 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWideSeek-R1: Exploring Width Scaling for Broad Information Seeking via Multi-Agent Reinforcement Learning
Feb 04, 2026Recent advancements in Large Language Models (LLMs) have largely focused on depth scaling, where a single agent solves long-horizon problems with multi-turn reasoning and tool use. However, as tasks grow broader, the key bottleneck shifts from individual competence to organizational capability. In this work, we explore a complementary dimension of width scaling with multi-agent systems to address broad information seeking. Existing multi-agent systems often rely on hand-crafted workflows and turn-taking interactions that fail to parallelize work effectively. To bridge this gap, we propose WideSeek-R1, a lead-agent-subagent framework trained via multi-agent reinforcement learning (MARL) to synergize scalable orchestration and parallel execution. By utilizing a shared LLM with isolated contexts and specialized tools, WideSeek-R1 jointly optimizes the lead agent and parallel subagents on a curated dataset of 20k broad information-seeking tasks. Extensive experiments show that WideSeek-R1-4B achieves an item F1 score of 40.0% on the WideSearch benchmark, which is comparable to the performance of single-agent DeepSeek-R1-671B. Furthermore, WideSeek-R1-4B exhibits consistent performance gains as the number of parallel subagents increases, highlighting the effectiveness of width scaling.
RLinf: Flexible and Efficient Large-scale Reinforcement Learning via Macro-to-Micro Flow Transformation
Sep 19, 2025



Reinforcement learning (RL) has demonstrated immense potential in advancing artificial general intelligence, agentic intelligence, and embodied intelligence. However, the inherent heterogeneity and dynamicity of RL workflows often lead to low hardware utilization and slow training on existing systems. In this paper, we present RLinf, a high-performance RL training system based on our key observation that the major roadblock to efficient RL training lies in system flexibility. To maximize flexibility and efficiency, RLinf is built atop a novel RL system design paradigm called macro-to-micro flow transformation (M2Flow), which automatically breaks down high-level, easy-to-compose RL workflows at both the temporal and spatial dimensions, and recomposes them into optimized execution flows. Supported by RLinf worker's adaptive communication capability, we devise context switching and elastic pipelining to realize M2Flow transformation, and a profiling-guided scheduling policy to generate optimal execution plans. Extensive evaluations on both reasoning RL and embodied RL tasks demonstrate that RLinf consistently outperforms state-of-the-art systems, achieving 1.1x-2.13x speedup in end-to-end training throughput.
Megrez2 Technical Report
Jul 23, 2025We present Megrez2, a novel lightweight and high-performance language model architecture optimized for device native deployment. Megrez2 introduces a novel cross-layer expert sharing mechanism, which significantly reduces total parameter count by reusing expert modules across adjacent transformer layers while maintaining most of the model's capacity. It also incorporates pre-gated routing, enabling memory-efficient expert loading and faster inference. As the first instantiation of the Megrez2 architecture, we introduce the Megrez2-Preview model, which is pre-trained on a 5-trillion-token corpus and further enhanced through supervised fine-tuning and reinforcement learning with verifiable rewards. With only 3B activated and 7.5B stored parameters, Megrez2-Preview demonstrates competitive or superior performance compared to larger models on a wide range of tasks, including language understanding, instruction following, mathematical reasoning, and code generation. These results highlight the effectiveness of the Megrez2 architecture to achieve a balance between accuracy, efficiency, and deployability, making it a strong candidate for real-world, resource-constrained applications.
Megrez-Omni Technical Report
Feb 19, 2025



