 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMambaVSR: Content-Aware Scanning State Space Model for Video Super-Resolution
Jun 13, 2025Video super-resolution (VSR) faces critical challenges in effectively modeling non-local dependencies across misaligned frames while preserving computational efficiency. Existing VSR methods typically rely on optical flow strategies or transformer architectures, which struggle with large motion displacements and long video sequences. To address this, we propose MambaVSR, the first state-space model framework for VSR that incorporates an innovative content-aware scanning mechanism. Unlike rigid 1D sequential processing in conventional vision Mamba methods, our MambaVSR enables dynamic spatiotemporal interactions through the Shared Compass Construction (SCC) and the Content-Aware Sequentialization (CAS). Specifically, the SCC module constructs intra-frame semantic connectivity graphs via efficient sparse attention and generates adaptive spatial scanning sequences through spectral clustering. Building upon SCC, the CAS module effectively aligns and aggregates non-local similar content across multiple frames by interleaving temporal features along the learned spatial order. To bridge global dependencies with local details, the Global-Local State Space Block (GLSSB) synergistically integrates window self-attention operations with SSM-based feature propagation, enabling high-frequency detail recovery under global dependency guidance. Extensive experiments validate MambaVSR's superiority, outperforming the Transformer-based method by 0.58 dB PSNR on the REDS dataset with 55% fewer parameters.
Multi-agent Embodied AI: Advances and Future Directions
May 08, 2025Embodied artificial intelligence (Embodied AI) plays a pivotal role in the application of advanced technologies in the intelligent era, where AI systems are integrated with physical bodies that enable them to perceive, reason, and interact with their environments. Through the use of sensors for input and actuators for action, these systems can learn and adapt based on real-world feedback, allowing them to perform tasks effectively in dynamic and unpredictable environments. As techniques such as deep learning (DL), reinforcement learning (RL), and large language models (LLMs) mature, embodied AI has become a leading field in both academia and industry, with applications spanning robotics, healthcare, transportation, and manufacturing. However, most research has focused on single-agent systems that often assume static, closed environments, whereas real-world embodied AI must navigate far more complex scenarios. In such settings, agents must not only interact with their surroundings but also collaborate with other agents, necessitating sophisticated mechanisms for adaptation, real-time learning, and collaborative problem-solving. Despite increasing interest in multi-agent systems, existing research remains narrow in scope, often relying on simplified models that fail to capture the full complexity of dynamic, open environments for multi-agent embodied AI. Moreover, no comprehensive survey has systematically reviewed the advancements in this area. As embodied AI rapidly evolves, it is crucial to deepen our understanding of multi-agent embodied AI to address the challenges presented by real-world applications. To fill this gap and foster further development in the field, this paper reviews the current state of research, analyzes key contributions, and identifies challenges and future directions, providing insights to guide innovation and progress in this field.
TransVFC: A Transformable Video Feature Compression Framework for Machines
Mar 31, 2025Nowadays, more and more video transmissions primarily aim at downstream machine vision tasks rather than humans. While widely deployed Human Visual System (HVS) oriented video coding standards like H.265/HEVC and H.264/AVC are efficient, they are not the optimal approaches for Video Coding for Machines (VCM) scenarios, leading to unnecessary bitrate expenditure. The academic and technical exploration within the VCM domain has led to the development of several strategies, and yet, conspicuous limitations remain in their adaptability for multi-task scenarios. To address the challenge, we propose a Transformable Video Feature Compression (TransVFC) framework. It offers a compress-then-transfer solution and includes a video feature codec and Feature Space Transform (FST) modules. In particular, the temporal redundancy of video features is squeezed by the codec through the scheme-based inter-prediction module. Then, the codec implements perception-guided conditional coding to minimize spatial redundancy and help the reconstructed features align with downstream machine perception.After that, the reconstructed features are transferred to new feature spaces for diverse downstream tasks by FST modules. To accommodate a new downstream task, it only requires training one lightweight FST module, avoiding retraining and redeploying the upstream codec and downstream task networks. Experiments show that TransVFC achieves high rate-task performance for diverse tasks of different granularities. We expect our work can provide valuable insights for video feature compression in multi-task scenarios. The codes are at https://github.com/Ws-Syx/TransVFC.
