 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrequency-domain Learning with Kernel Prior for Blind Image Deblurring
Apr 20, 2025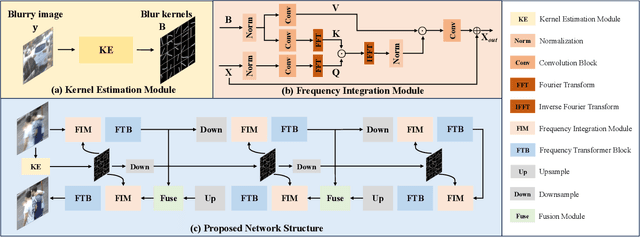
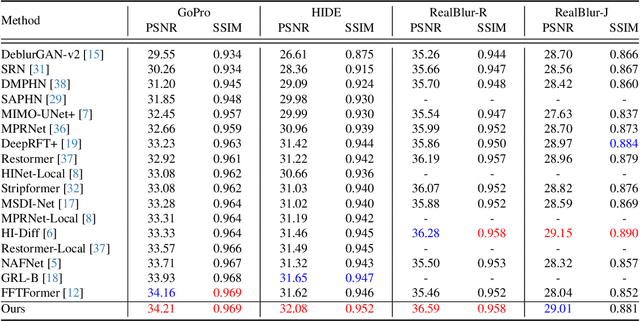

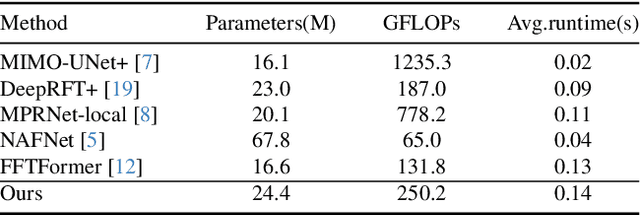
While achieving excellent results on various datasets, many deep learning methods for image deblurring suffer from limited generalization capabilities with out-of-domain data. This limitation is likely caused by their dependence on certain domain-specific datasets. To address this challenge, we argue that it is necessary to introduce the kernel prior into deep learning methods, as the kernel prior remains independent of the image context. For effective fusion of kernel prior information, we adopt a rational implementation method inspired by traditional deblurring algorithms that perform deconvolution in the frequency domain. We propose a module called Frequency Integration Module (FIM) for fusing the kernel prior and combine it with a frequency-based deblurring Transfomer network. Experimental results demonstrate that our method outperforms state-of-the-art methods on multiple blind image deblurring tasks, showcasing robust generalization abilities. Source code will be available soon.
Q-Ground: Image Quality Grounding with Large Multi-modality Models
Jul 24, 2024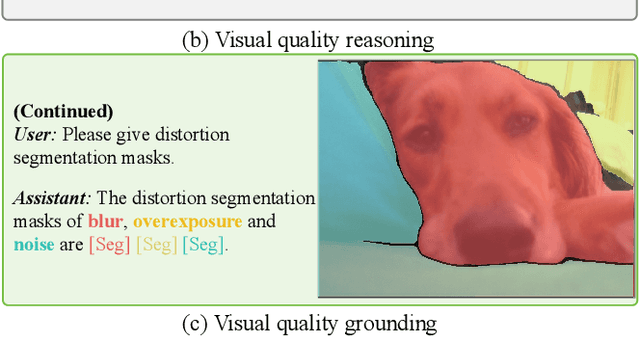

