 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJust Noticeable Difference Modeling for Deep Visual Features
Jan 29, 2026Deep visual features are increasingly used as the interface in vision systems, motivating the need to describe feature characteristics and control feature quality for machine perception. Just noticeable difference (JND) characterizes the maximum imperceptible distortion for images under human or machine vision. Extending it to deep visual features naturally meets the above demand by providing a task-aligned tolerance boundary in feature space, offering a practical reference for controlling feature quality under constrained resources. We propose FeatJND, a task-aligned JND formulation that predicts the maximum tolerable per-feature perturbation map while preserving downstream task performance. We propose a FeatJND estimator at standardized split points and validate it across image classification, detection, and instance segmentation. Under matched distortion strength, FeatJND-based distortions consistently preserve higher task performance than unstructured Gaussian perturbations, and attribution visualizations suggest FeatJND can suppress non-critical feature regions. As an application, we further apply FeatJND to token-wise dynamic quantization and show that FeatJND-guided step-size allocation yields clear gains over random step-size permutation and global uniform step size under the same noise budget. Our code will be released after publication.
From Global to Granular: Revealing IQA Model Performance via Correlation Surface
Jan 29, 2026Evaluation of Image Quality Assessment (IQA) models has long been dominated by global correlation metrics, such as Pearson Linear Correlation Coefficient (PLCC) and Spearman Rank-Order Correlation Coefficient (SRCC). While widely adopted, these metrics reduce performance to a single scalar, failing to capture how ranking consistency varies across the local quality spectrum. For example, two IQA models may achieve identical SRCC values, yet one ranks high-quality images (related to high Mean Opinion Score, MOS) more reliably, while the other better discriminates image pairs with small quality/MOS differences (related to $|Δ$MOS$|$). Such complementary behaviors are invisible under global metrics. Moreover, SRCC and PLCC are sensitive to test-sample quality distributions, yielding unstable comparisons across test sets. To address these limitations, we propose \textbf{Granularity-Modulated Correlation (GMC)}, which provides a structured, fine-grained analysis of IQA performance. GMC includes: (1) a \textbf{Granularity Modulator} that applies Gaussian-weighted correlations conditioned on absolute MOS values and pairwise MOS differences ($|Δ$MOS$|$) to examine local performance variations, and (2) a \textbf{Distribution Regulator} that regularizes correlations to mitigate biases from non-uniform quality distributions. The resulting \textbf{correlation surface} maps correlation values as a joint function of MOS and $|Δ$MOS$|$, providing a 3D representation of IQA performance. Experiments on standard benchmarks show that GMC reveals performance characteristics invisible to scalar metrics, offering a more informative and reliable paradigm for analyzing, comparing, and deploying IQA models. Codes are available at https://github.com/Dniaaa/GMC.
RLPO: Residual Listwise Preference Optimization for Long-Context Review Ranking
Jan 12, 2026Review ranking is pivotal in e-commerce for prioritizing diagnostic and authentic feedback from the deluge of user-generated content. While large language models have improved semantic assessment, existing ranking paradigms face a persistent trade-off in long-context settings. Pointwise scoring is efficient but often fails to account for list-level interactions, leading to miscalibrated top-$k$ rankings. Listwise approaches can leverage global context, yet they are computationally expensive and become unstable as candidate lists grow. To address this, we propose Residual Listwise Preference Optimization (RLPO), which formulates ranking as listwise representation-level residual correction over a strong pointwise LLM scorer. RLPO first produces calibrated pointwise scores and item representations, then applies a lightweight encoder over the representations to predict listwise score residuals, avoiding full token-level listwise processing. We also introduce a large-scale benchmark for long-context review ranking with human verification. Experiments show RLPO improves NDCG@k over strong pointwise and listwise baselines and remains robust as list length increases.
Plug In, Grade Right: Psychology-Inspired AGIQA
Dec 28, 2025Existing AGIQA models typically estimate image quality by measuring and aggregating the similarities between image embeddings and text embeddings derived from multi-grade quality descriptions. Although effective, we observe that such similarity distributions across grades usually exhibit multimodal patterns. For instance, an image embedding may show high similarity to both "excellent" and "poor" grade descriptions while deviating from the "good" one. We refer to this phenomenon as "semantic drift", where semantic inconsistencies between text embeddings and their intended descriptions undermine the reliability of text-image shared-space learning. To mitigate this issue, we draw inspiration from psychometrics and propose an improved Graded Response Model (GRM) for AGIQA. The GRM is a classical assessment model that categorizes a subject's ability across grades using test items with various difficulty levels. This paradigm aligns remarkably well with human quality rating, where image quality can be interpreted as an image's ability to meet various quality grades. Building on this philosophy, we design a two-branch quality grading module: one branch estimates image ability while the other constructs multiple difficulty levels. To ensure monotonicity in difficulty levels, we further model difficulty generation in an arithmetic manner, which inherently enforces a unimodal and interpretable quality distribution. Our Arithmetic GRM based Quality Grading (AGQG) module enjoys a plug-and-play advantage, consistently improving performance when integrated into various state-of-the-art AGIQA frameworks. Moreover, it also generalizes effectively to both natural and screen content image quality assessment, revealing its potential as a key component in future IQA models.
