 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeREDSearcher: A Scalable and Cost-Efficient Framework for Long-Horizon Search Agents
Feb 15, 2026Large language models are transitioning from generalpurpose knowledge engines to realworld problem solvers, yet optimizing them for deep search tasks remains challenging. The central bottleneck lies in the extreme sparsity of highquality search trajectories and reward signals, arising from the difficulty of scalable longhorizon task construction and the high cost of interactionheavy rollouts involving external tool calls. To address these challenges, we propose REDSearcher, a unified framework that codesigns complex task synthesis, midtraining, and posttraining for scalable searchagent optimization. Specifically, REDSearcher introduces the following improvements: (1) We frame task synthesis as a dualconstrained optimization, where task difficulty is precisely governed by graph topology and evidence dispersion, allowing scalable generation of complex, highquality tasks. (2) We introduce toolaugmented queries to encourage proactive tool use rather than passive recall.(3) During midtraining, we strengthen core atomic capabilities knowledge, planning, and function calling substantially reducing the cost of collecting highquality trajectories for downstream training. (4) We build a local simulated environment that enables rapid, lowcost algorithmic iteration for reinforcement learning experiments. Across both textonly and multimodal searchagent benchmarks, our approach achieves stateoftheart performance. To facilitate future research on longhorizon search agents, we will release 10K highquality complex text search trajectories, 5K multimodal trajectories and 1K text RL query set, and together with code and model checkpoints.
DeepEyesV2: Toward Agentic Multimodal Model
Nov 10, 2025Agentic multimodal models should not only comprehend text and images, but also actively invoke external tools, such as code execution environments and web search, and integrate these operations into reasoning. In this work, we introduce DeepEyesV2 and explore how to build an agentic multimodal model from the perspectives of data construction, training methods, and model evaluation. We observe that direct reinforcement learning alone fails to induce robust tool-use behavior. This phenomenon motivates a two-stage training pipeline: a cold-start stage to establish tool-use patterns, and reinforcement learning stage to further refine tool invocation. We curate a diverse, moderately challenging training dataset, specifically including examples where tool use is beneficial. We further introduce RealX-Bench, a comprehensive benchmark designed to evaluate real-world multimodal reasoning, which inherently requires the integration of multiple capabilities, including perception, search, and reasoning. We evaluate DeepEyesV2 on RealX-Bench and other representative benchmarks, demonstrating its effectiveness across real-world understanding, mathematical reasoning, and search-intensive tasks. Moreover, DeepEyesV2 exhibits task-adaptive tool invocation, tending to use image operations for perception tasks and numerical computations for reasoning tasks. Reinforcement learning further enables complex tool combinations and allows model to selectively invoke tools based on context. We hope our study can provide guidance for community in developing agentic multimodal models.
DeepEyes: Incentivizing "Thinking with Images" via Reinforcement Learning
May 20, 2025Large Vision-Language Models (VLMs) have shown strong capabilities in multimodal understanding and reasoning, yet they are primarily constrained by text-based reasoning processes. However, achieving seamless integration of visual and textual reasoning which mirrors human cognitive processes remains a significant challenge. In particular, effectively incorporating advanced visual input processing into reasoning mechanisms is still an open question. Thus, in this paper, we explore the interleaved multimodal reasoning paradigm and introduce DeepEyes, a model with "thinking with images" capabilities incentivized through end-to-end reinforcement learning without the need for cold-start SFT. Notably, this ability emerges natively within the model itself, leveraging its inherent grounding ability as a tool instead of depending on separate specialized models. Specifically, we propose a tool-use-oriented data selection mechanism and a reward strategy to encourage successful tool-assisted reasoning trajectories. DeepEyes achieves significant performance gains on fine-grained perception and reasoning benchmarks and also demonstrates improvement in grounding, hallucination, and mathematical reasoning tasks. Interestingly, we observe the distinct evolution of tool-calling behavior from initial exploration to efficient and accurate exploitation, and diverse thinking patterns that closely mirror human visual reasoning processes. Code is available at https://github.com/Visual-Agent/DeepEyes.