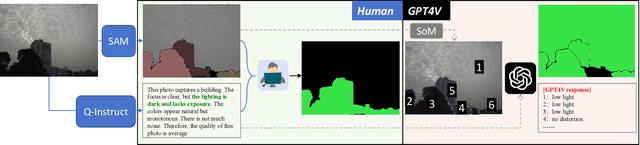

Recent advances of large multi-modality models (LMM) have greatly improved the ability of image quality assessment (IQA) method to evaluate and explain the quality of visual content. However, these advancements are mostly focused on overall quality assessment, and the detailed examination of local quality, which is crucial for comprehensive visual understanding, is still largely unexplored. In this work, we introduce Q-Ground, the first framework aimed at tackling fine-scale visual quality grounding by combining large multi-modality models with detailed visual quality analysis. Central to our contribution is the introduction of the QGround-100K dataset, a novel resource containing 100k triplets of (image, quality text, distortion segmentation) to facilitate deep investigations into visual quality. The dataset comprises two parts: one with human-labeled annotations for accurate quality assessment, and another labeled automatically by LMMs such as GPT4V, which helps improve the robustness of model training while also reducing the costs of data collection. With the QGround-100K dataset, we propose a LMM-based method equipped with multi-scale feature learning to learn models capable of performing both image quality answering and distortion segmentation based on text prompts. This dual-capability approach not only refines the model's understanding of region-aware image quality but also enables it to interactively respond to complex, text-based queries about image quality and specific distortions. Q-Ground takes a step towards sophisticated visual quality analysis in a finer scale, establishing a new benchmark for future research in the area. Codes and dataset are available at https://github.com/Q-Future/Q-Ground.
Towards Open-ended Visual Quality Comparison
Mar 04, 2024Comparative settings (e.g. pairwise choice, listwise ranking) have been adopted by a wide range of subjective studies for image quality assessment (IQA), as it inherently standardizes the evaluation criteria across different observers and offer more clear-cut responses. In this work, we extend the edge of emerging large multi-modality models (LMMs) to further advance visual quality comparison into open-ended settings, that 1) can respond to open-range questions on quality comparison; 2) can provide detailed reasonings beyond direct answers. To this end, we propose the Co-Instruct. To train this first-of-its-kind open-source open-ended visual quality comparer, we collect the Co-Instruct-562K dataset, from two sources: (a) LLM-merged single image quality description, (b) GPT-4V "teacher" responses on unlabeled data. Furthermore, to better evaluate this setting, we propose the MICBench, the first benchmark on multi-image comparison for LMMs. We demonstrate that Co-Instruct not only achieves in average 30% higher accuracy than state-of-the-art open-source LMMs, but also outperforms GPT-4V (its teacher), on both existing related benchmarks and the proposed MICBench. Our model is published at https://huggingface.co/q-future/co-instruct.
Q-Align: Teaching LMMs for Visual Scoring via Discrete Text-Defined Levels
Dec 28, 2023



The explosion of visual content available online underscores the requirement for an accurate machine assessor to robustly evaluate scores across diverse types of visual contents. While recent studies have demonstrated the exceptional potentials of large multi-modality models (LMMs) on a wide range of related fields, in this work, we explore how to teach them for visual rating aligned with human opinions. Observing that human raters only learn and judge discrete text-defined levels in subjective studies, we propose to emulate this subjective process and teach LMMs with text-defined rating levels instead of scores. The proposed Q-Align achieves state-of-the-art performance on image quality assessment (IQA), image aesthetic assessment (IAA), as well as video quality assessment (VQA) tasks under the original LMM structure. With the syllabus, we further unify the three tasks into one model, termed the OneAlign. In our experiments, we demonstrate the advantage of the discrete-level-based syllabus over direct-score-based variants for LMMs. Our code and the pre-trained weights are released at https://github.com/Q-Future/Q-Align.
Iterative Token Evaluation and Refinement for Real-World Super-Resolution
Dec 09, 2023
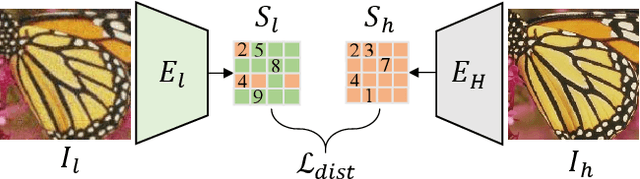