Embedding Compression Distortion in Video Coding for Machines
Mar 27, 2025Currently, video transmission serves not only the Human Visual System (HVS) for viewing but also machine perception for analysis. However, existing codecs are primarily optimized for pixel-domain and HVS-perception metrics rather than the needs of machine vision tasks. To address this issue, we propose a Compression Distortion Representation Embedding (CDRE) framework, which extracts machine-perception-related distortion representation and embeds it into downstream models, addressing the information lost during compression and improving task performance. Specifically, to better analyze the machine-perception-related distortion, we design a compression-sensitive extractor that identifies compression degradation in the feature domain. For efficient transmission, a lightweight distortion codec is introduced to compress the distortion information into a compact representation. Subsequently, the representation is progressively embedded into the downstream model, enabling it to be better informed about compression degradation and enhancing performance. Experiments across various codecs and downstream tasks demonstrate that our framework can effectively boost the rate-task performance of existing codecs with minimal overhead in terms of bitrate, execution time, and number of parameters. Our codes and supplementary materials are released in https://github.com/Ws-Syx/CDRE/.
SeeClear: Semantic Distillation Enhances Pixel Condensation for Video Super-Resolution
Oct 08, 2024Diffusion-based Video Super-Resolution (VSR) is renowned for generating perceptually realistic videos, yet it grapples with maintaining detail consistency across frames due to stochastic fluctuations. The traditional approach of pixel-level alignment is ineffective for diffusion-processed frames because of iterative disruptions. To overcome this, we introduce SeeClear--a novel VSR framework leveraging conditional video generation, orchestrated by instance-centric and channel-wise semantic controls. This framework integrates a Semantic Distiller and a Pixel Condenser, which synergize to extract and upscale semantic details from low-resolution frames. The Instance-Centric Alignment Module (InCAM) utilizes video-clip-wise tokens to dynamically relate pixels within and across frames, enhancing coherency. Additionally, the Channel-wise Texture Aggregation Memory (CaTeGory) infuses extrinsic knowledge, capitalizing on long-standing semantic textures. Our method also innovates the blurring diffusion process with the ResShift mechanism, finely balancing between sharpness and diffusion effects. Comprehensive experiments confirm our framework's advantage over state-of-the-art diffusion-based VSR techniques. The code is available: https://github.com/Tang1705/SeeClear-NeurIPS24.
Relation DETR: Exploring Explicit Position Relation Prior for Object Detection
Jul 16, 2024This paper presents a general scheme for enhancing the convergence and performance of DETR (DEtection TRansformer). We investigate the slow convergence problem in transformers from a new perspective, suggesting that it arises from the self-attention that introduces no structural bias over inputs. To address this issue, we explore incorporating position relation prior as attention bias to augment object detection, following the verification of its statistical significance using a proposed quantitative macroscopic correlation (MC) metric. Our approach, termed Relation-DETR, introduces an encoder to construct position relation embeddings for progressive attention refinement, which further extends the traditional streaming pipeline of DETR into a contrastive relation pipeline to address the conflicts between non-duplicate predictions and positive supervision. Extensive experiments on both generic and task-specific datasets demonstrate the effectiveness of our approach. Under the same configurations, Relation-DETR achieves a significant improvement (+2.0% AP compared to DINO), state-of-the-art performance (51.7% AP for 1x and 52.1% AP for 2x settings), and a remarkably faster convergence speed (over 40% AP with only 2 training epochs) than existing DETR detectors on COCO val2017. Moreover, the proposed relation encoder serves as a universal plug-in-and-play component, bringing clear improvements for theoretically any DETR-like methods. Furthermore, we introduce a class-agnostic detection dataset, SA-Det-100k. The experimental results on the dataset illustrate that the proposed explicit position relation achieves a clear improvement of 1.3% AP, highlighting its potential towards universal object detection. The code and dataset are available at https://github.com/xiuqhou/Relation-DETR.
