 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved Algorithms for Differentially Private Language Model Alignment
May 13, 2025Language model alignment is crucial for ensuring that large language models (LLMs) align with human preferences, yet it often involves sensitive user data, raising significant privacy concerns. While prior work has integrated differential privacy (DP) with alignment techniques, their performance remains limited. In this paper, we propose novel algorithms for privacy-preserving alignment and rigorously analyze their effectiveness across varying privacy budgets and models. Our framework can be deployed on two celebrated alignment techniques, namely direct preference optimization (DPO) and reinforcement learning from human feedback (RLHF). Through systematic experiments on large-scale language models, we demonstrate that our approach achieves state-of-the-art performance. Notably, one of our algorithms, DP-AdamW, combined with DPO, surpasses existing methods, improving alignment quality by up to 15% under moderate privacy budgets ({\epsilon}=2-5). We further investigate the interplay between privacy guarantees, alignment efficacy, and computational demands, providing practical guidelines for optimizing these trade-offs.
NTIRE 2025 Challenge on Event-Based Image Deblurring: Methods and Results
Apr 16, 2025This paper presents an overview of NTIRE 2025 the First Challenge on Event-Based Image Deblurring, detailing the proposed methodologies and corresponding results. The primary goal of the challenge is to design an event-based method that achieves high-quality image deblurring, with performance quantitatively assessed using Peak Signal-to-Noise Ratio (PSNR). Notably, there are no restrictions on computational complexity or model size. The task focuses on leveraging both events and images as inputs for single-image deblurring. A total of 199 participants registered, among whom 15 teams successfully submitted valid results, offering valuable insights into the current state of event-based image deblurring. We anticipate that this challenge will drive further advancements in event-based vision research.
Progressive Limb-Aware Virtual Try-On
Mar 16, 2025Existing image-based virtual try-on methods directly transfer specific clothing to a human image without utilizing clothing attributes to refine the transferred clothing geometry and textures, which causes incomplete and blurred clothing appearances. In addition, these methods usually mask the limb textures of the input for the clothing-agnostic person representation, which results in inaccurate predictions for human limb regions (i.e., the exposed arm skin), especially when transforming between long-sleeved and short-sleeved garments. To address these problems, we present a progressive virtual try-on framework, named PL-VTON, which performs pixel-level clothing warping based on multiple attributes of clothing and embeds explicit limb-aware features to generate photo-realistic try-on results. Specifically, we design a Multi-attribute Clothing Warping (MCW) module that adopts a two-stage alignment strategy based on multiple attributes to progressively estimate pixel-level clothing displacements. A Human Parsing Estimator (HPE) is then introduced to semantically divide the person into various regions, which provides structural constraints on the human body and therefore alleviates texture bleeding between clothing and limb regions. Finally, we propose a Limb-aware Texture Fusion (LTF) module to estimate high-quality details in limb regions by fusing textures of the clothing and the human body with the guidance of explicit limb-aware features. Extensive experiments demonstrate that our proposed method outperforms the state-of-the-art virtual try-on methods both qualitatively and quantitatively. The code is available at https://github.com/xyhanHIT/PL-VTON.
Path-Adaptive Matting for Efficient Inference Under Various Computational Cost Constraints
Mar 05, 2025



In this paper, we explore a novel image matting task aimed at achieving efficient inference under various computational cost constraints, specifically FLOP limitations, using a single matting network. Existing matting methods which have not explored scalable architectures or path-learning strategies, fail to tackle this challenge. To overcome these limitations, we introduce Path-Adaptive Matting (PAM), a framework that dynamically adjusts network paths based on image contexts and computational cost constraints. We formulate the training of the computational cost-constrained matting network as a bilevel optimization problem, jointly optimizing the matting network and the path estimator. Building on this formalization, we design a path-adaptive matting architecture by incorporating path selection layers and learnable connect layers to estimate optimal paths and perform efficient inference within a unified network. Furthermore, we propose a performance-aware path-learning strategy to generate path labels online by evaluating a few paths sampled from the prior distribution of optimal paths and network estimations, enabling robust and efficient online path learning. Experiments on five image matting datasets demonstrate that the proposed PAM framework achieves competitive performance across a range of computational cost constraints.