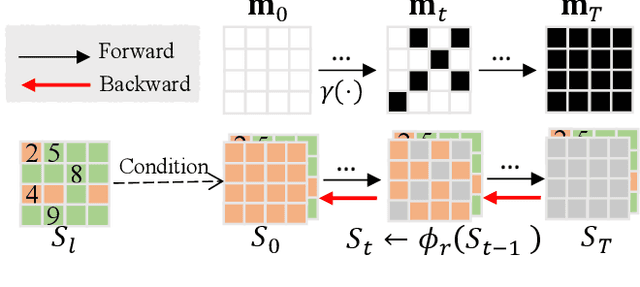
Real-world image super-resolution (RWSR) is a long-standing problem as low-quality (LQ) images often have complex and unidentified degradations. Existing methods such as Generative Adversarial Networks (GANs) or continuous diffusion models present their own issues including GANs being difficult to train while continuous diffusion models requiring numerous inference steps. In this paper, we propose an Iterative Token Evaluation and Refinement (ITER) framework for RWSR, which utilizes a discrete diffusion model operating in the discrete token representation space, i.e., indexes of features extracted from a VQGAN codebook pre-trained with high-quality (HQ) images. We show that ITER is easier to train than GANs and more efficient than continuous diffusion models. Specifically, we divide RWSR into two sub-tasks, i.e., distortion removal and texture generation. Distortion removal involves simple HQ token prediction with LQ images, while texture generation uses a discrete diffusion model to iteratively refine the distortion removal output with a token refinement network. In particular, we propose to include a token evaluation network in the discrete diffusion process. It learns to evaluate which tokens are good restorations and helps to improve the iterative refinement results. Moreover, the evaluation network can first check status of the distortion removal output and then adaptively select total refinement steps needed, thereby maintaining a good balance between distortion removal and texture generation. Extensive experimental results show that ITER is easy to train and performs well within just 8 iterative steps. Our codes will be available publicly.
Enhancing Diffusion Models with Text-Encoder Reinforcement Learning
Nov 27, 2023
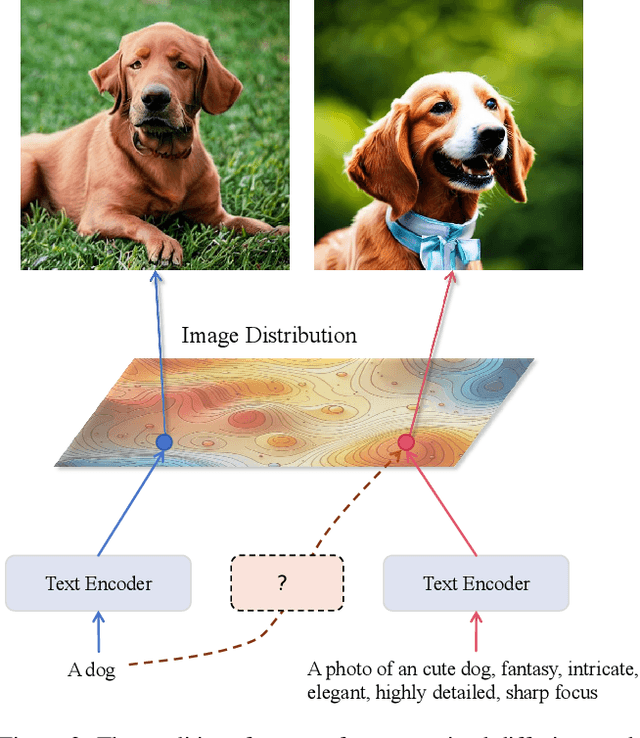
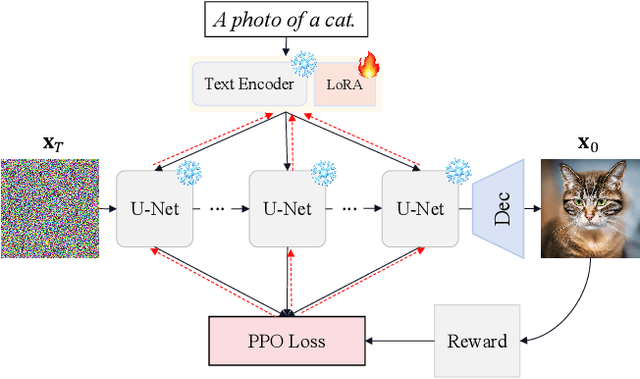