Cooperative Reward Shaping for Multi-Agent Pathfinding
Jul 15, 2024The primary objective of Multi-Agent Pathfinding (MAPF) is to plan efficient and conflict-free paths for all agents. Traditional multi-agent path planning algorithms struggle to achieve efficient distributed path planning for multiple agents. In contrast, Multi-Agent Reinforcement Learning (MARL) has been demonstrated as an effective approach to achieve this objective. By modeling the MAPF problem as a MARL problem, agents can achieve efficient path planning and collision avoidance through distributed strategies under partial observation. However, MARL strategies often lack cooperation among agents due to the absence of global information, which subsequently leads to reduced MAPF efficiency. To address this challenge, this letter introduces a unique reward shaping technique based on Independent Q-Learning (IQL). The aim of this method is to evaluate the influence of one agent on its neighbors and integrate such an interaction into the reward function, leading to active cooperation among agents. This reward shaping method facilitates cooperation among agents while operating in a distributed manner. The proposed approach has been evaluated through experiments across various scenarios with different scales and agent counts. The results are compared with those from other state-of-the-art (SOTA) planners. The evidence suggests that the approach proposed in this letter parallels other planners in numerous aspects, and outperforms them in scenarios featuring a large number of agents.
I$^2$VC: A Unified Framework for Intra- \& Inter-frame Video Compression
May 23, 2024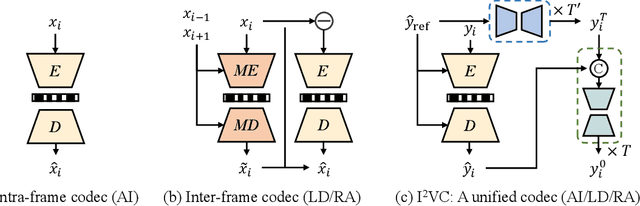
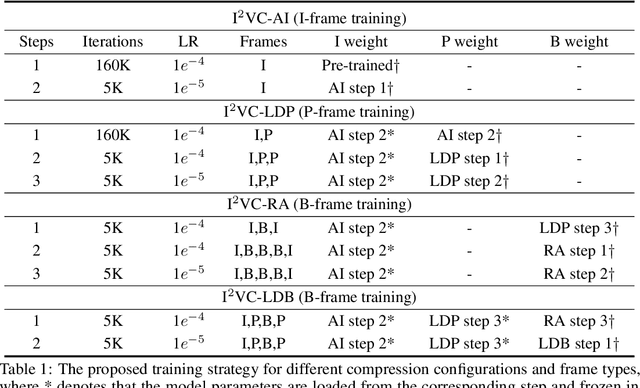
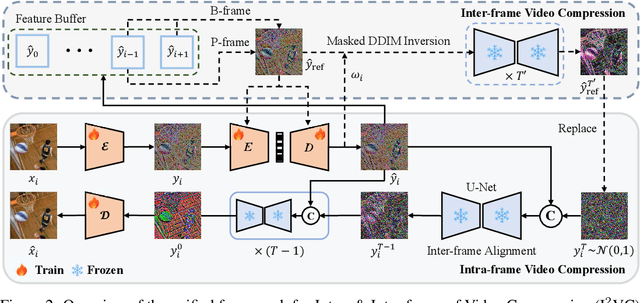
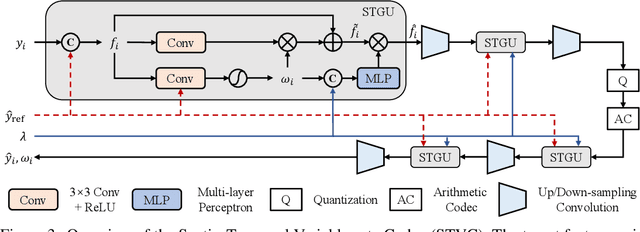
Video compression aims to reconstruct seamless frames by encoding the motion and residual information from existing frames. Previous neural video compression methods necessitate distinct codecs for three types of frames (I-frame, P-frame and B-frame), which hinders a unified approach and generalization across different video contexts. Intra-codec techniques lack the advanced Motion Estimation and Motion Compensation (MEMC) found in inter-codec, leading to fragmented frameworks lacking uniformity. Our proposed \textbf{Intra- \& Inter-frame Video Compression (I$^2$VC)} framework employs a single spatio-temporal codec that guides feature compression rates according to content importance. This unified codec transforms the dependence across frames into a conditional coding scheme, thus integrating intra- and inter-frame compression into one cohesive strategy. Given the absence of explicit motion data, achieving competent inter-frame compression with only a conditional codec poses a challenge. To resolve this, our approach includes an implicit inter-frame alignment mechanism. With the pre-trained diffusion denoising process, the utilization of a diffusion-inverted reference feature rather than random noise supports the initial compression state. This process allows for selective denoising of motion-rich regions based on decoded features, facilitating accurate alignment without the need for MEMC. Our experimental findings, across various compression configurations (AI, LD and RA) and frame types, prove that I$^2$VC outperforms the state-of-the-art perceptual learned codecs. Impressively, it exhibits a 58.4\% enhancement in perceptual reconstruction performance when benchmarked against the H.266/VVC standard (VTM). Official implementation can be found at \href{https://github.com/GYukai/I2VC}{https://github.com/GYukai/I2VC}
