 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoupled Similarity for Task-Aware Token Pruning in Large Vision-Language Models
Apr 13, 2026Token pruning has emerged as an effective approach to reduce the substantial computational overhead of Large Vision-Language Models (LVLMs) by discarding less informative visual tokens while preserving performance. However, existing methods typically rely on individual attention sources from different LVLM components, resulting in incomplete and suboptimal pruning decisions due to biased attention distributions. To address this problem, we propose DeSAP, a novel Decoupled Similarity-Aware Pruning method for precise, task-aware token pruning within the visual encoder. Specifically, DeSAP introduces a decoupled similarity to capture fine-grained cross-modal relevance between visual features and text tokens, providing explicit task-related guidance for pruning. By integrating decoupled similarity with visual saliency signals derived from visual attention, DeSAP performs token pruning under the guidance of both task-related and visual cues, enabling robust pruning even under aggressive pruning ratios. Extensive experiments across diverse benchmarks and architectures show that DeSAP consistently outperforms SOTA methods in both accuracy and efficiency. On LLaVA-1.5-7B, DeSAP achieves a 10 times FLOPs reduction and a 2.3 times prefill speedup by retaining only 11.1% of visual tokens, while maintaining 98.1% of the original performance.
Observe Less, Understand More: Cost-aware Cross-scale Observation for Remote Sensing Understanding
Apr 13, 2026Remote sensing understanding inherently requires multi-resolution observation, since different targets and application tasks demand different levels of spatial detail. While low-resolution (LR) imagery enables efficient global observation, high-resolution (HR) imagery provides critical local details at much higher acquisition cost and limited coverage. This motivates a cross-scale sensing strategy that selectively acquires HR imagery from LR-based global perception to improve task performance under constrained cost. Existing methods for HR sampling methods typically make selection decisions from isolated LR patches, which ignore fine-grained intra-patch importance and cross-patch contextual interactions, leading to fragmented feature representation and suboptimal scene reasoning under sparse HR observations. To address this issue, we formulate cross-scale remote sensing understanding as a unified cost-aware problem that couples fine-grained HR sampling with cross-patch representation prediction, enabling more effective task reasoning with fewer HR observations. Furthermore, we present GL-10M, a large-scale benchmark of 10 million spatially aligned multi-resolution images, enabling systematic evaluation of budget-constrained cross-scale reasoning in remote sensing. Extensive experiments on recognition and retrieval tasks show that our method consistently achieves a superior performance-cost trade-off.
SGMA: Semantic-Guided Modality-Aware Segmentation for Remote Sensing with Incomplete Multimodal Data
Mar 03, 2026Multimodal semantic segmentation integrates complementary information from diverse sensors for remote sensing Earth observation. However, practical systems often encounter missing modalities due to sensor failures or incomplete coverage, termed Incomplete Multimodal Semantic Segmentation (IMSS). IMSS faces three key challenges: (1) multimodal imbalance, where dominant modalities suppress fragile ones; (2) intra-class variation in scale, shape, and orientation across modalities; and (3) cross-modal heterogeneity with conflicting cues producing inconsistent semantic responses. Existing methods rely on contrastive learning or joint optimization, which risk over-alignment, discarding modality-specific cues or imbalanced training, favoring robust modalities, while largely overlooking intra-class variation and cross-modal heterogeneity. To address these limitations, we propose the Semantic-Guided Modality-Aware (SGMA) framework, which ensures balanced multimodal learning while reducing intra-class variation and reconciling cross-modal inconsistencies through semantic guidance. SGMA introduces two complementary plug-and-play modules: (1) Semantic-Guided Fusion (SGF) module extracts multi-scale, class-wise semantic prototypes that capture consistent categorical representations across modalities, estimates per-modality robustness based on prototype-feature alignment, and performs adaptive fusion weighted by robustness scores to mitigate intra-class variation and cross-modal heterogeneity; (2) Modality-Aware Sampling (MAS) module leverages robustness estimations from SGF to dynamically reweight training samples, prioritizing challenging samples from fragile modalities to address modality imbalance. Extensive experiments across multiple datasets and backbones demonstrate that SGMA consistently outperforms state-of-the-art methods, with particularly significant improvements in fragile modalities.
