 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGallant: Voxel Grid-based Humanoid Locomotion and Local-navigation across 3D Constrained Terrains
Nov 18, 2025Robust humanoid locomotion requires accurate and globally consistent perception of the surrounding 3D environment. However, existing perception modules, mainly based on depth images or elevation maps, offer only partial and locally flattened views of the environment, failing to capture the full 3D structure. This paper presents Gallant, a voxel-grid-based framework for humanoid locomotion and local navigation in 3D constrained terrains. It leverages voxelized LiDAR data as a lightweight and structured perceptual representation, and employs a z-grouped 2D CNN to map this representation to the control policy, enabling fully end-to-end optimization. A high-fidelity LiDAR simulation that dynamically generates realistic observations is developed to support scalable, LiDAR-based training and ensure sim-to-real consistency. Experimental results show that Gallant's broader perceptual coverage facilitates the use of a single policy that goes beyond the limitations of previous methods confined to ground-level obstacles, extending to lateral clutter, overhead constraints, multi-level structures, and narrow passages. Gallant also firstly achieves near 100% success rates in challenging scenarios such as stair climbing and stepping onto elevated platforms through improved end-to-end optimization.
MoE-DP: An MoE-Enhanced Diffusion Policy for Robust Long-Horizon Robotic Manipulation with Skill Decomposition and Failure Recovery
Nov 07, 2025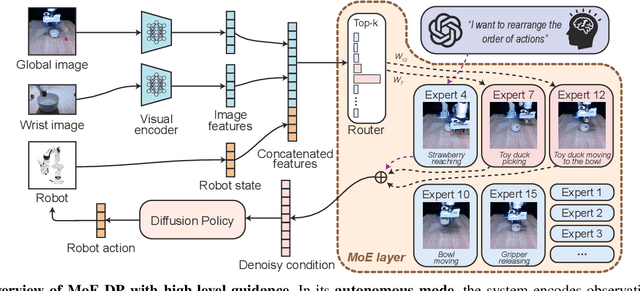
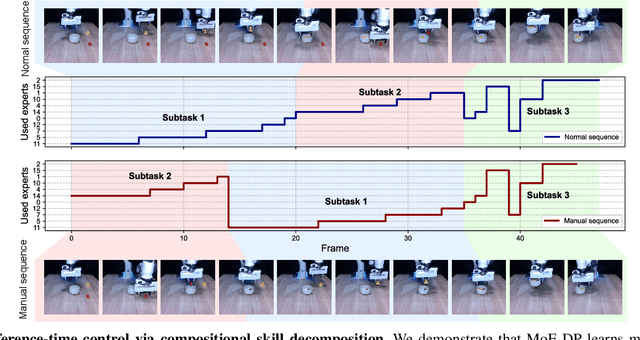
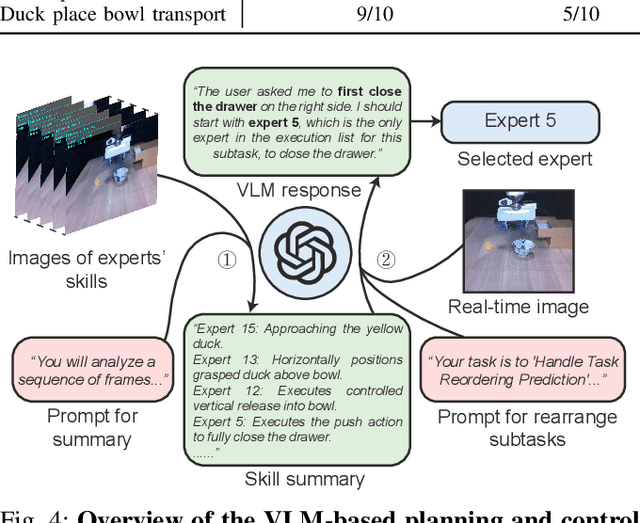
Diffusion policies have emerged as a powerful framework for robotic visuomotor control, yet they often lack the robustness to recover from subtask failures in long-horizon, multi-stage tasks and their learned representations of observations are often difficult to interpret. In this work, we propose the Mixture of Experts-Enhanced Diffusion Policy (MoE-DP), where the core idea is to insert a Mixture of Experts (MoE) layer between the visual encoder and the diffusion model. This layer decomposes the policy's knowledge into a set of specialized experts, which are dynamically activated to handle different phases of a task. We demonstrate through extensive experiments that MoE-DP exhibits a strong capability to recover from disturbances, significantly outperforming standard baselines in robustness. On a suite of 6 long-horizon simulation tasks, this leads to a 36% average relative improvement in success rate under disturbed conditions. This enhanced robustness is further validated in the real world, where MoE-DP also shows significant performance gains. We further show that MoE-DP learns an interpretable skill decomposition, where distinct experts correspond to semantic task primitives (e.g., approaching, grasping). This learned structure can be leveraged for inference-time control, allowing for the rearrangement of subtasks without any re-training.Our video and code are available at the https://moe-dp-website.github.io/MoE-DP-Website/.
