 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurgical SAM 2: Real-time Segment Anything in Surgical Video by Efficient Frame Pruning
Aug 15, 2024Surgical video segmentation is a critical task in computer-assisted surgery and is vital for enhancing surgical quality and patient outcomes. Recently, the Segment Anything Model 2 (SAM2) framework has shown superior advancements in image and video segmentation. However, SAM2 struggles with efficiency due to the high computational demands of processing high-resolution images and complex and long-range temporal dynamics in surgical videos. To address these challenges, we introduce Surgical SAM 2 (SurgSAM-2), an advanced model to utilize SAM2 with an Efficient Frame Pruning (EFP) mechanism, to facilitate real-time surgical video segmentation. The EFP mechanism dynamically manages the memory bank by selectively retaining only the most informative frames, reducing memory usage and computational cost while maintaining high segmentation accuracy. Our extensive experiments demonstrate that SurgSAM-2 significantly improves both efficiency and segmentation accuracy compared to the vanilla SAM2. Remarkably, SurgSAM-2 achieves a 3$\times$ FPS compared with SAM2, while also delivering state-of-the-art performance after fine-tuning with lower-resolution data. These advancements establish SurgSAM-2 as a leading model for surgical video analysis, making real-time surgical video segmentation in resource-constrained environments a feasible reality.
Towards Open-ended Visual Quality Comparison
Mar 04, 2024Comparative settings (e.g. pairwise choice, listwise ranking) have been adopted by a wide range of subjective studies for image quality assessment (IQA), as it inherently standardizes the evaluation criteria across different observers and offer more clear-cut responses. In this work, we extend the edge of emerging large multi-modality models (LMMs) to further advance visual quality comparison into open-ended settings, that 1) can respond to open-range questions on quality comparison; 2) can provide detailed reasonings beyond direct answers. To this end, we propose the Co-Instruct. To train this first-of-its-kind open-source open-ended visual quality comparer, we collect the Co-Instruct-562K dataset, from two sources: (a) LLM-merged single image quality description, (b) GPT-4V "teacher" responses on unlabeled data. Furthermore, to better evaluate this setting, we propose the MICBench, the first benchmark on multi-image comparison for LMMs. We demonstrate that Co-Instruct not only achieves in average 30% higher accuracy than state-of-the-art open-source LMMs, but also outperforms GPT-4V (its teacher), on both existing related benchmarks and the proposed MICBench. Our model is published at https://huggingface.co/q-future/co-instruct.
A Benchmark for Multi-modal Foundation Models on Low-level Vision: from Single Images to Pairs
Feb 11, 2024The rapid development of Multi-modality Large Language Models (MLLMs) has navigated a paradigm shift in computer vision, moving towards versatile foundational models. However, evaluating MLLMs in low-level visual perception and understanding remains a yet-to-explore domain. To this end, we design benchmark settings to emulate human language responses related to low-level vision: the low-level visual perception (A1) via visual question answering related to low-level attributes (e.g. clarity, lighting); and the low-level visual description (A2), on evaluating MLLMs for low-level text descriptions. Furthermore, given that pairwise comparison can better avoid ambiguity of responses and has been adopted by many human experiments, we further extend the low-level perception-related question-answering and description evaluations of MLLMs from single images to image pairs. Specifically, for perception (A1), we carry out the LLVisionQA+ dataset, comprising 2,990 single images and 1,999 image pairs each accompanied by an open-ended question about its low-level features; for description (A2), we propose the LLDescribe+ dataset, evaluating MLLMs for low-level descriptions on 499 single images and 450 pairs. Additionally, we evaluate MLLMs on assessment (A3) ability, i.e. predicting score, by employing a softmax-based approach to enable all MLLMs to generate quantifiable quality ratings, tested against human opinions in 7 image quality assessment (IQA) datasets. With 24 MLLMs under evaluation, we demonstrate that several MLLMs have decent low-level visual competencies on single images, but only GPT-4V exhibits higher accuracy on pairwise comparisons than single image evaluations (like humans). We hope that our benchmark will motivate further research into uncovering and enhancing these nascent capabilities of MLLMs. Datasets will be available at https://github.com/Q-Future/Q-Bench.