Using GUI Agent for Electronic Design Automation
Dec 12, 2025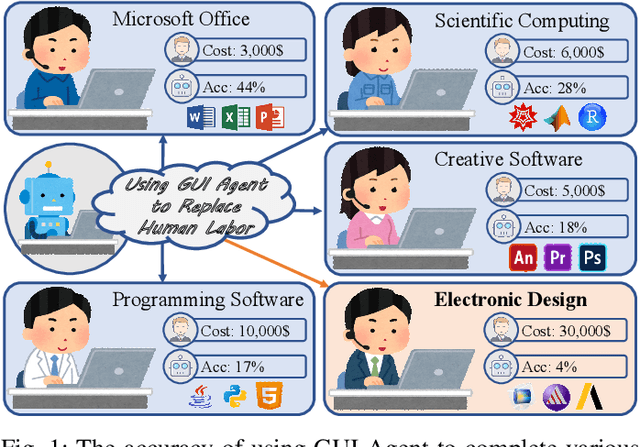
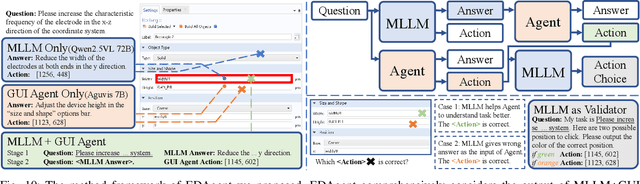
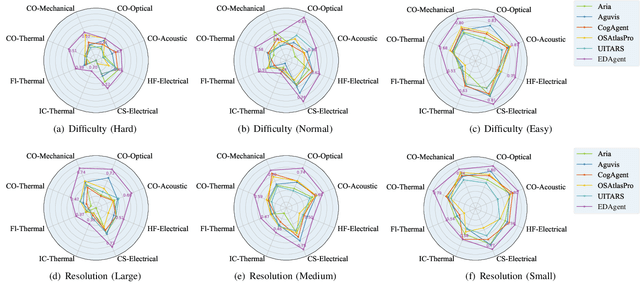
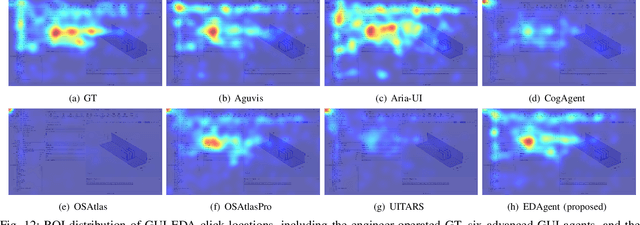
Graphical User Interface (GUI) agents adopt an end-to-end paradigm that maps a screenshot to an action sequence, thereby automating repetitive tasks in virtual environments. However, existing GUI agents are evaluated almost exclusively on commodity software such as Microsoft Word and Excel. Professional Computer-Aided Design (CAD) suites promise an order-of-magnitude higher economic return, yet remain the weakest performance domain for existing agents and are still far from replacing expert Electronic-Design-Automation (EDA) engineers. We therefore present the first systematic study that deploys GUI agents for EDA workflows. Our contributions are: (1) a large-scale dataset named GUI-EDA, including 5 CAD tools and 5 physical domains, comprising 2,000+ high-quality screenshot-answer-action pairs recorded by EDA scientists and engineers during real-world component design; (2) a comprehensive benchmark that evaluates 30+ mainstream GUI agents, demonstrating that EDA tasks constitute a major, unsolved challenge; and (3) an EDA-specialized metric named EDAgent, equipped with a reflection mechanism that achieves reliable performance on industrial CAD software and, for the first time, outperforms Ph.D. students majored in Electrical Engineering. This work extends GUI agents from generic office automation to specialized, high-value engineering domains and offers a new avenue for advancing EDA productivity. The dataset will be released at: https://github.com/aiben-ch/GUI-EDA.