Exploring Implicit Visual Misunderstandings in Multimodal Large Language Models through Attention Analysis
May 15, 2025Recent advancements have enhanced the capability of Multimodal Large Language Models (MLLMs) to comprehend multi-image information. However, existing benchmarks primarily evaluate answer correctness, overlooking whether models genuinely comprehend the visual input. To address this, we define implicit visual misunderstanding (IVM), where MLLMs provide correct answers without fully comprehending the visual input. Through our analysis, we decouple the visual and textual modalities within the causal attention module, revealing that attention distribution increasingly converges on the image associated with the correct answer as the network layers deepen. This insight leads to the introduction of a scale-agnostic metric, \textit{attention accuracy}, and a novel benchmark for quantifying IVMs. Attention accuracy directly evaluates the model's visual understanding via internal mechanisms, remaining robust to positional biases for more reliable assessments. Furthermore, we extend our approach to finer granularities and demonstrate its effectiveness in unimodal scenarios, underscoring its versatility and generalizability.
MLLM-Selector: Necessity and Diversity-driven High-Value Data Selection for Enhanced Visual Instruction Tuning
Mar 26, 2025Visual instruction tuning (VIT) has emerged as a crucial technique for enabling multi-modal large language models (MLLMs) to follow user instructions adeptly. Yet, a significant gap persists in understanding the attributes of high-quality instruction tuning data and frameworks for its automated selection. To address this, we introduce MLLM-Selector, an automated approach that identifies valuable data for VIT by weighing necessity and diversity. Our process starts by randomly sampling a subset from the VIT data pool to fine-tune a pretrained model, thus creating a seed model with an initial ability to follow instructions. Then, leveraging the seed model, we calculate necessity scores for each sample in the VIT data pool to identify samples pivotal for enhancing model performance. Our findings underscore the importance of mixing necessity and diversity in data choice, leading to the creation of MLLM-Selector, our methodology that fuses necessity scoring with strategic sampling for superior data refinement. Empirical results indicate that within identical experimental conditions, MLLM-Selector surpasses LLaVA-1.5 in some benchmarks with less than 1% of the data and consistently exceeds performance across all validated benchmarks when using less than 50%.
Cheems: A Practical Guidance for Building and Evaluating Chinese Reward Models from Scratch
Feb 24, 2025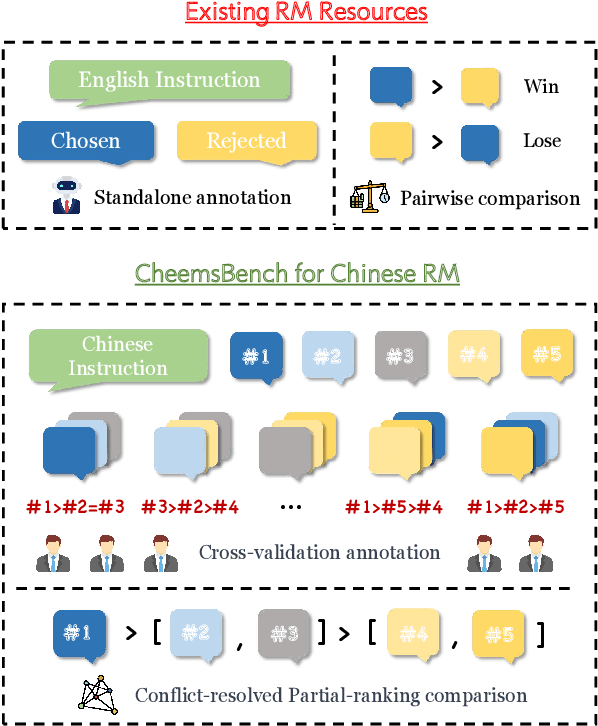
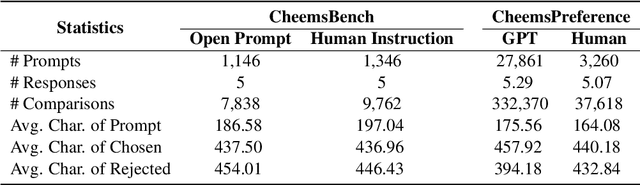
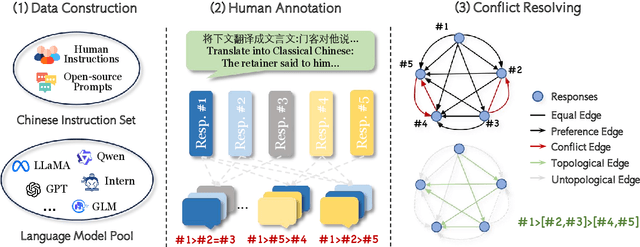
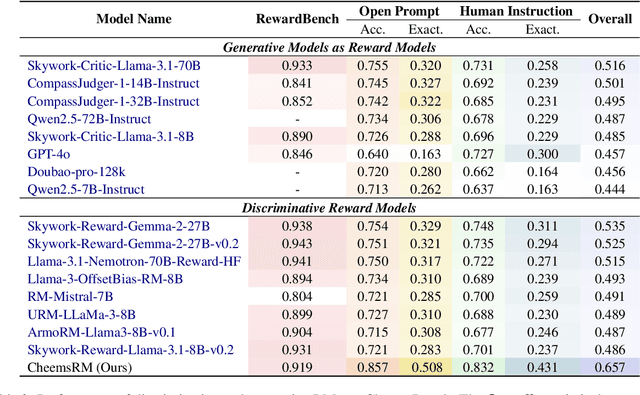