Q-Align: Teaching LMMs for Visual Scoring via Discrete Text-Defined Levels
Dec 28, 2023



The explosion of visual content available online underscores the requirement for an accurate machine assessor to robustly evaluate scores across diverse types of visual contents. While recent studies have demonstrated the exceptional potentials of large multi-modality models (LMMs) on a wide range of related fields, in this work, we explore how to teach them for visual rating aligned with human opinions. Observing that human raters only learn and judge discrete text-defined levels in subjective studies, we propose to emulate this subjective process and teach LMMs with text-defined rating levels instead of scores. The proposed Q-Align achieves state-of-the-art performance on image quality assessment (IQA), image aesthetic assessment (IAA), as well as video quality assessment (VQA) tasks under the original LMM structure. With the syllabus, we further unify the three tasks into one model, termed the OneAlign. In our experiments, we demonstrate the advantage of the discrete-level-based syllabus over direct-score-based variants for LMMs. Our code and the pre-trained weights are released at https://github.com/Q-Future/Q-Align.
Q-Boost: On Visual Quality Assessment Ability of Low-level Multi-Modality Foundation Models
Dec 23, 2023Recent advancements in Multi-modality Large Language Models (MLLMs) have demonstrated remarkable capabilities in complex high-level vision tasks. However, the exploration of MLLM potential in visual quality assessment, a vital aspect of low-level vision, remains limited. To address this gap, we introduce Q-Boost, a novel strategy designed to enhance low-level MLLMs in image quality assessment (IQA) and video quality assessment (VQA) tasks, which is structured around two pivotal components: 1) Triadic-Tone Integration: Ordinary prompt design simply oscillates between the binary extremes of $positive$ and $negative$. Q-Boost innovates by incorporating a `middle ground' approach through $neutral$ prompts, allowing for a more balanced and detailed assessment. 2) Multi-Prompt Ensemble: Multiple quality-centric prompts are used to mitigate bias and acquire more accurate evaluation. The experimental results show that the low-level MLLMs exhibit outstanding zeros-shot performance on the IQA/VQA tasks equipped with the Q-Boost strategy.
Q-Instruct: Improving Low-level Visual Abilities for Multi-modality Foundation Models
Nov 12, 2023



Multi-modality foundation models, as represented by GPT-4V, have brought a new paradigm for low-level visual perception and understanding tasks, that can respond to a broad range of natural human instructions in a model. While existing foundation models have shown exciting potentials on low-level visual tasks, their related abilities are still preliminary and need to be improved. In order to enhance these models, we conduct a large-scale subjective experiment collecting a vast number of real human feedbacks on low-level vision. Each feedback follows a pathway that starts with a detailed description on the low-level visual appearance (*e.g. clarity, color, brightness* of an image, and ends with an overall conclusion, with an average length of 45 words. The constructed **Q-Pathway** dataset includes 58K detailed human feedbacks on 18,973 images with diverse low-level appearance. Moreover, to enable foundation models to robustly respond to diverse types of questions, we design a GPT-participated conversion to process these feedbacks into diverse-format 200K instruction-response pairs. Experimental results indicate that the **Q-Instruct** consistently elevates low-level perception and understanding abilities across several foundational models. We anticipate that our datasets can pave the way for a future that general intelligence can perceive, understand low-level visual appearance and evaluate visual quality like a human. Our dataset, model zoo, and demo is published at: https://q-future.github.io/Q-Instruct.
