 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVIPER: Process-aware Evaluation for Generative Video Reasoning
Dec 31, 2025Recent breakthroughs in video generation have demonstrated an emerging capability termed Chain-of-Frames (CoF) reasoning, where models resolve complex tasks through the generation of continuous frames. While these models show promise for Generative Video Reasoning (GVR), existing evaluation frameworks often rely on single-frame assessments, which can lead to outcome-hacking, where a model reaches a correct conclusion through an erroneous process. To address this, we propose a process-aware evaluation paradigm. We introduce VIPER, a comprehensive benchmark spanning 16 tasks across temporal, structural, symbolic, spatial, physics, and planning reasoning. Furthermore, we propose Process-outcome Consistency (POC@r), a new metric that utilizes VLM-as-Judge with a hierarchical rubric to evaluate both the validity of the intermediate steps and the final result. Our experiments reveal that state-of-the-art video models achieve only about 20% POC@1.0 and exhibit a significant outcome-hacking. We further explore the impact of test-time scaling and sampling robustness, highlighting a substantial gap between current video generation and true generalized visual reasoning. Our benchmark will be publicly released.
I$^2$VC: A Unified Framework for Intra- \& Inter-frame Video Compression
May 23, 2024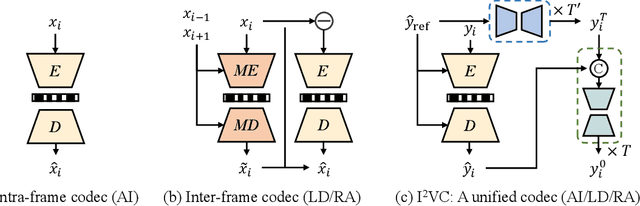
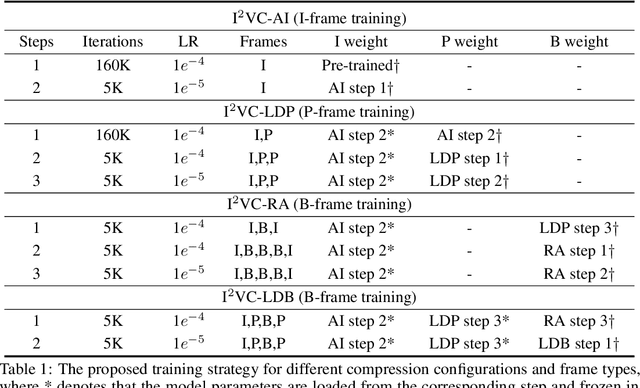
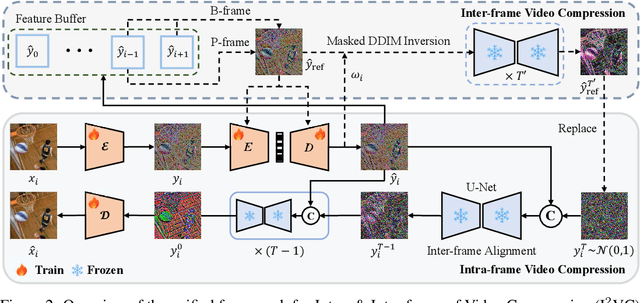
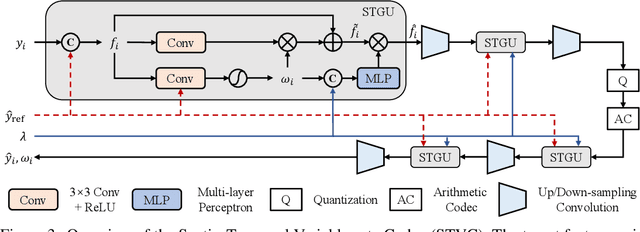
Video compression aims to reconstruct seamless frames by encoding the motion and residual information from existing frames. Previous neural video compression methods necessitate distinct codecs for three types of frames (I-frame, P-frame and B-frame), which hinders a unified approach and generalization across different video contexts. Intra-codec techniques lack the advanced Motion Estimation and Motion Compensation (MEMC) found in inter-codec, leading to fragmented frameworks lacking uniformity. Our proposed \textbf{Intra- \& Inter-frame Video Compression (I$^2$VC)} framework employs a single spatio-temporal codec that guides feature compression rates according to content importance. This unified codec transforms the dependence across frames into a conditional coding scheme, thus integrating intra- and inter-frame compression into one cohesive strategy. Given the absence of explicit motion data, achieving competent inter-frame compression with only a conditional codec poses a challenge. To resolve this, our approach includes an implicit inter-frame alignment mechanism. With the pre-trained diffusion denoising process, the utilization of a diffusion-inverted reference feature rather than random noise supports the initial compression state. This process allows for selective denoising of motion-rich regions based on decoded features, facilitating accurate alignment without the need for MEMC. Our experimental findings, across various compression configurations (AI, LD and RA) and frame types, prove that I$^2$VC outperforms the state-of-the-art perceptual learned codecs. Impressively, it exhibits a 58.4\% enhancement in perceptual reconstruction performance when benchmarked against the H.266/VVC standard (VTM). Official implementation can be found at \href{https://github.com/GYukai/I2VC}{https://github.com/GYukai/I2VC}
An LLM-free Multi-dimensional Benchmark for MLLMs Hallucination Evaluation
Nov 13, 2023Despite making significant progress in multi-modal tasks, current Multi-modal Large Language Models (MLLMs) encounter the significant challenge of hallucination, which may lead to harmful consequences. Therefore, evaluating MLLMs' hallucinations is becoming increasingly important in model improvement and practical application deployment. Previous works are limited in high evaluation costs (e.g., relying on humans or advanced LLMs) and insufficient evaluation dimensions (e.g., types of hallucination and task). In this paper, we propose an LLM-free multi-dimensional benchmark AMBER, which can be used to evaluate both generative task and discriminative task including object existence, object attribute and object relation hallucination. Based on AMBER, we design a low-cost and efficient evaluation pipeline. Additionally, we conduct a comprehensive evaluation and detailed analysis of mainstream MLLMs including GPT-4V(ision), and also give guideline suggestions for mitigating hallucinations. The data and code of AMBER are available at https://github.com/junyangwang0410/AMBER.