 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSenseNova-U1: Unifying Multimodal Understanding and Generation with NEO-unify Architecture
May 12, 2026Recent large vision-language models (VLMs) remain fundamentally constrained by a persistent dichotomy: understanding and generation are treated as distinct problems, leading to fragmented architectures, cascaded pipelines, and misaligned representation spaces. We argue that this divide is not merely an engineering artifact, but a structural limitation that hinders the emergence of native multimodal intelligence. Hence, we introduce SenseNova-U1, a native unified multimodal paradigm built upon NEO-unify, in which understanding and generation evolve as synergistic views of a single underlying process. We launch two native unified variants, SenseNova-U1-8B-MoT and SenseNova-U1-A3B-MoT, built on dense (8B) and mixture-of-experts (30B-A3B) understanding baselines, respectively. Designed from first principles, they rival top-tier understanding-only VLMs across text understanding, vision-language perception, knowledge reasoning, agentic decision-making, and spatial intelligence. Meanwhile, they deliver strong semantic consistency and visual fidelity, excelling in conventional or knowledge-intensive any-to-image (X2I) synthesis, complex text-rich infographic generation, and interleaved vision-language generation, with or without think patterns. Beyond performance, we show detailed model design, data preprocessing, pre-/post-training, and inference strategies to support community research. Last but not least, preliminary evidence demonstrates that our models extend beyond perception and generation, performing strongly in vision-language-action (VLA) and world model (WM) scenarios. This points toward a broader roadmap where models do not translate between modalities, but think and act across them in a native manner. Multimodal AI is no longer about connecting separate systems, but about building a unified one and trusting the necessary capabilities to emerge from within.
MonoArt: Progressive Structural Reasoning for Monocular Articulated 3D Reconstruction
Mar 19, 2026Reconstructing articulated 3D objects from a single image requires jointly inferring object geometry, part structure, and motion parameters from limited visual evidence. A key difficulty lies in the entanglement between motion cues and object structure, which makes direct articulation regression unstable. Existing methods address this challenge through multi-view supervision, retrieval-based assembly, or auxiliary video generation, often sacrificing scalability or efficiency. We present MonoArt, a unified framework grounded in progressive structural reasoning. Rather than predicting articulation directly from image features, MonoArt progressively transforms visual observations into canonical geometry, structured part representations, and motion-aware embeddings within a single architecture. This structured reasoning process enables stable and interpretable articulation inference without external motion templates or multi-stage pipelines. Extensive experiments on PartNet-Mobility demonstrate that OM achieves state-of-the-art performance in both reconstruction accuracy and inference speed. The framework further generalizes to robotic manipulation and articulated scene reconstruction.
Bridging Semantic and Kinematic Conditions with Diffusion-based Discrete Motion Tokenizer
Mar 19, 2026Prior motion generation largely follows two paradigms: continuous diffusion models that excel at kinematic control, and discrete token-based generators that are effective for semantic conditioning. To combine their strengths, we propose a three-stage framework comprising condition feature extraction (Perception), discrete token generation (Planning), and diffusion-based motion synthesis (Control). Central to this framework is MoTok, a diffusion-based discrete motion tokenizer that decouples semantic abstraction from fine-grained reconstruction by delegating motion recovery to a diffusion decoder, enabling compact single-layer tokens while preserving motion fidelity. For kinematic conditions, coarse constraints guide token generation during planning, while fine-grained constraints are enforced during control through diffusion-based optimization. This design prevents kinematic details from disrupting semantic token planning. On HumanML3D, our method significantly improves controllability and fidelity over MaskControl while using only one-sixth of the tokens, reducing trajectory error from 0.72 cm to 0.08 cm and FID from 0.083 to 0.029. Unlike prior methods that degrade under stronger kinematic constraints, ours improves fidelity, reducing FID from 0.033 to 0.014.