Technique Report of CVPR 2024 PBDL Challenges
Jun 15, 2024



The intersection of physics-based vision and deep learning presents an exciting frontier for advancing computer vision technologies. By leveraging the principles of physics to inform and enhance deep learning models, we can develop more robust and accurate vision systems. Physics-based vision aims to invert the processes to recover scene properties such as shape, reflectance, light distribution, and medium properties from images. In recent years, deep learning has shown promising improvements for various vision tasks, and when combined with physics-based vision, these approaches can enhance the robustness and accuracy of vision systems. This technical report summarizes the outcomes of the Physics-Based Vision Meets Deep Learning (PBDL) 2024 challenge, held in CVPR 2024 workshop. The challenge consisted of eight tracks, focusing on Low-Light Enhancement and Detection as well as High Dynamic Range (HDR) Imaging. This report details the objectives, methodologies, and results of each track, highlighting the top-performing solutions and their innovative approaches.
P-MSDiff: Parallel Multi-Scale Diffusion for Remote Sensing Image Segmentation
May 30, 2024



Diffusion models and multi-scale features are essential components in semantic segmentation tasks that deal with remote-sensing images. They contribute to improved segmentation boundaries and offer significant contextual information. U-net-like architectures are frequently employed in diffusion models for segmentation tasks. These architectural designs include dense skip connections that may pose challenges for interpreting intermediate features. Consequently, they might not efficiently convey semantic information throughout various layers of the encoder-decoder architecture. To address these challenges, we propose a new model for semantic segmentation known as the diffusion model with parallel multi-scale branches. This model consists of Parallel Multiscale Diffusion modules (P-MSDiff) and a Cross-Bridge Linear Attention mechanism (CBLA). P-MSDiff enhances the understanding of semantic information across multiple levels of granularity and detects repetitive distribution data through the integration of recursive denoising branches. It further facilitates the amalgamation of data by connecting relevant branches to the primary framework to enable concurrent denoising. Furthermore, within the interconnected transformer architecture, the LA module has been substituted with the CBLA module. This module integrates a semidefinite matrix linked to the query into the dot product computation of keys and values. This integration enables the adaptation of queries within the LA framework. This adjustment enhances the structure for multi-head attention computation, leading to enhanced network performance and CBLA is a plug-and-play module. Our model demonstrates superior performance based on the J1 metric on both the UAVid and Vaihingen Building datasets, showing improvements of 1.60% and 1.40% over strong baseline models, respectively.
End-to-End Human Instance Matting
Mar 03, 2024



Human instance matting aims to estimate an alpha matte for each human instance in an image, which is extremely challenging and has rarely been studied so far. Despite some efforts to use instance segmentation to generate a trimap for each instance and apply trimap-based matting methods, the resulting alpha mattes are often inaccurate due to inaccurate segmentation. In addition, this approach is computationally inefficient due to multiple executions of the matting method. To address these problems, this paper proposes a novel End-to-End Human Instance Matting (E2E-HIM) framework for simultaneous multiple instance matting in a more efficient manner. Specifically, a general perception network first extracts image features and decodes instance contexts into latent codes. Then, a united guidance network exploits spatial attention and semantics embedding to generate united semantics guidance, which encodes the locations and semantic correspondences of all instances. Finally, an instance matting network decodes the image features and united semantics guidance to predict all instance-level alpha mattes. In addition, we construct a large-scale human instance matting dataset (HIM-100K) comprising over 100,000 human images with instance alpha matte labels. Experiments on HIM-100K demonstrate the proposed E2E-HIM outperforms the existing methods on human instance matting with 50% lower errors and 5X faster speed (6 instances in a 640X640 image). Experiments on the PPM-100, RWP-636, and P3M datasets demonstrate that E2E-HIM also achieves competitive performance on traditional human matting.
Dual-Context Aggregation for Universal Image Matting
Feb 28, 2024Natural image matting aims to estimate the alpha matte of the foreground from a given image. Various approaches have been explored to address this problem, such as interactive matting methods that use guidance such as click or trimap, and automatic matting methods tailored to specific objects. However, existing matting methods are designed for specific objects or guidance, neglecting the common requirement of aggregating global and local contexts in image matting. As a result, these methods often encounter challenges in accurately identifying the foreground and generating precise boundaries, which limits their effectiveness in unforeseen scenarios. In this paper, we propose a simple and universal matting framework, named Dual-Context Aggregation Matting (DCAM), which enables robust image matting with arbitrary guidance or without guidance. Specifically, DCAM first adopts a semantic backbone network to extract low-level features and context features from the input image and guidance. Then, we introduce a dual-context aggregation network that incorporates global object aggregators and local appearance aggregators to iteratively refine the extracted context features. By performing both global contour segmentation and local boundary refinement, DCAM exhibits robustness to diverse types of guidance and objects. Finally, we adopt a matting decoder network to fuse the low-level features and the refined context features for alpha matte estimation. Experimental results on five matting datasets demonstrate that the proposed DCAM outperforms state-of-the-art matting methods in both automatic matting and interactive matting tasks, which highlights the strong universality and high performance of DCAM. The source code is available at \url{https://github.com/Windaway/DCAM}.