DeTracker: Motion-decoupled Vehicle Detection and Tracking in Unstabilized Satellite Videos
Jan 14, 2026Satellite videos provide continuous observations of surface dynamics but pose significant challenges for multi-object tracking (MOT), especially under unstabilized conditions where platform jitter and the weak appearance of tiny objects jointly degrade tracking performance. To address this problem, we propose DeTracker, a joint detection-and-tracking framework tailored for unstabilized satellite videos. DeTracker introduces a Global--Local Motion Decoupling (GLMD) module that explicitly separates satellite platform motion from true object motion through global alignment and local refinement, leading to improved trajectory stability and motion estimation accuracy. In addition, a Temporal Dependency Feature Pyramid (TDFP) module is developed to perform cross-frame temporal feature fusion, enhancing the continuity and discriminability of tiny-object representations. We further construct a new benchmark dataset, SDM-Car-SU, which simulates multi-directional and multi-speed platform motions to enable systematic evaluation of tracking robustness under varying motion perturbations. Extensive experiments on both simulated and real unstabilized satellite videos demonstrate that DeTracker significantly outperforms existing methods, achieving 61.1% MOTA on SDM-Car-SU and 47.3% MOTA on real satellite video data.
SDM-Car: A Dataset for Small and Dim Moving Vehicles Detection in Satellite Videos
Dec 24, 2024



Vehicle detection and tracking in satellite video is essential in remote sensing (RS) applications. However, upon the statistical analysis of existing datasets, we find that the dim vehicles with low radiation intensity and limited contrast against the background are rarely annotated, which leads to the poor effect of existing approaches in detecting moving vehicles under low radiation conditions. In this paper, we address the challenge by building a \textbf{S}mall and \textbf{D}im \textbf{M}oving Cars (SDM-Car) dataset with a multitude of annotations for dim vehicles in satellite videos, which is collected by the Luojia 3-01 satellite and comprises 99 high-quality videos. Furthermore, we propose a method based on image enhancement and attention mechanisms to improve the detection accuracy of dim vehicles, serving as a benchmark for evaluating the dataset. Finally, we assess the performance of several representative methods on SDM-Car and present insightful findings. The dataset is openly available at https://github.com/TanedaM/SDM-Car.
Hyperspectral Image Spectral-Spatial Feature Extraction via Tensor Principal Component Analysis
Dec 08, 2024
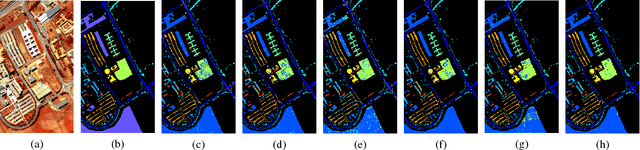
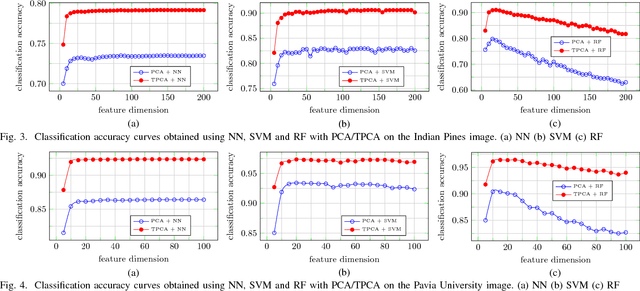
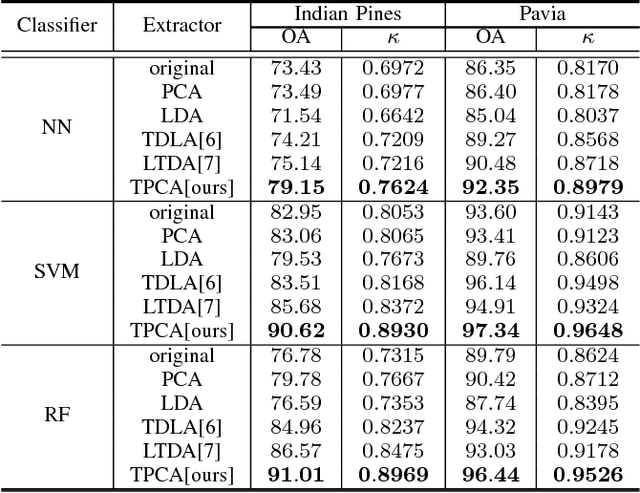
This paper addresses the challenge of spectral-spatial feature extraction for hyperspectral image classification by introducing a novel tensor-based framework. The proposed approach incorporates circular convolution into a tensor structure to effectively capture and integrate both spectral and spatial information. Building upon this framework, the traditional Principal Component Analysis (PCA) technique is extended to its tensor-based counterpart, referred to as Tensor Principal Component Analysis (TPCA). The proposed TPCA method leverages the inherent multi-dimensional structure of hyperspectral data, thereby enabling more effective feature representation. Experimental results on benchmark hyperspectral datasets demonstrate that classification models using TPCA features consistently outperform those using traditional PCA and other state-of-the-art techniques. These findings highlight the potential of the tensor-based framework in advancing hyperspectral image analysis.