In this work, we present the Megrez models, comprising a language model (Megrez-3B-Instruct) and a multimodal model (Megrez-3B-Omni). These models are designed to deliver fast inference, compactness, and robust edge-side intelligence through a software-hardware co-design approach. Megrez-3B-Instruct offers several advantages, including high accuracy, high speed, ease of use, and a wide range of applications. Building on Megrez-3B-Instruct, Megrez-3B-Omni is an on-device multimodal understanding LLM that supports image, text, and audio analysis. It achieves state-of-the-art accuracy across all three modalities and demonstrates strong versatility and robustness, setting a new benchmark for multimodal AI models.
On Designing Effective RL Reward at Training Time for LLM Reasoning
Oct 19, 2024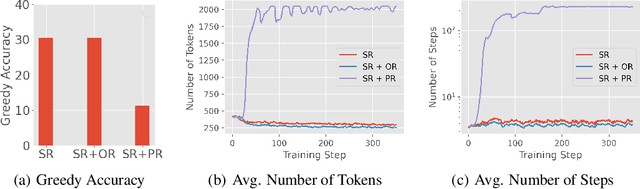
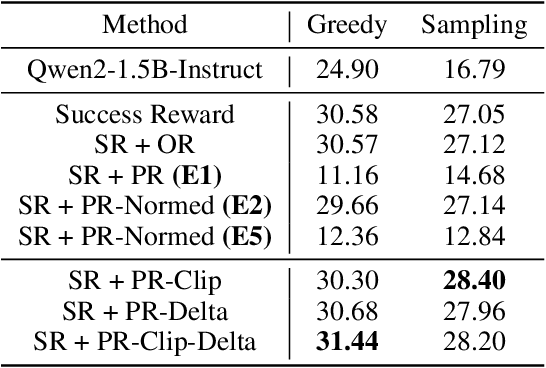

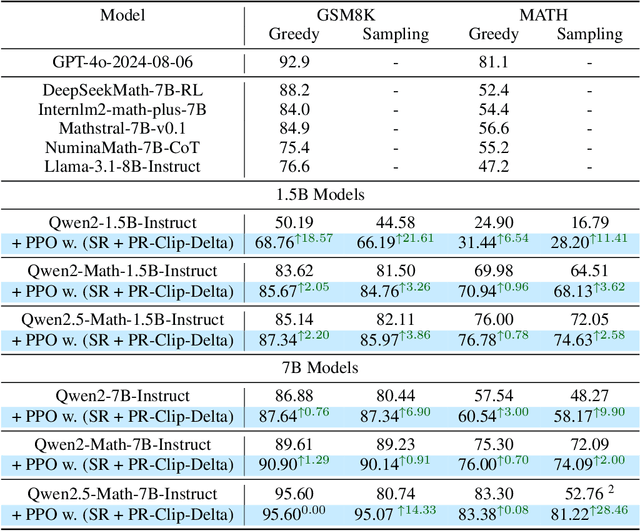
Reward models have been increasingly critical for improving the reasoning capability of LLMs. Existing research has shown that a well-trained reward model can substantially improve model performances at inference time via search. However, the potential of reward models during RL training time still remains largely under-explored. It is currently unclear whether these reward models can provide additional training signals to enhance the reasoning capabilities of LLMs in RL training that uses sparse success rewards, which verify the correctness of solutions. In this work, we evaluate popular reward models for RL training, including the Outcome-supervised Reward Model (ORM) and the Process-supervised Reward Model (PRM), and train a collection of LLMs for math problems using RL by combining these learned rewards with success rewards. Surprisingly, even though these learned reward models have strong inference-time performances, they may NOT help or even hurt RL training, producing worse performances than LLMs trained with the success reward only. Our analysis reveals that an LLM can receive high rewards from some of these reward models by repeating correct but unnecessary reasoning steps, leading to a severe reward hacking issue. Therefore, we introduce two novel reward refinement techniques, including Clipping and Delta. The key idea is to ensure the accumulative reward of any reasoning trajectory is upper-bounded to keep a learned reward model effective without being exploited. We evaluate our techniques with multiple reward models over a set of 1.5B and 7B LLMs on MATH and GSM8K benchmarks and demonstrate that with a carefully designed reward function, RL training without any additional supervised tuning can improve all the evaluated LLMs, including the state-of-the-art 7B LLM Qwen2.5-Math-7B-Instruct on MATH and GSM8K benchmarks.
Is DPO Superior to PPO for LLM Alignment? A Comprehensive Study
Apr 16, 2024