Reward models (RMs) are crucial for aligning large language models (LLMs) with human preferences. However, most RM research is centered on English and relies heavily on synthetic resources, which leads to limited and less reliable datasets and benchmarks for Chinese. To address this gap, we introduce CheemsBench, a fully human-annotated RM evaluation benchmark within Chinese contexts, and CheemsPreference, a large-scale and diverse preference dataset annotated through human-machine collaboration to support Chinese RM training. We systematically evaluate open-source discriminative and generative RMs on CheemsBench and observe significant limitations in their ability to capture human preferences in Chinese scenarios. Additionally, based on CheemsPreference, we construct an RM that achieves state-of-the-art performance on CheemsBench, demonstrating the necessity of human supervision in RM training. Our findings reveal that scaled AI-generated data struggles to fully capture human preferences, emphasizing the importance of high-quality human supervision in RM development.
An LLM-free Multi-dimensional Benchmark for MLLMs Hallucination Evaluation
Nov 13, 2023



Despite making significant progress in multi-modal tasks, current Multi-modal Large Language Models (MLLMs) encounter the significant challenge of hallucination, which may lead to harmful consequences. Therefore, evaluating MLLMs' hallucinations is becoming increasingly important in model improvement and practical application deployment. Previous works are limited in high evaluation costs (e.g., relying on humans or advanced LLMs) and insufficient evaluation dimensions (e.g., types of hallucination and task). In this paper, we propose an LLM-free multi-dimensional benchmark AMBER, which can be used to evaluate both generative task and discriminative task including object existence, object attribute and object relation hallucination. Based on AMBER, we design a low-cost and efficient evaluation pipeline. Additionally, we conduct a comprehensive evaluation and detailed analysis of mainstream MLLMs including GPT-4V(ision), and also give guideline suggestions for mitigating hallucinations. The data and code of AMBER are available at https://github.com/junyangwang0410/AMBER.
UReader: Universal OCR-free Visually-situated Language Understanding with Multimodal Large Language Model
Oct 08, 2023
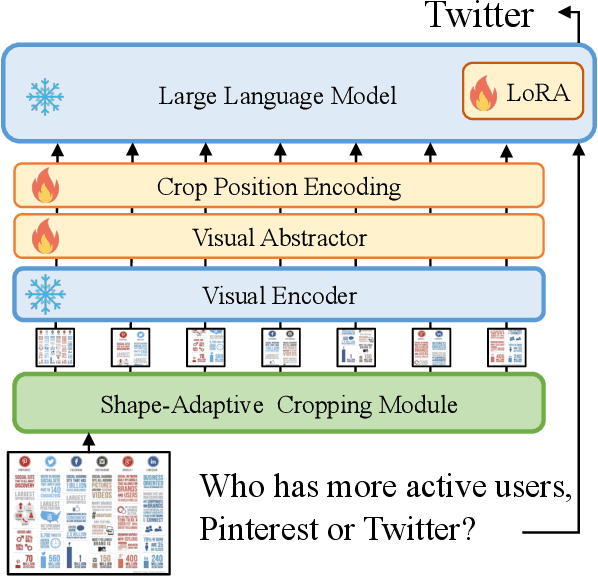


Text is ubiquitous in our visual world, conveying crucial information, such as in documents, websites, and everyday photographs. In this work, we propose UReader, a first exploration of universal OCR-free visually-situated language understanding based on the Multimodal Large Language Model (MLLM). By leveraging the shallow text recognition ability of the MLLM, we only finetuned 1.2% parameters and the training cost is much lower than previous work following domain-specific pretraining and finetuning paradigms. Concretely, UReader is jointly finetuned on a wide range of Visually-situated Language Understanding tasks via a unified instruction format. To enhance the visual text and semantic understanding, we further apply two auxiliary tasks with the same format, namely text reading and key points generation tasks. We design a shape-adaptive cropping module before the encoder-decoder architecture of MLLM to leverage the frozen low-resolution vision encoder for processing high-resolution images. Without downstream finetuning, our single model achieves state-of-the-art ocr-free performance in 8 out of 10 visually-situated language understanding tasks, across 5 domains: documents, tables, charts, natural images, and webpage screenshots. Codes and instruction-tuning datasets will be released.