Towards Robust Online Domain Adaptive Semantic Segmentation under Adverse Weather Conditions
Sep 02, 2024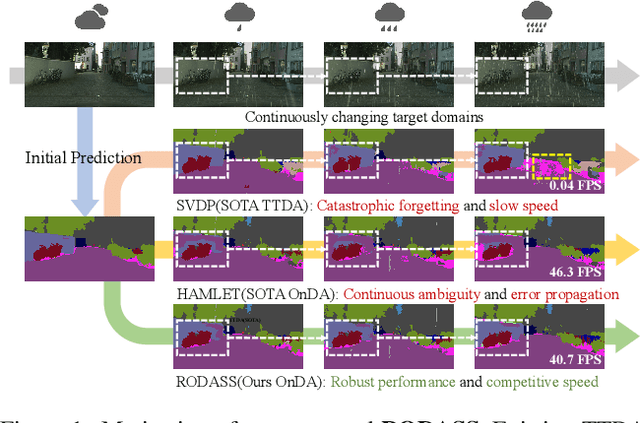
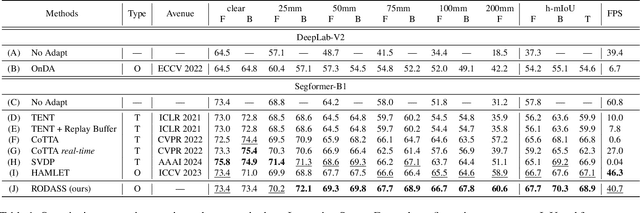
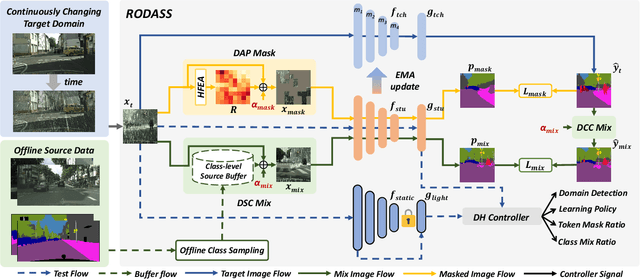

Online Domain Adaptation (OnDA) is designed to handle unforeseeable domain changes at minimal cost that occur during the deployment of the model, lacking clear boundaries between the domain, such as sudden weather events. However, existing OnDA methods that rely solely on the model itself to adapt to the current domain often misidentify ambiguous classes amidst continuous domain shifts and pass on this erroneous knowledge to the next domain. To tackle this, we propose \textbf{RODASS}, a \textbf{R}obust \textbf{O}nline \textbf{D}omain \textbf{A}daptive \textbf{S}emantic \textbf{S}egmentation framework, which dynamically detects domain shifts and adjusts hyper-parameters to minimize training costs and error propagation. Specifically, we introduce the \textbf{D}ynamic \textbf{A}mbiguous \textbf{P}atch \textbf{Mask} (\textbf{DAP Mask}) strategy, which dynamically selects highly disturbed regions and masks these regions, mitigating error accumulation in ambiguous classes and enhancing the model's robustness against external noise in dynamic natural environments. Additionally, we present the \textbf{D}ynamic \textbf{S}ource \textbf{C}lass \textbf{Mix} (\textbf{DSC Mix}), a domain-aware mix method that augments target domain scenes with class-level source buffers, reducing the high uncertainty and noisy labels, thereby accelerating adaptation and offering a more efficient solution for online domain adaptation. Our approach outperforms state-of-the-art methods on widely used OnDA benchmarks while maintaining approximately 40 frames per second (FPS).