FACET: Force-Adaptive Control via Impedance Reference Tracking for Legged Robots
May 11, 2025Reinforcement learning (RL) has made significant strides in legged robot control, enabling locomotion across diverse terrains and complex loco-manipulation capabilities. However, the commonly used position or velocity tracking-based objectives are agnostic to forces experienced by the robot, leading to stiff and potentially dangerous behaviors and poor control during forceful interactions. To address this limitation, we present \emph{Force-Adaptive Control via Impedance Reference Tracking} (FACET). Inspired by impedance control, we use RL to train a control policy to imitate a virtual mass-spring-damper system, allowing fine-grained control under external forces by manipulating the virtual spring. In simulation, we demonstrate that our quadruped robot achieves improved robustness to large impulses (up to 200 Ns) and exhibits controllable compliance, achieving an 80% reduction in collision impulse. The policy is deployed to a physical robot to showcase both compliance and the ability to engage with large forces by kinesthetic control and pulling payloads up to 2/3 of its weight. Further extension to a legged loco-manipulator and a humanoid shows the applicability of our method to more complex settings to enable whole-body compliance control. Project Website: https://egalahad.github.io/facet/
ArtFormer: Controllable Generation of Diverse 3D Articulated Objects
Dec 10, 2024This paper presents a novel framework for modeling and conditional generation of 3D articulated objects. Troubled by flexibility-quality tradeoffs, existing methods are often limited to using predefined structures or retrieving shapes from static datasets. To address these challenges, we parameterize an articulated object as a tree of tokens and employ a transformer to generate both the object's high-level geometry code and its kinematic relations. Subsequently, each sub-part's geometry is further decoded using a signed-distance-function (SDF) shape prior, facilitating the synthesis of high-quality 3D shapes. Our approach enables the generation of diverse objects with high-quality geometry and varying number of parts. Comprehensive experiments on conditional generation from text descriptions demonstrate the effectiveness and flexibility of our method.
Multi-UAV Behavior-based Formation with Static and Dynamic Obstacles Avoidance via Reinforcement Learning
Oct 24, 2024



Formation control of multiple Unmanned Aerial Vehicles (UAVs) is vital for practical applications. This paper tackles the task of behavior-based UAV formation while avoiding static and dynamic obstacles during directed flight. We present a two-stage reinforcement learning (RL) training pipeline to tackle the challenge of multi-objective optimization, large exploration spaces, and the sim-to-real gap. The first stage searches in a simplified scenario for a linear utility function that balances all task objectives simultaneously, whereas the second stage applies the utility function in complex scenarios, utilizing curriculum learning to navigate large exploration spaces. Additionally, we apply an attention-based observation encoder to enhance formation maintenance and manage varying obstacle quantity. Experiments in simulation and real world demonstrate that our method outperforms planning-based and RL-based baselines regarding collision-free rate and formation maintenance in scenarios with static, dynamic, and mixed obstacles.
On the Evaluation of Generative Robotic Simulations