Evaluation and Analysis of Hallucination in Large Vision-Language Models
Aug 29, 2023

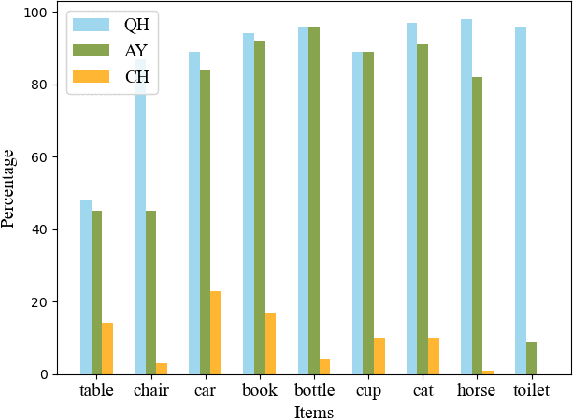
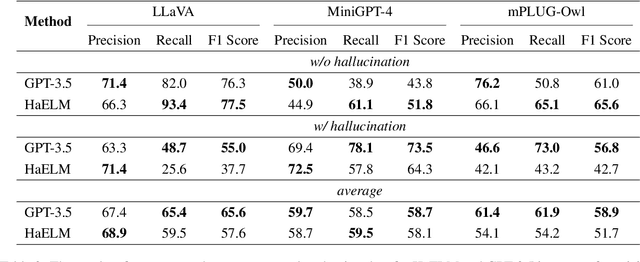
Large Vision-Language Models (LVLMs) have recently achieved remarkable success. However, LVLMs are still plagued by the hallucination problem, which limits the practicality in many scenarios. Hallucination refers to the information of LVLMs' responses that does not exist in the visual input, which poses potential risks of substantial consequences. There has been limited work studying hallucination evaluation in LVLMs. In this paper, we propose Hallucination Evaluation based on Large Language Models (HaELM), an LLM-based hallucination evaluation framework. HaELM achieves an approximate 95% performance comparable to ChatGPT and has additional advantages including low cost, reproducibility, privacy preservation and local deployment. Leveraging the HaELM, we evaluate the hallucination in current LVLMs. Furthermore, we analyze the factors contributing to hallucination in LVLMs and offer helpful suggestions to mitigate the hallucination problem. Our training data and human annotation hallucination data will be made public soon.
CValues: Measuring the Values of Chinese Large Language Models from Safety to Responsibility
Jul 19, 2023



With the rapid evolution of large language models (LLMs), there is a growing concern that they may pose risks or have negative social impacts. Therefore, evaluation of human values alignment is becoming increasingly important. Previous work mainly focuses on assessing the performance of LLMs on certain knowledge and reasoning abilities, while neglecting the alignment to human values, especially in a Chinese context. In this paper, we present CValues, the first Chinese human values evaluation benchmark to measure the alignment ability of LLMs in terms of both safety and responsibility criteria. As a result, we have manually collected adversarial safety prompts across 10 scenarios and induced responsibility prompts from 8 domains by professional experts. To provide a comprehensive values evaluation of Chinese LLMs, we not only conduct human evaluation for reliable comparison, but also construct multi-choice prompts for automatic evaluation. Our findings suggest that while most Chinese LLMs perform well in terms of safety, there is considerable room for improvement in terms of responsibility. Moreover, both the automatic and human evaluation are important for assessing the human values alignment in different aspects. The benchmark and code is available on ModelScope and Github.