Q-Ground: Image Quality Grounding with Large Multi-modality Models
Jul 24, 2024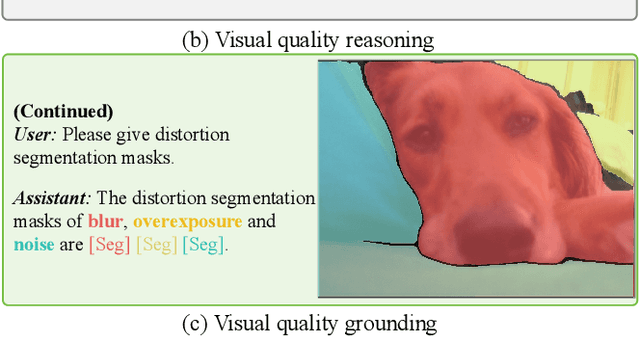

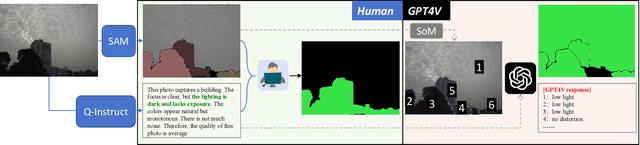

Recent advances of large multi-modality models (LMM) have greatly improved the ability of image quality assessment (IQA) method to evaluate and explain the quality of visual content. However, these advancements are mostly focused on overall quality assessment, and the detailed examination of local quality, which is crucial for comprehensive visual understanding, is still largely unexplored. In this work, we introduce Q-Ground, the first framework aimed at tackling fine-scale visual quality grounding by combining large multi-modality models with detailed visual quality analysis. Central to our contribution is the introduction of the QGround-100K dataset, a novel resource containing 100k triplets of (image, quality text, distortion segmentation) to facilitate deep investigations into visual quality. The dataset comprises two parts: one with human-labeled annotations for accurate quality assessment, and another labeled automatically by LMMs such as GPT4V, which helps improve the robustness of model training while also reducing the costs of data collection. With the QGround-100K dataset, we propose a LMM-based method equipped with multi-scale feature learning to learn models capable of performing both image quality answering and distortion segmentation based on text prompts. This dual-capability approach not only refines the model's understanding of region-aware image quality but also enables it to interactively respond to complex, text-based queries about image quality and specific distortions. Q-Ground takes a step towards sophisticated visual quality analysis in a finer scale, establishing a new benchmark for future research in the area. Codes and dataset are available at https://github.com/Q-Future/Q-Ground.
360VFI: A Dataset and Benchmark for Omnidirectional Video Frame Interpolation
Jul 19, 2024



With the development of VR-related techniques, viewers can enjoy a realistic and immersive experience through a head-mounted display, while omnidirectional video with a low frame rate can lead to user dizziness. However, the prevailing plane frame interpolation methodologies are unsuitable for Omnidirectional Video Interpolation, chiefly due to the lack of models tailored to such videos with strong distortion, compounded by the scarcity of valuable datasets for Omnidirectional Video Frame Interpolation. In this paper, we introduce the benchmark dataset, 360VFI, for Omnidirectional Video Frame Interpolation. We present a practical implementation that introduces a distortion prior from omnidirectional video into the network to modulate distortions. We especially propose a pyramid distortion-sensitive feature extractor that uses the unique characteristics of equirectangular projection (ERP) format as prior information. Moreover, we devise a decoder that uses an affine transformation to facilitate the synthesis of intermediate frames further. 360VFI is the first dataset and benchmark that explores the challenge of Omnidirectional Video Frame Interpolation. Through our benchmark analysis, we presented four different distortion conditions scenes in the proposed 360VFI dataset to evaluate the challenge triggered by distortion during interpolation. Besides, experimental results demonstrate that Omnidirectional Video Interpolation can be effectively improved by modeling for omnidirectional distortion.
Towards Open-ended Visual Quality Comparison
Mar 04, 2024Comparative settings (e.g. pairwise choice, listwise ranking) have been adopted by a wide range of subjective studies for image quality assessment (IQA), as it inherently standardizes the evaluation criteria across different observers and offer more clear-cut responses. In this work, we extend the edge of emerging large multi-modality models (LMMs) to further advance visual quality comparison into open-ended settings, that 1) can respond to open-range questions on quality comparison; 2) can provide detailed reasonings beyond direct answers. To this end, we propose the Co-Instruct. To train this first-of-its-kind open-source open-ended visual quality comparer, we collect the Co-Instruct-562K dataset, from two sources: (a) LLM-merged single image quality description, (b) GPT-4V "teacher" responses on unlabeled data. Furthermore, to better evaluate this setting, we propose the MICBench, the first benchmark on multi-image comparison for LMMs. We demonstrate that Co-Instruct not only achieves in average 30% higher accuracy than state-of-the-art open-source LMMs, but also outperforms GPT-4V (its teacher), on both existing related benchmarks and the proposed MICBench. Our model is published at https://huggingface.co/q-future/co-instruct.