Oct 10, 2024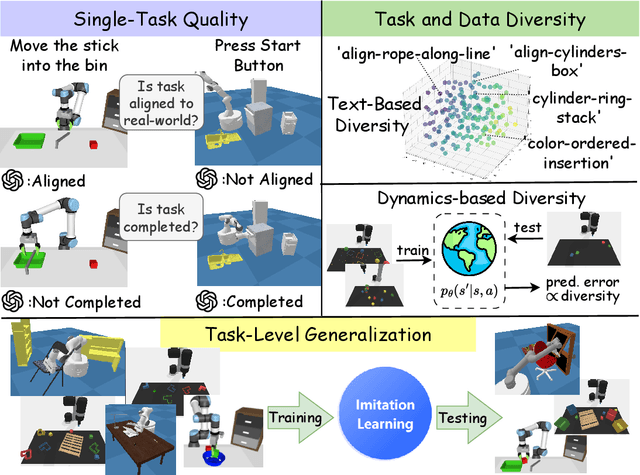
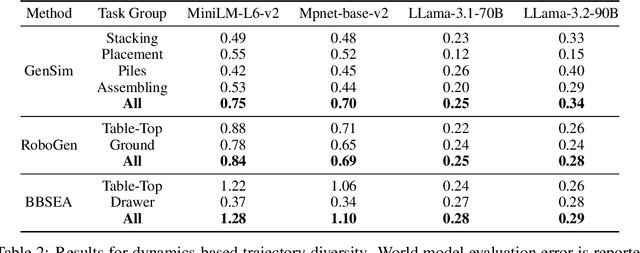
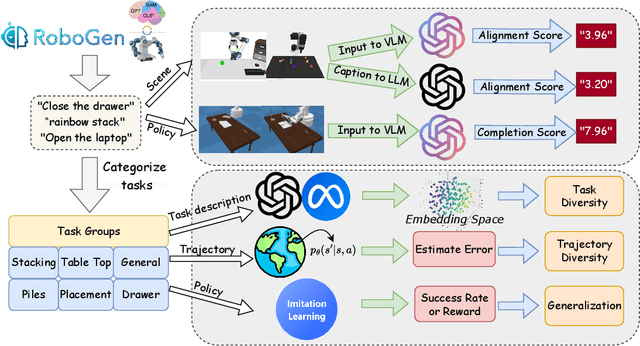
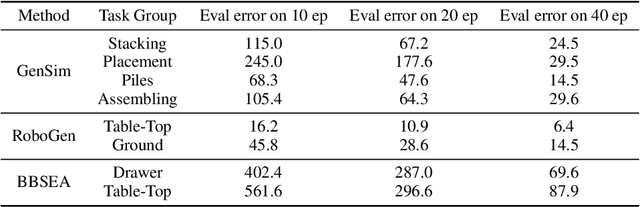
Due to the difficulty of acquiring extensive real-world data, robot simulation has become crucial for parallel training and sim-to-real transfer, highlighting the importance of scalable simulated robotic tasks. Foundation models have demonstrated impressive capacities in autonomously generating feasible robotic tasks. However, this new paradigm underscores the challenge of adequately evaluating these autonomously generated tasks. To address this, we propose a comprehensive evaluation framework tailored to generative simulations. Our framework segments evaluation into three core aspects: quality, diversity, and generalization. For single-task quality, we evaluate the realism of the generated task and the completeness of the generated trajectories using large language models and vision-language models. In terms of diversity, we measure both task and data diversity through text similarity of task descriptions and world model loss trained on collected task trajectories. For task-level generalization, we assess the zero-shot generalization ability on unseen tasks of a policy trained with multiple generated tasks. Experiments conducted on three representative task generation pipelines demonstrate that the results from our framework are highly consistent with human evaluations, confirming the feasibility and validity of our approach. The findings reveal that while metrics of quality and diversity can be achieved through certain methods, no single approach excels across all metrics, suggesting a need for greater focus on balancing these different metrics. Additionally, our analysis further highlights the common challenge of low generalization capability faced by current works. Our anonymous website: https://sites.google.com/view/evaltasks.
Multi-UAV Pursuit-Evasion with Online Planning in Unknown Environments by Deep Reinforcement Learning
Sep 25, 2024



Multi-UAV pursuit-evasion, where pursuers aim to capture evaders, poses a key challenge for UAV swarm intelligence. Multi-agent reinforcement learning (MARL) has demonstrated potential in modeling cooperative behaviors, but most RL-based approaches remain constrained to simplified simulations with limited dynamics or fixed scenarios. Previous attempts to deploy RL policy to real-world pursuit-evasion are largely restricted to two-dimensional scenarios, such as ground vehicles or UAVs at fixed altitudes. In this paper, we address multi-UAV pursuit-evasion by considering UAV dynamics and physical constraints. We introduce an evader prediction-enhanced network to tackle partial observability in cooperative strategy learning. Additionally, we propose an adaptive environment generator within MARL training, enabling higher exploration efficiency and better policy generalization across diverse scenarios. Simulations show our method significantly outperforms all baselines in challenging scenarios, generalizing to unseen scenarios with a 100% capture rate. Finally, we derive a feasible policy via a two-stage reward refinement and deploy the policy on real quadrotors in a zero-shot manner. To our knowledge, this is the first work to derive and deploy an RL-based policy using collective thrust and body rates control commands for multi-UAV pursuit-evasion in unknown environments. The open-source code and videos are available at https://sites.google.com/view/pursuit-evasion-rl.