HSImul3R: Physics-in-the-Loop Reconstruction of Simulation-Ready Human-Scene Interactions
Mar 16, 2026We present HSImul3R, a unified framework for simulation-ready 3D reconstruction of human-scene interactions (HSI) from casual captures, including sparse-view images and monocular videos. Existing methods suffer from a perception-simulation gap: visually plausible reconstructions often violate physical constraints, leading to instability in physics engines and failure in embodied AI applications. To bridge this gap, we introduce a physically-grounded bi-directional optimization pipeline that treats the physics simulator as an active supervisor to jointly refine human dynamics and scene geometry. In the forward direction, we employ Scene-targeted Reinforcement Learning to optimize human motion under dual supervision of motion fidelity and contact stability. In the reverse direction, we propose Direct Simulation Reward Optimization, which leverages simulation feedback on gravitational stability and interaction success to refine scene geometry. We further present HSIBench, a new benchmark with diverse objects and interaction scenarios. Extensive experiments demonstrate that HSImul3R produces the first stable, simulation-ready HSI reconstructions and can be directly deployed to real-world humanoid robots.
InfiniteDance: Scalable 3D Dance Generation Towards in-the-wild Generalization
Mar 10, 2026Although existing 3D dance generation methods perform well in controlled scenarios, they often struggle to generalize in the wild. When conditioned on unseen music, existing methods often produce unstructured or physically implausible dance, largely due to limited music-to-dance data and restricted model capacity. This work aims to push the frontier of generalizable 3D dance generation by scaling up both data and model design. (1) On the data side, we develop a fully automated pipeline that reconstructs high-fidelity 3D dance motions from monocular videos. To eliminate the physical artifacts prevalent in existing reconstruction methods, we introduce a Foot Restoration Diffusion Model (FRDM) guided by foot-contact and geometric constraints that enforce physical plausibility while preserving kinematic smoothness and expressiveness, resulting in a diverse, high-quality multimodal 3D dance dataset totaling 100.69 hours. (2) On model design, we propose Choreographic LLaMA (ChoreoLLaMA), a scalable LLaMA-based architecture. To enhance robustness under unfamiliar music conditions, we integrate a retrieval-augmented generation (RAG) module that injects reference dance as a prompt. Additionally, we design a slow/fast-cadence Mixture-of-Experts (MoE) module that enables ChoreoLLaMA to smoothly adapt motion rhythms across varying music tempos. Extensive experiments across diverse dance genres show that our approach surpasses existing methods in both qualitative and quantitative evaluations, marking a step toward scalable, real-world 3D dance generation. Code, models, and data will be released.
DynamicVLA: A Vision-Language-Action Model for Dynamic Object Manipulation
Jan 29, 2026Manipulating dynamic objects remains an open challenge for Vision-Language-Action (VLA) models, which, despite strong generalization in static manipulation, struggle in dynamic scenarios requiring rapid perception, temporal anticipation, and continuous control. We present DynamicVLA, a framework for dynamic object manipulation that integrates temporal reasoning and closed-loop adaptation through three key designs: 1) a compact 0.4B VLA using a convolutional vision encoder for spatially efficient, structurally faithful encoding, enabling fast multimodal inference; 2) Continuous Inference, enabling overlapping reasoning and execution for lower latency and timely adaptation to object motion; and 3) Latent-aware Action Streaming, which bridges the perception-execution gap by enforcing temporally aligned action execution. To fill the missing foundation of dynamic manipulation data, we introduce the Dynamic Object Manipulation (DOM) benchmark, built from scratch with an auto data collection pipeline that efficiently gathers 200K synthetic episodes across 2.8K scenes and 206 objects, and enables fast collection of 2K real-world episodes without teleoperation. Extensive evaluations demonstrate remarkable improvements in response speed, perception, and generalization, positioning DynamicVLA as a unified framework for general dynamic object manipulation across embodiments.
