 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Evaluation of Generative Robotic Simulations
Paper and Code
Oct 10, 2024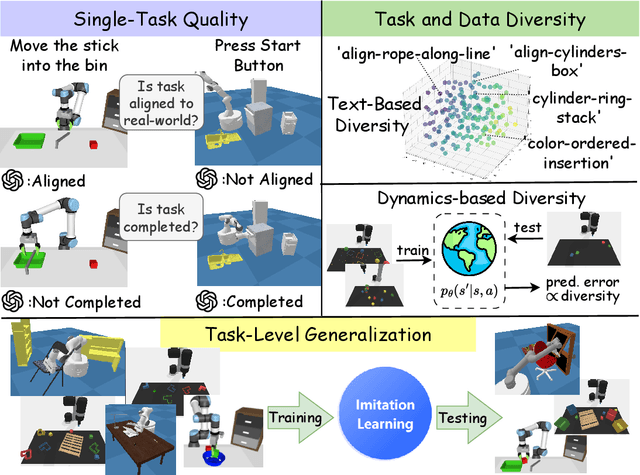
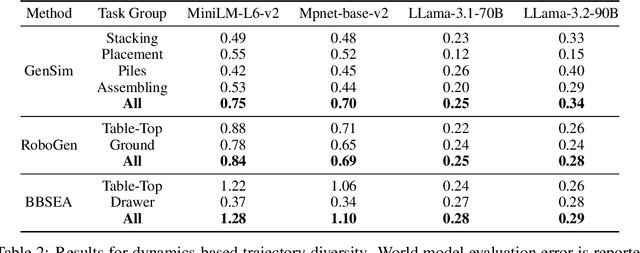
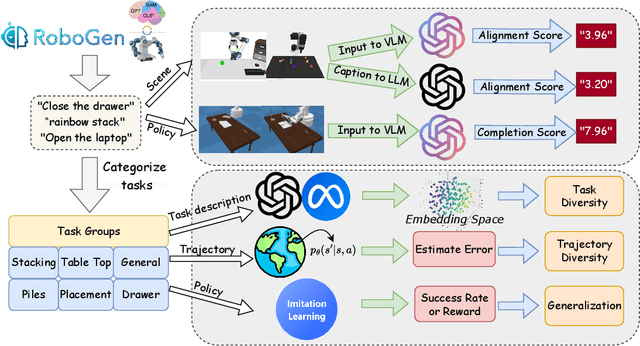
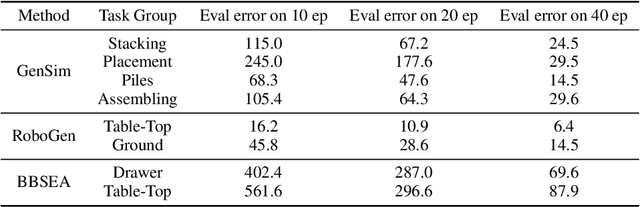
Due to the difficulty of acquiring extensive real-world data, robot simulation has become crucial for parallel training and sim-to-real transfer, highlighting the importance of scalable simulated robotic tasks. Foundation models have demonstrated impressive capacities in autonomously generating feasible robotic tasks. However, this new paradigm underscores the challenge of adequately evaluating these autonomously generated tasks. To address this, we propose a comprehensive evaluation framework tailored to generative simulations. Our framework segments evaluation into three core aspects: quality, diversity, and generalization. For single-task quality, we evaluate the realism of the generated task and the completeness of the generated trajectories using large language models and vision-language models. In terms of diversity, we measure both task and data diversity through text similarity of task descriptions and world model loss trained on collected task trajectories. For task-level generalization, we assess the zero-shot generalization ability on unseen tasks of a policy trained with multiple generated tasks. Experiments conducted on three representative task generation pipelines demonstrate that the results from our framework are highly consistent with human evaluations, confirming the feasibility and validity of our approach. The findings reveal that while metrics of quality and diversity can be achieved through certain methods, no single approach excels across all metrics, suggesting a need for greater focus on balancing these different metrics. Additionally, our analysis further highlights the common challenge of low generalization capability faced by current works. Our anonymous website: https://sites.google.com/view/evaltasks.