Salience DETR: Enhancing Detection Transformer with Hierarchical Salience Filtering Refinement
Mar 24, 2024



DETR-like methods have significantly increased detection performance in an end-to-end manner. The mainstream two-stage frameworks of them perform dense self-attention and select a fraction of queries for sparse cross-attention, which is proven effective for improving performance but also introduces a heavy computational burden and high dependence on stable query selection. This paper demonstrates that suboptimal two-stage selection strategies result in scale bias and redundancy due to the mismatch between selected queries and objects in two-stage initialization. To address these issues, we propose hierarchical salience filtering refinement, which performs transformer encoding only on filtered discriminative queries, for a better trade-off between computational efficiency and precision. The filtering process overcomes scale bias through a novel scale-independent salience supervision. To compensate for the semantic misalignment among queries, we introduce elaborate query refinement modules for stable two-stage initialization. Based on above improvements, the proposed Salience DETR achieves significant improvements of +4.0% AP, +0.2% AP, +4.4% AP on three challenging task-specific detection datasets, as well as 49.2% AP on COCO 2017 with less FLOPs. The code is available at https://github.com/xiuqhou/Salience-DETR.
Semantic Lens: Instance-Centric Semantic Alignment for Video Super-Resolution
Dec 23, 2023



As a critical clue of video super-resolution (VSR), inter-frame alignment significantly impacts overall performance. However, accurate pixel-level alignment is a challenging task due to the intricate motion interweaving in the video. In response to this issue, we introduce a novel paradigm for VSR named Semantic Lens, predicated on semantic priors drawn from degraded videos. Specifically, video is modeled as instances, events, and scenes via a Semantic Extractor. Those semantics assist the Pixel Enhancer in understanding the recovered contents and generating more realistic visual results. The distilled global semantics embody the scene information of each frame, while the instance-specific semantics assemble the spatial-temporal contexts related to each instance. Furthermore, we devise a Semantics-Powered Attention Cross-Embedding (SPACE) block to bridge the pixel-level features with semantic knowledge, composed of a Global Perspective Shifter (GPS) and an Instance-Specific Semantic Embedding Encoder (ISEE). Concretely, the GPS module generates pairs of affine transformation parameters for pixel-level feature modulation conditioned on global semantics. After that, the ISEE module harnesses the attention mechanism to align the adjacent frames in the instance-centric semantic space. In addition, we incorporate a simple yet effective pre-alignment module to alleviate the difficulty of model training. Extensive experiments demonstrate the superiority of our model over existing state-of-the-art VSR methods.