 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDark-EvGS: Event Camera as an Eye for Radiance Field in the Dark
Jul 16, 2025



In low-light environments, conventional cameras often struggle to capture clear multi-view images of objects due to dynamic range limitations and motion blur caused by long exposure. Event cameras, with their high-dynamic range and high-speed properties, have the potential to mitigate these issues. Additionally, 3D Gaussian Splatting (GS) enables radiance field reconstruction, facilitating bright frame synthesis from multiple viewpoints in low-light conditions. However, naively using an event-assisted 3D GS approach still faced challenges because, in low light, events are noisy, frames lack quality, and the color tone may be inconsistent. To address these issues, we propose Dark-EvGS, the first event-assisted 3D GS framework that enables the reconstruction of bright frames from arbitrary viewpoints along the camera trajectory. Triplet-level supervision is proposed to gain holistic knowledge, granular details, and sharp scene rendering. The color tone matching block is proposed to guarantee the color consistency of the rendered frames. Furthermore, we introduce the first real-captured dataset for the event-guided bright frame synthesis task via 3D GS-based radiance field reconstruction. Experiments demonstrate that our method achieves better results than existing methods, conquering radiance field reconstruction under challenging low-light conditions. The code and sample data are included in the supplementary material.
NTIRE 2025 Challenge on Event-Based Image Deblurring: Methods and Results
Apr 16, 2025This paper presents an overview of NTIRE 2025 the First Challenge on Event-Based Image Deblurring, detailing the proposed methodologies and corresponding results. The primary goal of the challenge is to design an event-based method that achieves high-quality image deblurring, with performance quantitatively assessed using Peak Signal-to-Noise Ratio (PSNR). Notably, there are no restrictions on computational complexity or model size. The task focuses on leveraging both events and images as inputs for single-image deblurring. A total of 199 participants registered, among whom 15 teams successfully submitted valid results, offering valuable insights into the current state of event-based image deblurring. We anticipate that this challenge will drive further advancements in event-based vision research.
On the Evaluation of Generative Robotic Simulations
Oct 10, 2024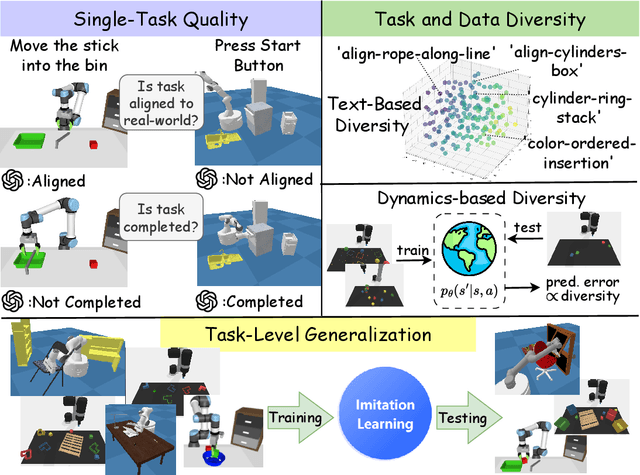
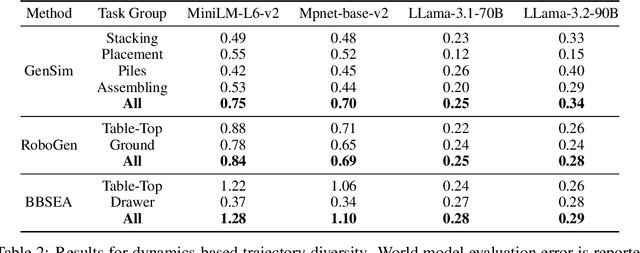
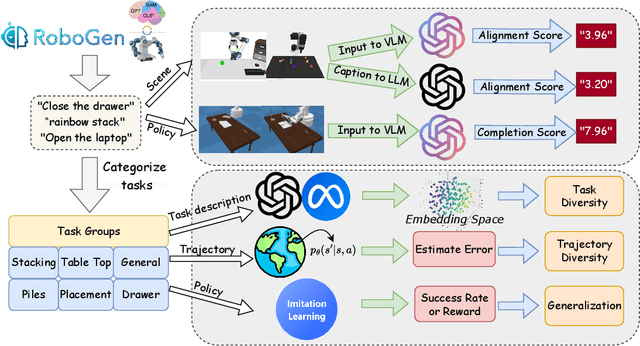
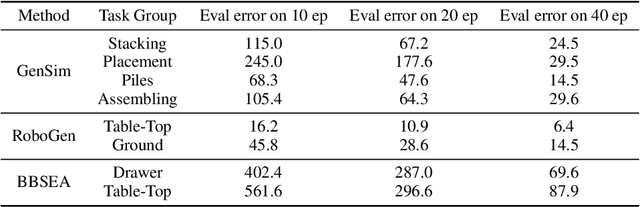
Due to the difficulty of acquiring extensive real-world data, robot simulation has become crucial for parallel training and sim-to-real transfer, highlighting the importance of scalable simulated robotic tasks. Foundation models have demonstrated impressive capacities in autonomously generating feasible robotic tasks. However, this new paradigm underscores the challenge of adequately evaluating these autonomously generated tasks. To address this, we propose a comprehensive evaluation framework tailored to generative simulations. Our framework segments evaluation into three core aspects: quality, diversity, and generalization. For single-task quality, we evaluate the realism of the generated task and the completeness of the generated trajectories using large language models and vision-language models. In terms of diversity, we measure both task and data diversity through text similarity of task descriptions and world model loss trained on collected