Q-Bench: A Benchmark for General-Purpose Foundation Models on Low-level Vision
Sep 28, 2023The rapid evolution of Multi-modality Large Language Models (MLLMs) has catalyzed a shift in computer vision from specialized models to general-purpose foundation models. Nevertheless, there is still an inadequacy in assessing the abilities of MLLMs on low-level visual perception and understanding. To address this gap, we present Q-Bench, a holistic benchmark crafted to systematically evaluate potential abilities of MLLMs on three realms: low-level visual perception, low-level visual description, and overall visual quality assessment. a) To evaluate the low-level perception ability, we construct the LLVisionQA dataset, consisting of 2,990 diverse-sourced images, each equipped with a human-asked question focusing on its low-level attributes. We then measure the correctness of MLLMs on answering these questions. b) To examine the description ability of MLLMs on low-level information, we propose the LLDescribe dataset consisting of long expert-labelled golden low-level text descriptions on 499 images, and a GPT-involved comparison pipeline between outputs of MLLMs and the golden descriptions. c) Besides these two tasks, we further measure their visual quality assessment ability to align with human opinion scores. Specifically, we design a softmax-based strategy that enables MLLMs to predict quantifiable quality scores, and evaluate them on various existing image quality assessment (IQA) datasets. Our evaluation across the three abilities confirms that MLLMs possess preliminary low-level visual skills. However, these skills are still unstable and relatively imprecise, indicating the need for specific enhancements on MLLMs towards these abilities. We hope that our benchmark can encourage the research community to delve deeper to discover and enhance these untapped potentials of MLLMs. Project Page: https://vqassessment.github.io/Q-Bench.
Towards Explainable In-the-Wild Video Quality Assessment: a Database and a Language-Prompted Approach
May 22, 2023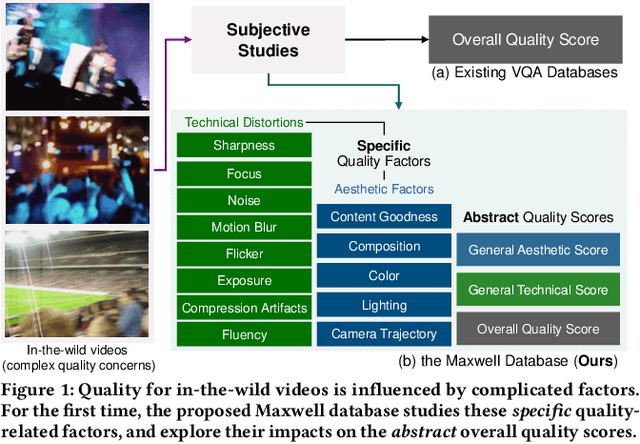
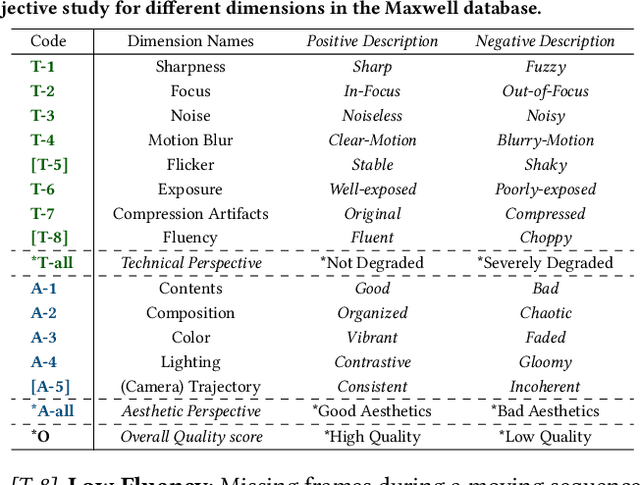
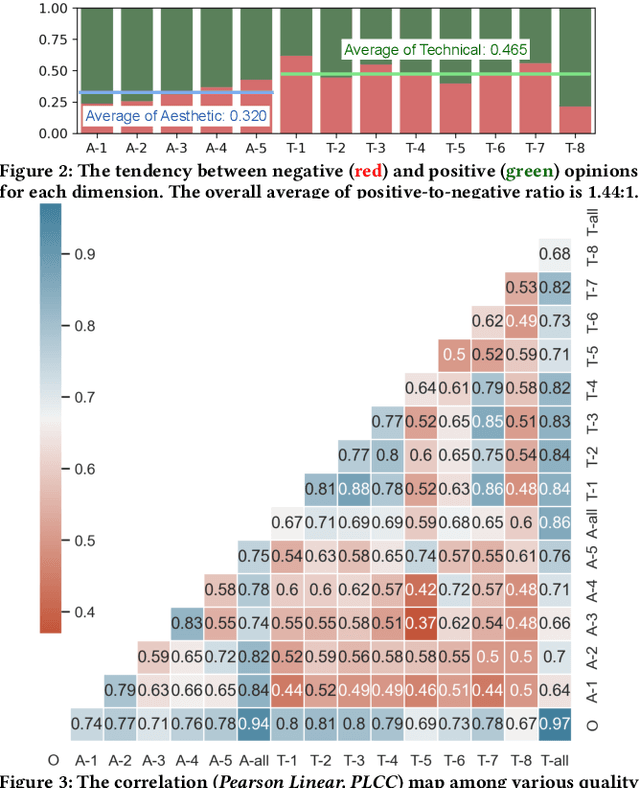
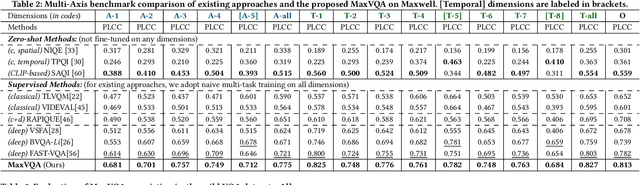
The proliferation of in-the-wild videos has greatly expanded the Video Quality Assessment (VQA) problem. Unlike early definitions that usually focus on limited distortion types, VQA on in-the-wild videos is especially challenging as it could be affected by complicated factors, including various distortions and diverse contents. Though subjective studies have collected overall quality scores for these