks, but their immense size and inference costs pose significant computational challenges for practical deployment. While structured pruning offers a promising avenue for model compression, existing methods often struggle with the detrimental effects of aggressive, simultaneous width and depth reductions, leading to substantial performance degradation. This paper argues that a critical, often overlooked, aspect in making such aggressive joint pruning viable is the strategic re-initialization and adjustment of remaining weights to improve the model post-pruning training accuracies. We introduce Pangu Light, a framework for LLM acceleration centered around structured pruning coupled with novel weight re-initialization techniques designed to address this ``missing piece''. Our framework systematically targets multiple axes, including model width, depth, attention heads, and RMSNorm, with its effectiveness rooted in novel re-initialization methods like Cross-Layer Attention Pruning (CLAP) and Stabilized LayerNorm Pruning (SLNP) that mitigate performance drops by providing the network a better training starting point. Further enhancing efficiency, Pangu Light incorporates specialized optimizations such as absorbing Post-RMSNorm computations and tailors its strategies to Ascend NPU characteristics. The Pangu Light models consistently exhibit a superior accuracy-efficiency trade-off, outperforming prominent baseline pruning methods like Nemotron and established LLMs like Qwen3 series. For instance, on Ascend NPUs, Pangu Light-32B's 81.6 average score and 2585 tokens/s throughput exceed Qwen3-32B's 80.9 average score and 2225 tokens/s.
Chain-of-Focus: Adaptive Visual Search and Zooming for Multimodal Reasoning via RL
May 21, 2025
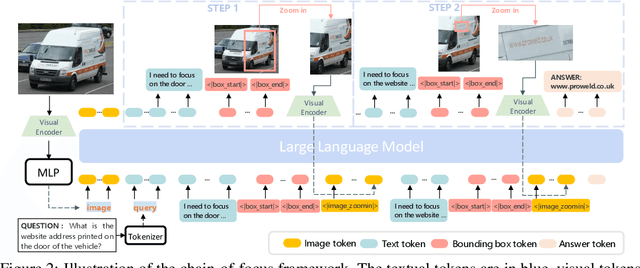


Vision language models (VLMs) have achieved impressive performance across a variety of computer vision tasks. However, the multimodal reasoning capability has not been fully explored in existing models. In this paper, we propose a Chain-of-Focus (CoF) method that allows VLMs to perform adaptive focusing and zooming in on key image regions based on obtained visual cues and the given questions, achieving efficient multimodal reasoning. To enable this CoF capability, we present a two-stage training pipeline, including supervised fine-tuning (SFT) and reinforcement learning (RL). In the SFT stage, we construct the MM-CoF dataset, comprising 3K samples derived from a visual agent designed to adaptively identify key regions to solve visual tasks with different image resolutions and questions. We use MM-CoF to fine-tune the Qwen2.5-VL model for cold start. In the RL stage, we leverage the outcome accuracies and formats as rewards to update the Qwen2.5-VL model, enabling further refining the search and reasoning strategy of models without human priors. Our model achieves significant improvements on multiple benchmarks. On the V* benchmark that requires strong visual reasoning capability, our model outperforms existing VLMs by 5% among 8 image resolutions ranging from 224 to 4K, demonstrating the effectiveness of the proposed CoF method and facilitating the more efficient deployment of VLMs in practical applications.
Iterative Tool Usage Exploration for Multimodal Agents via Step-wise Preference Tuning
May 06, 2025Multimodal agents, which integrate a controller (e.g., a large language model) with external tools, have demonstrated remarkable capabilities in tackling complex tasks. However, existing agents need to collect a large number of expert data for fine-tuning to adapt to new environments. In this paper, we propose an online self-exploration method for multimodal agents, namely SPORT, via step-wise preference optimization to refine the trajectories of agents, which automatically generates tasks and learns from solving the generated tasks, without any expert annotation. SPORT operates through four iterative components: task synthesis, step sampling, step verification, and preference tuning. First, we synthesize multi-modal tasks using language models. Then, we introduce a novel search scheme, where step sampling and step verification are executed alternately to solve each generated task. We employ a verifier to provide AI feedback to construct step-wise preference data. The data is subsequently used to update the controller's policy through preference tuning, producing a SPORT Agent. By interacting with real environments, the SPORT Agent evolves into a more refined and capable system. Evaluation in the GTA and GAIA benchmarks show that the SPORT Agent achieves 6.41\% and 3.64\% improvements, underscoring the generalization and effectiveness introduced by our method. The project page is https://SPORT-Agents.github.io.
Iterative Trajectory Exploration for Multimodal Agents
Apr 30, 2025Multimodal agents, which integrate a controller (e.g., a large language model) with external tools, have demonstrated remarkable capabilities in tackling complex tasks. However, existing agents need to collect a large number of expert data for fine-tuning to adapt to new environments. In this paper, we propose an online self-exploration method for multimodal agents, namely SPORT, via step-wise preference optimization to refine the trajectories of agents, which automatically generates tasks and learns from solving the generated tasks, without any expert annotation. SPORT operates through four iterative components: task synthesis, step sampling, step verification, and preference tuning. First, we synthesize multi-modal tasks using language models. Then, we introduce a novel search scheme, where step sampling and step verification are executed alternately to solve each generated task. We employ a verifier to provide AI feedback to construct step-wise preference data. The data is subsequently used to update the controller's policy through preference tuning, producing a SPORT Agent. By interacting with real environments, the SPORT Agent evolves into a more refined and capable system. Evaluation in the GTA and GAIA benchmarks show that the SPORT Agent achieves 6.41\% and 3.64\% improvements, underscoring the generalization and effectiveness introduced by our method. The project page is https://SPORT-Agents.github.io.
TongUI: Building Generalized GUI Agents by Learning from Multimodal Web Tutorials
Apr 17, 2025Building Graphical User Interface (GUI) agents is a promising research direction, which simulates human interaction with computers or mobile phones to perform diverse GUI tasks. However, a major challenge in developing generalized GUI agents is the lack of sufficient trajectory data across various operating systems and applications, mainly due to the high cost of manual annotations. In this paper, we propose the TongUI framework that builds generalized GUI agents by learning from rich multimodal web tutorials. Concretely, we crawl and process online GUI tutorials (such as videos and articles) into GUI agent trajectory data, through which we produce the GUI-Net dataset containing 143K trajectory data across five operating systems and more than 200 applications. We develop the TongUI agent by fine-tuning Qwen2.5-VL-3B/7B models on GUI-Net, which show remarkable performance improvements on commonly used grounding and navigation benchmarks, outperforming baseline agents about 10\% on multiple benchmarks, showing the effectiveness of the GUI-Net dataset and underscoring the significance of our TongUI framework. We will fully open-source the code, the GUI-Net dataset, and the trained models soon.