Reinforcement Learning from Human Feedback (RLHF) is currently the most widely used method to align large language models (LLMs) with human preferences. Existing RLHF methods can be roughly categorized as either reward-based or reward-free. Novel applications such as ChatGPT and Claude leverage reward-based methods that first learn a reward model and apply actor-critic algorithms, such as Proximal Policy Optimization (PPO). However, in academic benchmarks, state-of-the-art results are often achieved via reward-free methods, such as Direct Preference Optimization (DPO). Is DPO truly superior to PPO? Why does PPO perform poorly on these benchmarks? In this paper, we first conduct both theoretical and empirical studies on the algorithmic properties of DPO and show that DPO may have fundamental limitations. Moreover, we also comprehensively examine PPO and reveal the key factors for the best performances of PPO in fine-tuning LLMs. Finally, we benchmark DPO and PPO across various a collection of RLHF testbeds, ranging from dialogue to code generation. Experiment results demonstrate that PPO is able to surpass other alignment methods in all cases and achieve state-of-the-art results in challenging code competitions.
Learning Zero-Shot Cooperation with Humans, Assuming Humans Are Biased
Feb 03, 2023



There is a recent trend of applying multi-agent reinforcement learning (MARL) to train an agent that can cooperate with humans in a zero-shot fashion without using any human data. The typical workflow is to first repeatedly run self-play (SP) to build a policy pool and then train the final adaptive policy against this pool. A crucial limitation of this framework is that every policy in the pool is optimized w.r.t. the environment reward function, which implicitly assumes that the testing partners of the adaptive policy will be precisely optimizing the same reward function as well. However, human objectives are often substantially biased according to their own preferences, which can differ greatly from the environment reward. We propose a more general framework, Hidden-Utility Self-Play (HSP), which explicitly models human biases as hidden reward functions in the self-play objective. By approximating the reward space as linear functions, HSP adopts an effective technique to generate an augmented policy pool with biased policies. We evaluate HSP on the Overcooked benchmark. Empirical results show that our HSP method produces higher rewards than baselines when cooperating with learned human models, manually scripted policies, and real humans. The HSP policy is also rated as the most assistive policy based on human feedback.
Multi-Agent Vulnerability Discovery for Autonomous Driving with Hazard Arbitration Reward
Dec 12, 2021
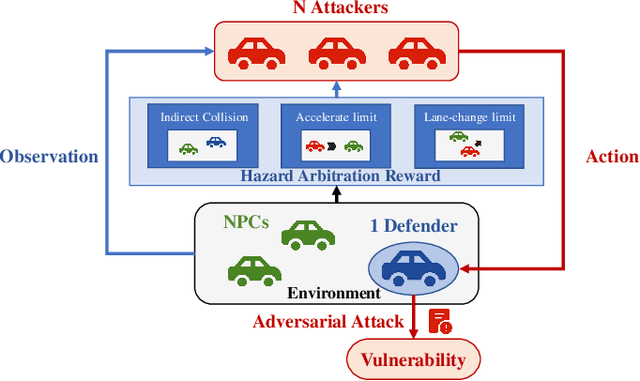

Discovering hazardous scenarios is crucial in testing and further improving driving policies. However, conducting efficient driving policy testing faces two key challenges. On the one hand, the probability of naturally encountering hazardous scenarios is low when testing a well-trained autonomous driving strategy. Thus, discovering these scenarios by purely real-world road testing is extremely costly. On the other hand, a proper determination of accident responsibility is necessary for this task. Collecting scenarios with wrong-attributed responsibilities will lead to an overly conservative autonomous driving strategy. To be more specific, we aim to discover hazardous scenarios that are autonomous-vehicle responsible (AV-responsible), i.e., the vulnerabilities of the under-test driving policy. To this end, this work proposes a Safety Test framework by finding Av-Responsible Scenarios (STARS) based on multi-agent reinforcement learning. STARS guides other traffic participants to produce Av-Responsible Scenarios and make the under-test driving policy misbehave via introducing Hazard Arbitration Reward (HAR). HAR enables our framework to discover diverse, complex, and AV-responsible hazardous scenarios. Experimental results against four different driving policies in three environments demonstrate that STARS can effectively discover AV-responsible hazardous scenarios. These scenarios indeed correspond to the vulnerabilities of the under-test driving policies, thus are meaningful for their further improvements.