Rethinking Context Aggregation in Natural Image Matting
Apr 03, 2023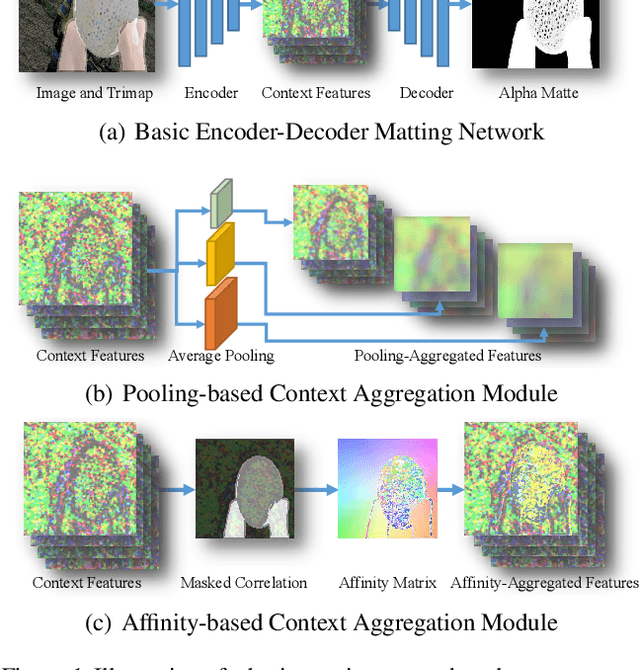
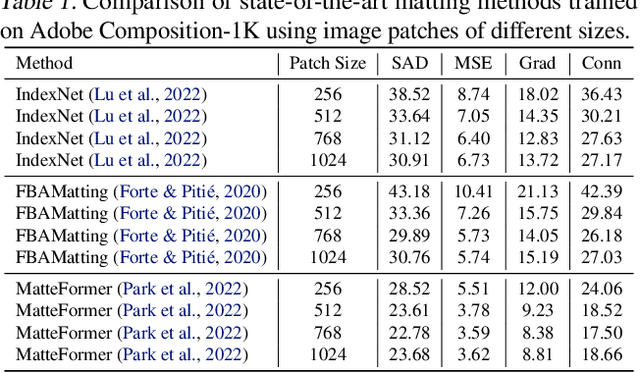
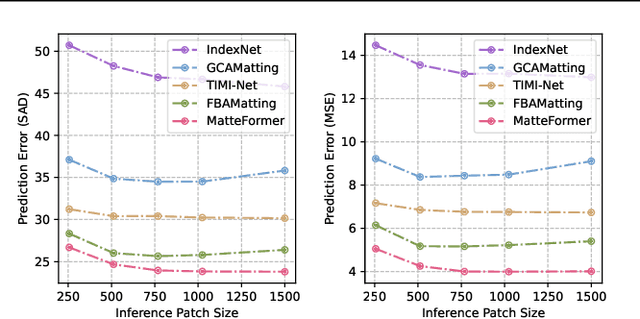
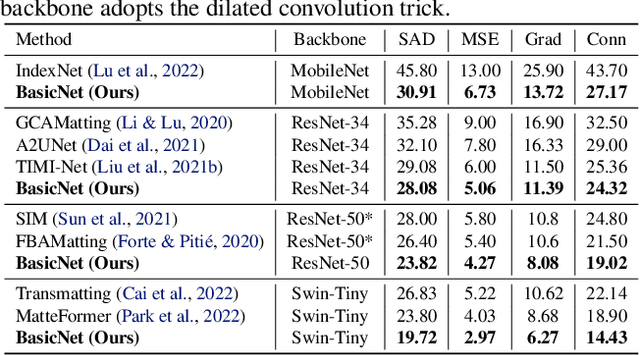
For natural image matting, context information plays a crucial role in estimating alpha mattes especially when it is challenging to distinguish foreground from its background. Exiting deep learning-based methods exploit specifically designed context aggregation modules to refine encoder features. However, the effectiveness of these modules has not been thoroughly explored. In this paper, we conduct extensive experiments to reveal that the context aggregation modules are actually not as effective as expected. We also demonstrate that when learned on large image patches, basic encoder-decoder networks with a larger receptive field can effectively aggregate context to achieve better performance.Upon the above findings, we propose a simple yet effective matting network, named AEMatter, which enlarges the receptive field by incorporating an appearance-enhanced axis-wise learning block into the encoder and adopting a hybrid-transformer decoder. Experimental results on four datasets demonstrate that our AEMatter significantly outperforms state-of-the-art matting methods (e.g., on the Adobe Composition-1K dataset, \textbf{25\%} and \textbf{40\%} reduction in terms of SAD and MSE, respectively, compared against MatteFormer). The code and model are available at \url{https://github.com/QLYoo/AEMatter}.