Text-to-image diffusion models are typically trained to optimize the log-likelihood objective, which presents challenges in meeting specific requirements for downstream tasks, such as image aesthetics and image-text alignment. Recent research addresses this issue by refining the diffusion U-Net using human rewards through reinforcement learning or direct backpropagation. However, many of them overlook the importance of the text encoder, which is typically pretrained and fixed during training. In this paper, we demonstrate that by finetuning the text encoder through reinforcement learning, we can enhance the text-image alignment of the results, thereby improving the visual quality. Our primary motivation comes from the observation that the current text encoder is suboptimal, often requiring careful prompt adjustment. While fine-tuning the U-Net can partially improve performance, it remains suffering from the suboptimal text encoder. Therefore, we propose to use reinforcement learning with low-rank adaptation to finetune the text encoder based on task-specific rewards, referred as \textbf{TexForce}. We first show that finetuning the text encoder can improve the performance of diffusion models. Then, we illustrate that TexForce can be simply combined with existing U-Net finetuned models to get much better results without additional training. Finally, we showcase the adaptability of our method in diverse applications, including the generation of high-quality face and hand images.
Q-Instruct: Improving Low-level Visual Abilities for Multi-modality Foundation Models
Nov 12, 2023



Multi-modality foundation models, as represented by GPT-4V, have brought a new paradigm for low-level visual perception and understanding tasks, that can respond to a broad range of natural human instructions in a model. While existing foundation models have shown exciting potentials on low-level visual tasks, their related abilities are still preliminary and need to be improved. In order to enhance these models, we conduct a large-scale subjective experiment collecting a vast number of real human feedbacks on low-level vision. Each feedback follows a pathway that starts with a detailed description on the low-level visual appearance (*e.g. clarity, color, brightness* of an image, and ends with an overall conclusion, with an average length of 45 words. The constructed **Q-Pathway** dataset includes 58K detailed human feedbacks on 18,973 images with diverse low-level appearance. Moreover, to enable foundation models to robustly respond to diverse types of questions, we design a GPT-participated conversion to process these feedbacks into diverse-format 200K instruction-response pairs. Experimental results indicate that the **Q-Instruct** consistently elevates low-level perception and understanding abilities across several foundational models. We anticipate that our datasets can pave the way for a future that general intelligence can perceive, understand low-level visual appearance and evaluate visual quality like a human. Our dataset, model zoo, and demo is published at: https://q-future.github.io/Q-Instruct.
Q-Bench: A Benchmark for General-Purpose Foundation Models on Low-level Vision
Sep 28, 2023The rapid evolution of Multi-modality Large Language Models (MLLMs) has catalyzed a shift in computer vision from specialized models to general-purpose foundation models. Nevertheless, there is still an inadequacy in assessing the abilities of MLLMs on low-level visual perception and understanding. To address this gap, we present Q-Bench, a holistic benchmark crafted to systematically evaluate potential abilities of MLLMs on three realms: low-level visual perception, low-level visual description, and overall visual quality assessment. a) To evaluate the low-level perception ability, we construct the LLVisionQA dataset, consisting of 2,990 diverse-sourced images, each equipped with a human-asked question focusing on its low-level attributes. We then measure the correctness of MLLMs on answering these questions. b) To examine the description ability of MLLMs on low-level information, we propose the LLDescribe dataset consisting of long expert-labelled golden low-level text descriptions on 499 images, and a GPT-involved comparison pipeline between outputs of MLLMs and the golden descriptions. c) Besides these two tasks, we further measure their visual quality assessment ability to align with human opinion scores. Specifically, we design a softmax-based strategy that enables MLLMs to predict quantifiable quality scores, and evaluate them on various existing image quality assessment (IQA) datasets. Our evaluation across the three abilities confirms that MLLMs possess preliminary low-level visual skills. However, these skills are still unstable and relatively imprecise, indicating the need for specific enhancements on MLLMs towards these abilities. We hope that our benchmark can encourage the research community to delve deeper to discover and enhance these untapped potentials of MLLMs. Project Page: https://vqassessment.github.io/Q-Bench.
TOPIQ: A Top-down Approach from Semantics to Distortions for Image Quality Assessment
Aug 06, 2023