Embodied Image Compression
Dec 12, 2025
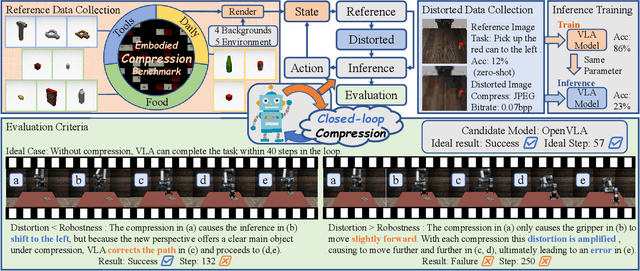
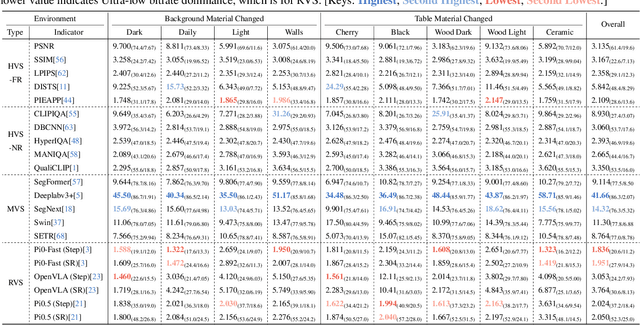
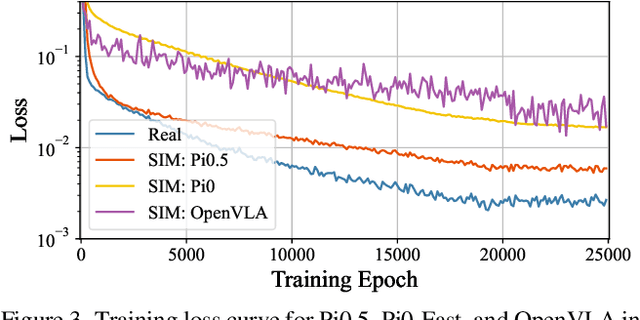
Image Compression for Machines (ICM) has emerged as a pivotal research direction in the field of visual data compression. However, with the rapid evolution of machine intelligence, the target of compression has shifted from task-specific virtual models to Embodied agents operating in real-world environments. To address the communication constraints of Embodied AI in multi-agent systems and ensure real-time task execution, this paper introduces, for the first time, the scientific problem of Embodied Image Compression. We establish a standardized benchmark, EmbodiedComp, to facilitate systematic evaluation under ultra-low bitrate conditions in a closed-loop setting. Through extensive empirical studies in both simulated and real-world settings, we demonstrate that existing Vision-Language-Action models (VLAs) fail to reliably perform even simple manipulation tasks when compressed below the Embodied bitrate threshold. We anticipate that EmbodiedComp will catalyze the development of domain-specific compression tailored for Embodied agents , thereby accelerating the Embodied AI deployment in the Real-world.
SFP: Real-World Scene Recovery Using Spatial and Frequency Priors
Dec 09, 2025
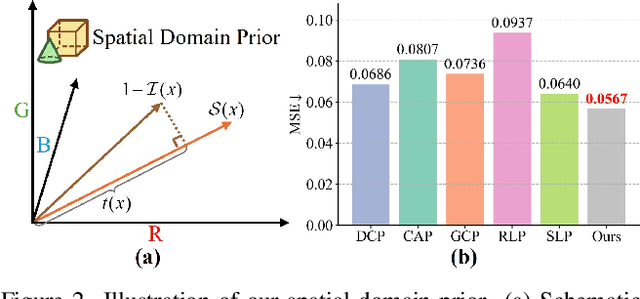
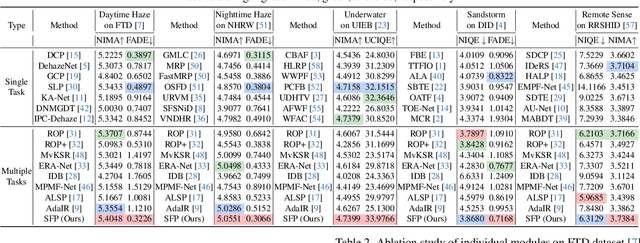
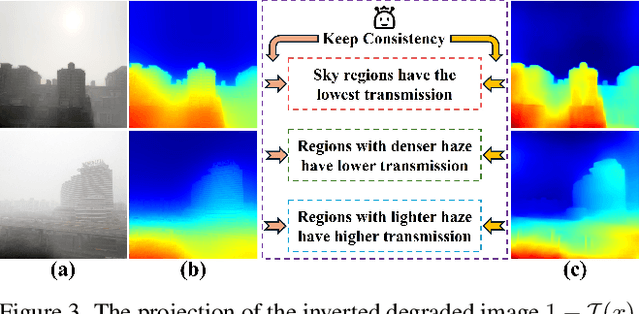
Scene recovery serves as a critical task for various computer vision applications. Existing methods typically rely on a single prior, which is inherently insufficient to handle multiple degradations, or employ complex network architectures trained on synthetic data, which suffer from poor generalization for diverse real-world scenarios. In this paper, we propose Spatial and Frequency Priors (SFP) for real-world scene recovery. In the spatial domain, we observe that the inverse of the degraded image exhibits a projection along its spectral direction that resembles the scene transmission. Leveraging this spatial prior, the transmission map is estimated to recover the scene from scattering degradation. In the frequency domain, a mask is