Long-Range Feature Propagating for Natural Image Matting
Sep 25, 2021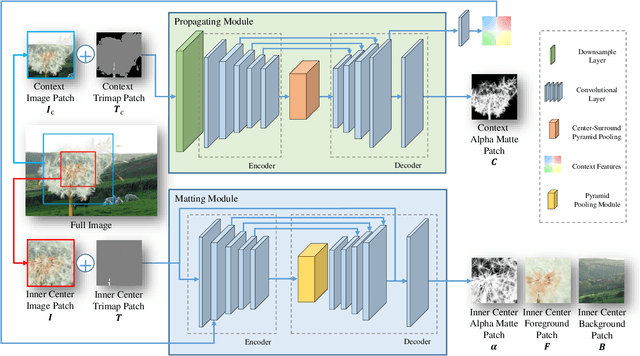
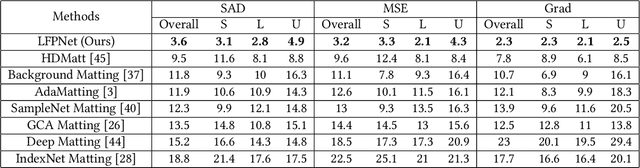
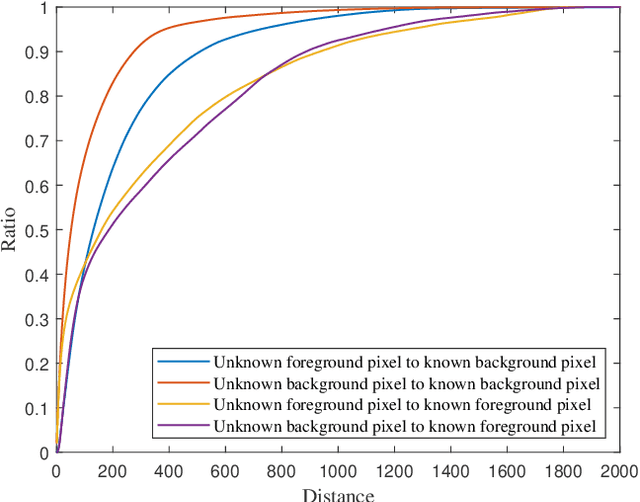
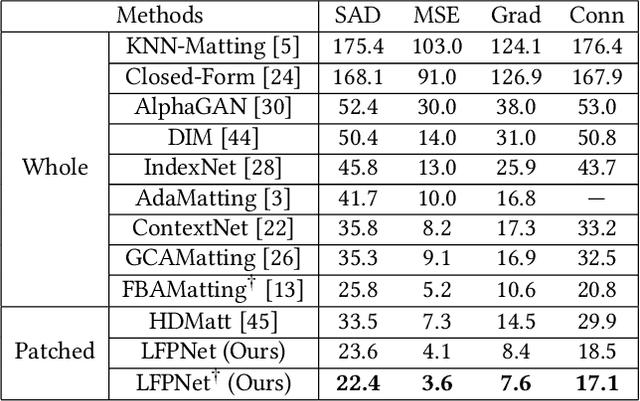
Natural image matting estimates the alpha values of unknown regions in the trimap. Recently, deep learning based methods propagate the alpha values from the known regions to unknown regions according to the similarity between them. However, we find that more than 50\% pixels in the unknown regions cannot be correlated to pixels in known regions due to the limitation of small effective reception fields of common convolutional neural networks, which leads to inaccurate estimation when the pixels in the unknown regions cannot be inferred only with pixels in the reception fields. To solve this problem, we propose Long-Range Feature Propagating Network (LFPNet), which learns the long-range context features outside the reception fields for alpha matte estimation. Specifically, we first design the propagating module which extracts the context features from the downsampled image. Then, we present Center-Surround Pyramid Pooling (CSPP) that explicitly propagates the context features from the surrounding context image patch to the inner center image patch. Finally, we use the matting module which takes the image, trimap and context features to estimate the alpha matte. Experimental results demonstrate that the proposed method performs favorably against the state-of-the-art methods on the AlphaMatting and Adobe Image Matting datasets.