Image Quality Assessment (IQA) is a fundamental task in computer vision that has witnessed remarkable progress with deep neural networks. Inspired by the characteristics of the human visual system, existing methods typically use a combination of global and local representations (\ie, multi-scale features) to achieve superior performance. However, most of them adopt simple linear fusion of multi-scale features, and neglect their possibly complex relationship and interaction. In contrast, humans typically first form a global impression to locate important regions and then focus on local details in those regions. We therefore propose a top-down approach that uses high-level semantics to guide the IQA network to focus on semantically important local distortion regions, named as \emph{TOPIQ}. Our approach to IQA involves the design of a heuristic coarse-to-fine network (CFANet) that leverages multi-scale features and progressively propagates multi-level semantic information to low-level representations in a top-down manner. A key component of our approach is the proposed cross-scale attention mechanism, which calculates attention maps for lower level features guided by higher level features. This mechanism emphasizes active semantic regions for low-level distortions, thereby improving performance. CFANet can be used for both Full-Reference (FR) and No-Reference (NR) IQA. We use ResNet50 as its backbone and demonstrate that CFANet achieves better or competitive performance on most public FR and NR benchmarks compared with state-of-the-art methods based on vision transformers, while being much more efficient (with only ${\sim}13\%$ FLOPS of the current best FR method). Codes are released at \url{https://github.com/chaofengc/IQA-PyTorch}.
MIPI 2023 Challenge on Nighttime Flare Removal: Methods and Results
May 23, 2023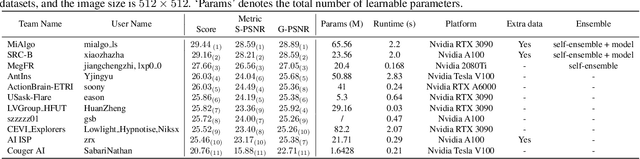

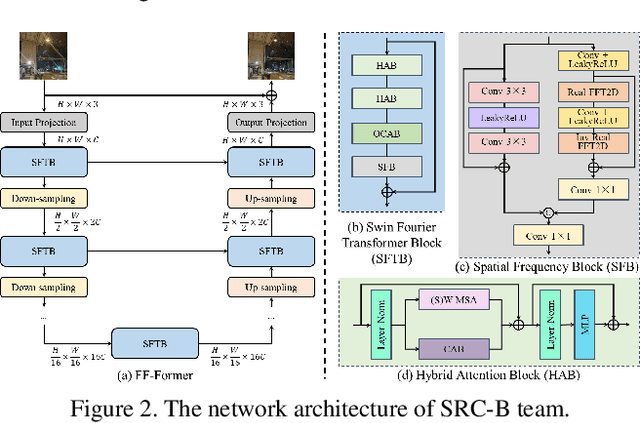
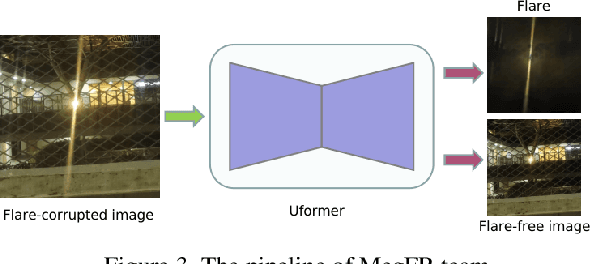
Developing and integrating advanced image sensors with novel algorithms in camera systems are prevalent with the increasing demand for computational photography and imaging on mobile platforms. However, the lack of high-quality data for research and the rare opportunity for in-depth exchange of views from industry and academia constrain the development of mobile intelligent photography and imaging (MIPI). With the success of the 1st MIPI Workshop@ECCV 2022, we introduce the second MIPI challenge including four tracks focusing on novel image sensors and imaging algorithms. In this paper, we summarize and review the Nighttime Flare Removal track on MIPI 2023. In total, 120 participants were successfully registered, and 11 teams submitted results in the final testing phase. The developed solutions in this challenge achieved state-of-the-art performance on Nighttime Flare Removal. A detailed description of all models developed in this challenge is provided in this paper. More details of this challenge and the link to the dataset can be found at https://mipi-challenge.org/MIPI2023/ .