task trajectories. For task-level generalization, we assess the zero-shot generalization ability on unseen tasks of a policy trained with multiple generated tasks. Experiments conducted on three representative task generation pipelines demonstrate that the results from our framework are highly consistent with human evaluations, confirming the feasibility and validity of our approach. The findings reveal that while metrics of quality and diversity can be achieved through certain methods, no single approach excels across all metrics, suggesting a need for greater focus on balancing these different metrics. Additionally, our analysis further highlights the common challenge of low generalization capability faced by current works. Our anonymous website: https://sites.google.com/view/evaltasks.
EvPlug: Learn a Plug-and-Play Module for Event and Image Fusion
Dec 28, 2023Event cameras and RGB cameras exhibit complementary characteristics in imaging: the former possesses high dynamic range (HDR) and high temporal resolution, while the latter provides rich texture and color information. This makes the integration of event cameras into middle- and high-level RGB-based vision tasks highly promising. However, challenges arise in multi-modal fusion, data annotation, and model architecture design. In this paper, we propose EvPlug, which learns a plug-and-play event and image fusion module from the supervision of the existing RGB-based model. The learned fusion module integrates event streams with image features in the form of a plug-in, endowing the RGB-based model to be robust to HDR and fast motion scenes while enabling high temporal resolution inference. Our method only requires unlabeled event-image pairs (no pixel-wise alignment required) and does not alter the structure or weights of the RGB-based model. We demonstrate the superiority of EvPlug in several vision tasks such as object detection, semantic segmentation, and 3D hand pose estimation
EventAid: Benchmarking Event-aided Image/Video Enhancement Algorithms with Real-captured Hybrid Dataset
Dec 13, 2023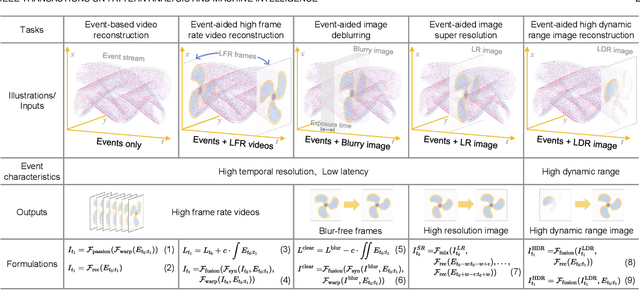



Event cameras are emerging imaging technology that offers advantages over conventional frame-based imaging sensors in dynamic range and sensing speed. Complementing the rich texture and color perception of traditional image frames, the hybrid camera system of event and frame-based cameras enables high-performance imaging. With the assistance of event cameras, high-quality image/video enhancement methods make it possible to break the limits of traditional frame-based cameras, especially exposure time, resolution, dynamic range, and frame rate limits. This paper focuses on five event-aided image and video enhancement tasks (i.e., event-based video reconstruction, event-aided high frame rate video reconstruction, image deblurring, image super-resolution, and high dynamic range image reconstruction), provides an analysis of the effects of different event properties, a real-captured and ground truth labeled benchmark dataset, a unified benchmarking of state-of-the-art methods, and an evaluation for two mainstream event simulators. In detail, this paper collects a real-captured evaluation dataset EventAid for five event-aided image/video enhancement tasks, by using "Event-RGB" multi-camera hybrid system, taking into account scene diversity and spatiotemporal synchronization. We further perform quantitative and visual comparisons for state-of-the-art algorithms, provide a controlled experiment to analyze the performance limit of event-aided image deblurring methods, and discuss open problems to inspire future research.