constructed for adaptive frequency enhancement, with two parameters estimated using our proposed novel priors. Specifically, one prior assumes that the mean intensity of the degraded image's direct current (DC) components across three channels in the frequency domain closely approximates that of each channel in the clear image. The second prior is based on the observation that, for clear images, the magnitude of low radial frequencies below 0.001 constitutes approximately 1% of the total spectrum. Finally, we design a weighted fusion strategy to integrate spatial-domain restoration, frequency-domain enhancement, and salient features from the input image, yielding the final recovered result. Extensive evaluations demonstrate the effectiveness and superiority of our proposed SFP for scene recovery under various degradation conditions.
MUGSQA: Novel Multi-Uncertainty-Based Gaussian Splatting Quality Assessment Method, Dataset, and Benchmarks
Nov 10, 2025

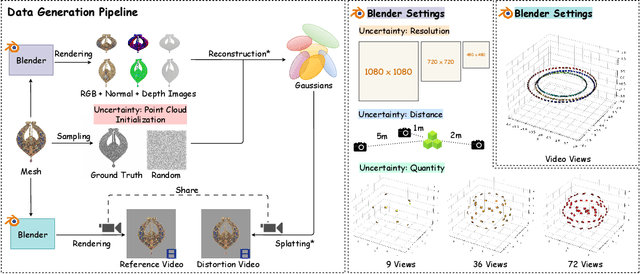
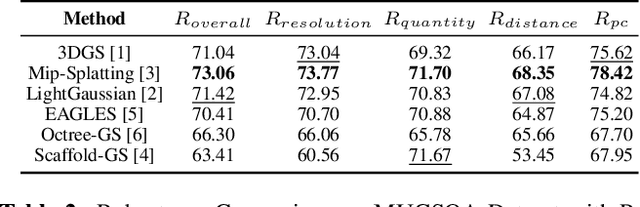
Gaussian Splatting (GS) has recently emerged as a promising technique for 3D object reconstruction, delivering high-quality rendering results with significantly improved reconstruction speed. As variants continue to appear, assessing the perceptual quality of 3D objects reconstructed with different GS-based methods remains an open challenge. To address this issue, we first propose a unified multi-distance subjective quality assessment method that closely mimics human viewing behavior for objects reconstructed with GS-based methods in actual applications, thereby better collecting perceptual experiences. Based on it, we also construct a novel GS quality assessment dataset named MUGSQA, which is constructed considering multiple uncertainties of the input data. These uncertainties include the quantity and resolution of input views, the view distance, and the accuracy of the initial point cloud. Moreover, we construct two benchmarks: one to evaluate the robustness of various GS-based reconstruction methods under multiple uncertainties, and the other to evaluate the performance of existing quality assessment metrics. Our dataset and benchmark code will be released soon.