Improving Detection in Aerial Images by Capturing Inter-Object Relationships
Apr 05, 2024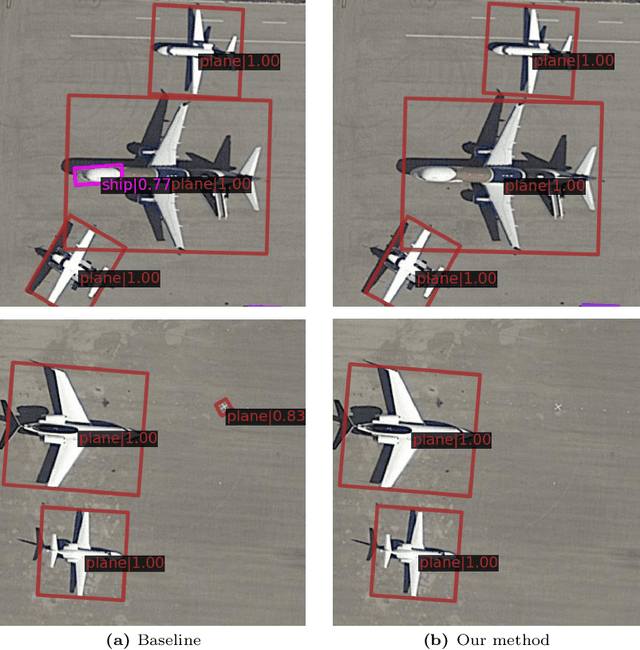

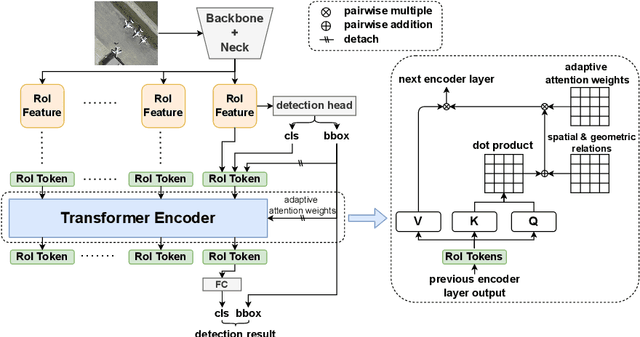

In many image domains, the spatial distribution of objects in a scene exhibits meaningful patterns governed by their semantic relationships. In most modern detection pipelines, however, the detection proposals are processed independently, overlooking the underlying relationships between objects. In this work, we introduce a transformer-based approach to capture these inter-object relationships to refine classification and regression outcomes for detected objects. Building on two-stage detectors, we tokenize the region of interest (RoI) proposals to be processed by a transformer encoder. Specific spatial and geometric relations are incorporated into the attention weights and adaptively modulated and regularized. Experimental results demonstrate that the proposed method achieves consistent performance improvement on three benchmarks including DOTA-v1.0, DOTA-v1.5, and HRSC 2016, especially ranking first on both DOTA-v1.5 and HRSC 2016. Specifically, our new method has an increase of 1.59 mAP on DOTA-v1.0, 4.88 mAP on DOTA-v1.5, and 2.1 mAP on HRSC 2016, respectively, compared to the baselines.
TaskFlex Solver for Multi-Agent Pursuit via Automatic Curriculum Learning
Dec 19, 2023



This paper addresses the problem of multi-agent pursuit, where slow pursuers cooperate to capture fast evaders in a confined environment with obstacles. Existing heuristic algorithms often lack expressive coordination strategies and are highly sensitive to task conditions, requiring extensive hyperparameter tuning. In contrast, reinforcement learning (RL) has been applied to this problem and is capable of obtaining cooperative pursuit strategies. However, RL-based methods face challenges in training for complex scenarios due to the vast amount of training data and limited adaptability to varying task conditions, such as different scene sizes, varying numbers and speeds of obstacles, and flexible speed ratios of the evader to the pursuer. In this work, we combine RL and curriculum learning to introduce a flexible solver for multiagent pursuit problems, named TaskFlex Solver (TFS), which is capable of solving multi-agent pursuit problems with diverse and dynamically changing task conditions in both 2-dimensional and 3-dimensional scenarios. TFS utilizes a curriculum learning method that constructs task distributions based on training progress, enhancing training efficiency and final performance. Our algorithm consists of two main components: the Task Evaluator, which evaluates task success rates and selects tasks of moderate difficulty to maintain a curriculum archive, and the Task Sampler, which constructs training distributions by sampling tasks from the curriculum archive to maximize policy improvement. Experiments show that TFS produces much stronger performance than baselines and achieves close to 100% capture rates in both 2-dimensional and 3-dimensional multi-agent pursuit problems with diverse and dynamically changing scenes. The project website is at https://sites.google.com/view/tfs-2023.
Feedback RoI Features Improve Aerial Object Detection
Nov 28, 2023



Neuroscience studies have shown that the human visual system utilizes high-level feedback information to guide lower-level perception, enabling adaptation to signals of different characteristics. In light of this, we propose Feedback multi-Level feature Extractor (Flex) to incorporate a similar mechanism for object detection. Flex refines feature selection based on image-wise and instance-level feedback information in response to image quality variation and classification uncertainty. Experimental results show that Flex offers consistent improvement to a range of existing SOTA methods on the challenging aerial object detection datasets including DOTA-v1.0, DOTA-v1.5, and HRSC2016. Although the design originates in aerial image detection, further experiments on MS COCO also reveal our module's efficacy in general detection models. Quantitative and qualitative analyses indicate that the improvements are closely related to image qualities, which match our motivation.