3D Scene Generation: A Survey
May 08, 2025



3D scene generation seeks to synthesize spatially structured, semantically meaningful, and photorealistic environments for applications such as immersive media, robotics, autonomous driving, and embodied AI. Early methods based on procedural rules offered scalability but limited diversity. Recent advances in deep generative models (e.g., GANs, diffusion models) and 3D representations (e.g., NeRF, 3D Gaussians) have enabled the learning of real-world scene distributions, improving fidelity, diversity, and view consistency. Recent advances like diffusion models bridge 3D scene synthesis and photorealism by reframing generation as image or video synthesis problems. This survey provides a systematic overview of state-of-the-art approaches, organizing them into four paradigms: procedural generation, neural 3D-based generation, image-based generation, and video-based generation. We analyze their technical foundations, trade-offs, and representative results, and review commonly used datasets, evaluation protocols, and downstream applications. We conclude by discussing key challenges in generation capacity, 3D representation, data and annotations, and evaluation, and outline promising directions including higher fidelity, physics-aware and interactive generation, and unified perception-generation models. This review organizes recent advances in 3D scene generation and highlights promising directions at the intersection of generative AI, 3D vision, and embodied intelligence. To track ongoing developments, we maintain an up-to-date project page: https://github.com/hzxie/Awesome-3D-Scene-Generation.
CityDreamer4D: Compositional Generative Model of Unbounded 4D Cities
Jan 15, 2025



3D scene generation has garnered growing attention in recent years and has made significant progress. Generating 4D cities is more challenging than 3D scenes due to the presence of structurally complex, visually diverse objects like buildings and vehicles, and heightened human sensitivity to distortions in urban environments. To tackle these issues, we propose CityDreamer4D, a compositional generative model specifically tailored for generating unbounded 4D cities. Our main insights are 1) 4D city generation should separate dynamic objects (e.g., vehicles) from static scenes (e.g., buildings and roads), and 2) all objects in the 4D scene should be composed of different types of neural fields for buildings, vehicles, and background stuff. Specifically, we propose Traffic Scenario Generator and Unbounded Layout Generator to produce dynamic traffic scenarios and static city layouts using a highly compact BEV representation. Objects in 4D cities are generated by combining stuff-oriented and instance-oriented neural fields for background stuff, buildings, and vehicles. To suit the distinct characteristics of background stuff and instances, the neural fields employ customized generative hash grids and periodic positional embeddings as scene parameterizations. Furthermore, we offer a comprehensive suite of datasets for city generation, including OSM, GoogleEarth, and CityTopia. The OSM dataset provides a variety of real-world city layouts, while the Google Earth and CityTopia datasets deliver large-scale, high-quality city imagery complete with 3D instance annotations. Leveraging its compositional design, CityDreamer4D supports a range of downstream applications, such as instance editing, city stylization, and urban simulation, while delivering state-of-the-art performance in generating realistic 4D cities.
DynamicCity: Large-Scale LiDAR Generation from Dynamic Scenes