Image Quality Assessment for Machines: Paradigm, Large-scale Database, and Models
Aug 27, 2025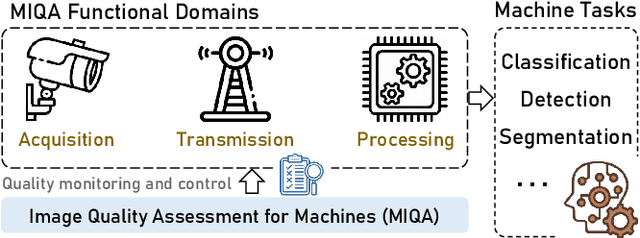

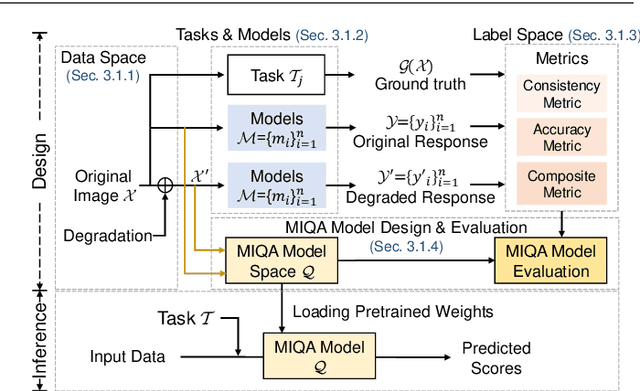
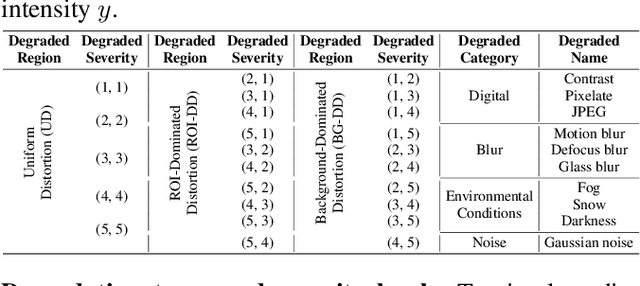
Machine vision systems (MVS) are intrinsically vulnerable to performance degradation under adverse visual conditions. To address this, we propose a machine-centric image quality assessment (MIQA) framework that quantifies the impact of image degradations on MVS performance. We establish an MIQA paradigm encompassing the end-to-end assessment workflow. To support this, we construct a machine-centric image quality database (MIQD-2.5M), comprising 2.5 million samples that capture distinctive degradation responses in both consistency and accuracy metrics, spanning 75 vision models, 250 degradation types, and three representative vision tasks. We further propose a region-aware MIQA (RA-MIQA) model to evaluate MVS visual quality through fine-grained spatial degradation analysis. Extensive experiments benchmark the proposed RA-MIQA against seven human visual system (HVS)-based IQA metrics and five retrained classical backbones. Results demonstrate RA-MIQA's superior performance in multiple dimensions, e.g., achieving SRCC gains of 13.56% on consistency and 13.37% on accuracy for image classification, while also revealing task-specific degradation sensitivities. Critically, HVS-based metrics prove inadequate for MVS quality prediction, while even specialized MIQA models struggle with background degradations, accuracy-oriented estimation, and subtle distortions. This study can advance MVS reliability and establish foundations for machine-centric image processing and optimization. The model and code are available at: https://github.com/XiaoqiWang/MIQA.
Power Battery Detection
Aug 11, 2025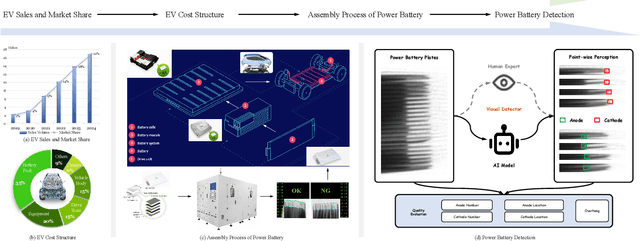



Power batteries are essential components in electric vehicles, where internal structural defects can pose serious safety risks. We conduct a comprehensive study on a new task, power battery detection (PBD), which aims to localize the dense endpoints of cathode and anode plates from industrial X-ray images for quality inspection. Manual inspection is inefficient and error-prone, while traditional vision algorithms struggle with densely packed plates, low contrast, scale variation, and imaging artifacts. To address this issue and drive more attention into this meaningful task, we present PBD5K, the first large-scale benchmark for this task, consisting of 5,000 X-ray images from nine battery types with fine-grained annotations and eight types of real-world visual interference. To support scalable and consistent labeling, we develop an intelligent annotation pipeline that combines image filtering, model-assisted pre-labeling, cross-verification, and layered quality evaluation. We formulate PBD as a point-level segmentation problem and propose MDCNeXt, a model designed to extract and integrate multi-dimensional structure clues including point, line, and count information from the plate itself. To improve discrimination between plates and suppress visual interference, MDCNeXt incorporates two state space modules. The first is a prompt-filtered module that learns contrastive relationships guided by task-specific prompts. The second is a density-aware reordering module that refines segmentation in regions with high plate density. In addition, we propose a distance-adaptive mask generation strategy to provide robust supervision under varying spatial distributions of anode and cathode positions. The source code and datasets will be publicly available at \href{https://github.com/Xiaoqi-Zhao-DLUT/X-ray-PBD}{PBD5K}.