videos, how the abstract quality scores relate with specific factors is still obscure, hindering VQA methods from more concrete quality evaluations (e.g. sharpness of a video). To solve this problem, we collect over two million opinions on 4,543 in-the-wild videos on 13 dimensions of quality-related factors, including in-capture authentic distortions (e.g. motion blur, noise, flicker), errors introduced by compression and transmission, and higher-level experiences on semantic contents and aesthetic issues (e.g. composition, camera trajectory), to establish the multi-dimensional Maxwell database. Specifically, we ask the subjects to label among a positive, a negative, and a neural choice for each dimension. These explanation-level opinions allow us to measure the relationships between specific quality factors and abstract subjective quality ratings, and to benchmark different categories of VQA algorithms on each dimension, so as to more comprehensively analyze their strengths and weaknesses. Furthermore, we propose the MaxVQA, a language-prompted VQA approach that modifies vision-language foundation model CLIP to better capture important quality issues as observed in our analyses. The MaxVQA can jointly evaluate various specific quality factors and final quality scores with state-of-the-art accuracy on all dimensions, and superb generalization ability on existing datasets. Code and data available at \url{https://github.com/VQAssessment/MaxVQA}.
Exploring Opinion-unaware Video Quality Assessment with Semantic Affinity Criterion
Feb 26, 2023



Recent learning-based video quality assessment (VQA) algorithms are expensive to implement due to the cost of data collection of human quality opinions, and are less robust across various scenarios due to the biases of these opinions. This motivates our exploration on opinion-unaware (a.k.a zero-shot) VQA approaches. Existing approaches only considers low-level naturalness in spatial or temporal domain, without considering impacts from high-level semantics. In this work, we introduce an explicit semantic affinity index for opinion-unaware VQA using text-prompts in the contrastive language-image pre-training (CLIP) model. We also aggregate it with different traditional low-level naturalness indexes through gaussian normalization and sigmoid rescaling strategies. Composed of aggregated semantic and technical metrics, the proposed Blind Unified Opinion-Unaware Video Quality Index via Semantic and Technical Metric Aggregation (BUONA-VISTA) outperforms existing opinion-unaware VQA methods by at least 20% improvements, and is more robust than opinion-aware approaches.