Oct 23, 2024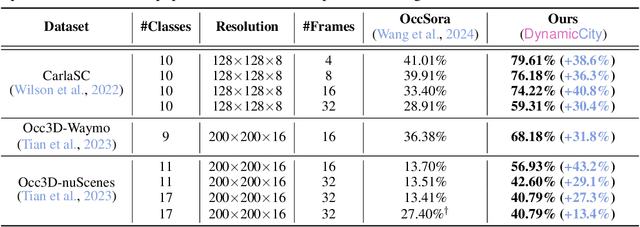
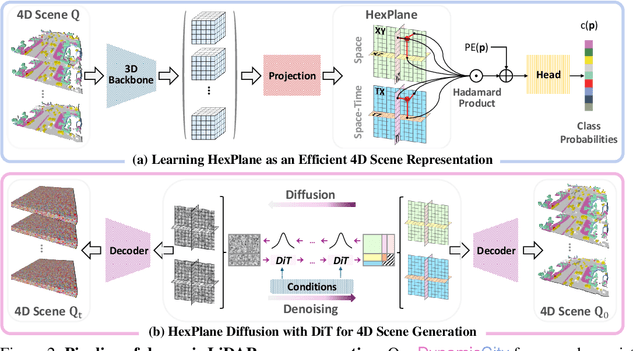

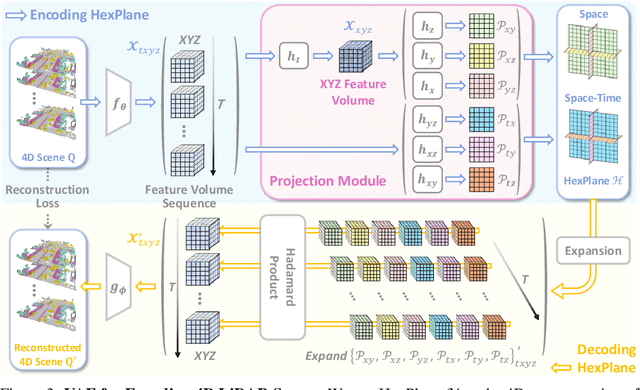
LiDAR scene generation has been developing rapidly recently. However, existing methods primarily focus on generating static and single-frame scenes, overlooking the inherently dynamic nature of real-world driving environments. In this work, we introduce DynamicCity, a novel 4D LiDAR generation framework capable of generating large-scale, high-quality LiDAR scenes that capture the temporal evolution of dynamic environments. DynamicCity mainly consists of two key models. 1) A VAE model for learning HexPlane as the compact 4D representation. Instead of using naive averaging operations, DynamicCity employs a novel Projection Module to effectively compress 4D LiDAR features into six 2D feature maps for HexPlane construction, which significantly enhances HexPlane fitting quality (up to 12.56 mIoU gain). Furthermore, we utilize an Expansion & Squeeze Strategy to reconstruct 3D feature volumes in parallel, which improves both network training efficiency and reconstruction accuracy than naively querying each 3D point (up to 7.05 mIoU gain, 2.06x training speedup, and 70.84% memory reduction). 2) A DiT-based diffusion model for HexPlane generation. To make HexPlane feasible for DiT generation, a Padded Rollout Operation is proposed to reorganize all six feature planes of the HexPlane as a squared 2D feature map. In particular, various conditions could be introduced in the diffusion or sampling process, supporting versatile 4D generation applications, such as trajectory- and command-driven generation, inpainting, and layout-conditioned generation. Extensive experiments on the CarlaSC and Waymo datasets demonstrate that DynamicCity significantly outperforms existing state-of-the-art 4D LiDAR generation methods across multiple metrics. The code will be released to facilitate future research.
CrowdMoGen: Zero-Shot Text-Driven Collective Motion Generation
Jul 08, 2024



Crowd Motion Generation is essential in entertainment industries such as animation and games as well as in strategic fields like urban simulation and planning. This new task requires an intricate integration of control and generation to realistically synthesize crowd dynamics under specific spatial and semantic constraints, whose challenges are yet to be fully explored. On the one hand, existing human motion generation models typically focus on individual behaviors, neglecting the complexities of collective behaviors. On the other hand, recent methods for multi-person motion generation depend heavily on pre-defined scenarios and are limited to a fixed, small number of inter-person interactions, thus hampering their practicality. To overcome these challenges, we introduce CrowdMoGen, a zero-shot text-driven framework that harnesses the power of Large Language Model (LLM) to incorporate the collective intelligence into the motion generation framework as guidance, thereby enabling generalizable planning and generation of crowd motions without paired training data. Our framework consists of two key components: 1) Crowd Scene Planner that learns to coordinate motions and dynamics according to specific scene contexts or introduced perturbations, and 2) Collective Motion Generator that efficiently synthesizes the required collective motions based on the holistic plans. Extensive quantitative and qualitative experiments have validated the effectiveness of our framework, which not only fills a critical gap by providing scalable and generalizable solutions for Crowd Motion Generation task but also achieves high levels of realism and flexibility.