 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Alignment in LVLMs with Debiased Self-Judgment
Aug 28, 2025



The rapid advancements in Large Language Models (LLMs) and Large Visual-Language Models (LVLMs) have opened up new opportunities for integrating visual and linguistic modalities. However, effectively aligning these modalities remains challenging, often leading to hallucinations--where generated outputs are not grounded in the visual input--and raising safety concerns across various domains. Existing alignment methods, such as instruction tuning and preference tuning, often rely on external datasets, human annotations, or complex post-processing, which limit scalability and increase costs. To address these challenges, we propose a novel approach that generates the debiased self-judgment score, a self-evaluation metric created internally by the model without relying on external resources. This enables the model to autonomously improve alignment. Our method enhances both decoding strategies and preference tuning processes, resulting in reduced hallucinations, enhanced safety, and improved overall capability. Empirical results show that our approach significantly outperforms traditional methods, offering a more effective solution for aligning LVLMs.
Mimicking the Physicist's Eye:A VLM-centric Approach for Physics Formula Discovery
Aug 24, 2025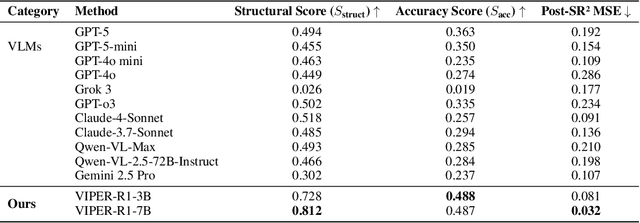
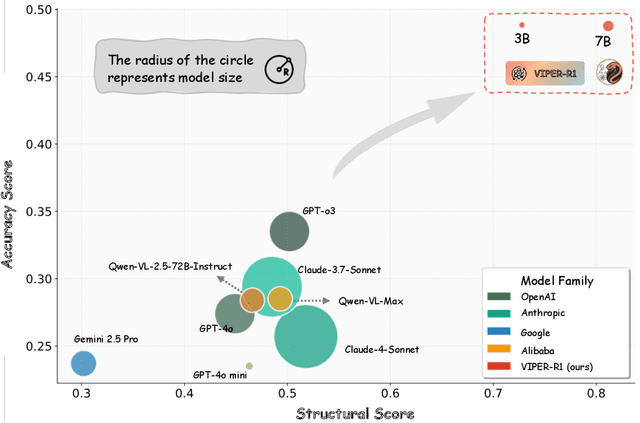
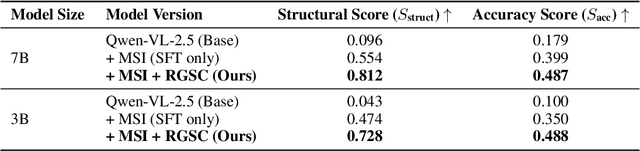
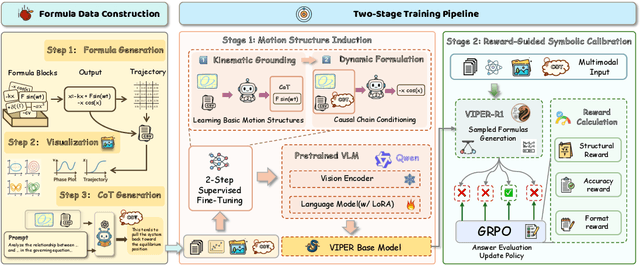
Automated discovery of physical laws from observational data in the real world is a grand challenge in AI. Current methods, relying on symbolic regression or LLMs, are limited to uni-modal data and overlook the rich, visual phenomenological representations of motion that are indispensable to physicists. This "sensory deprivation" severely weakens their ability to interpret the inherent spatio-temporal patterns within dynamic phenomena. To address this gap, we propose VIPER-R1, a multimodal model that performs Visual Induction for Physics-based Equation Reasoning to discover fundamental symbolic formulas. It integrates visual perception, trajectory data, and symbolic reasoning to emulate the scientific discovery process. The model is trained via a curriculum of Motion Structure Induction (MSI), using supervised fine-tuning to interpret kinematic phase portraits and to construct hypotheses guided by a Causal Chain of Thought (C-CoT), followed by Reward-Guided Symbolic Calibration (RGSC) to refine the formula structure with reinforcement learning. During inference, the trained VIPER-R1 acts as an agent: it first posits a high-confidence symbolic ansatz, then proactively invokes an external symbolic regression tool to perform Symbolic Residual Realignment (SR^2). This final step, analogous to a physicist's perturbation analysis, reconciles the theoretical model with empirical data. To support this research, we introduce PhysSymbol, a new 5,000-instance multimodal corpus. Experiments show that VIPER-R1 consistently outperforms state-of-the-art VLM baselines in accuracy and interpretability, enabling more precise discovery of physical laws. Project page: https://jiaaqiliu.github.io/VIPER-R1/
Anyprefer: An Agentic Framework for Preference Data Synthesis
Apr 27, 2025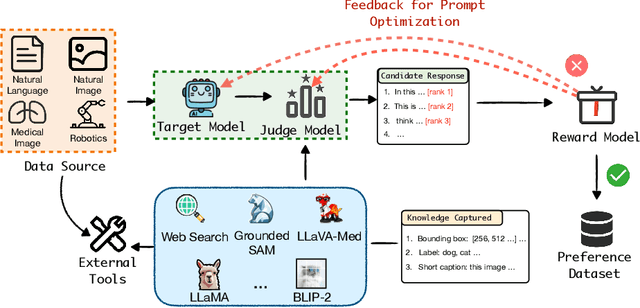
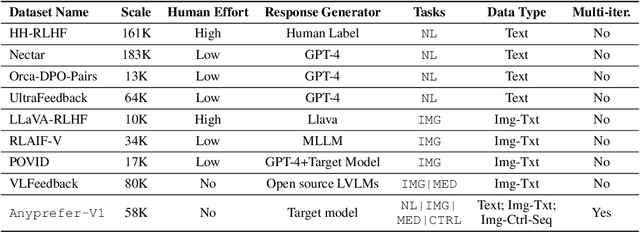
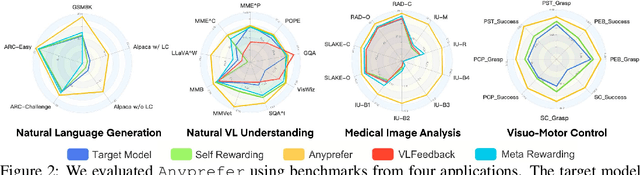
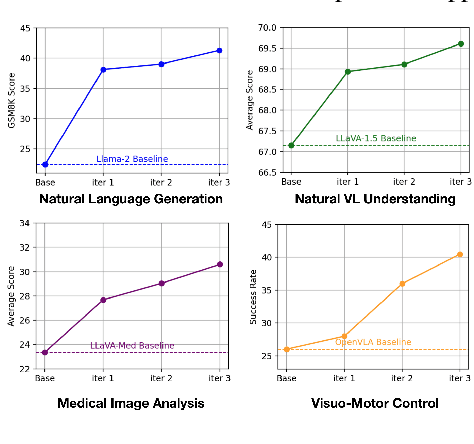
High-quality preference data is essential for aligning foundation models with human values through preference learning. However, manual annotation of such data is often time-consuming and costly. Recent methods often adopt a self-rewarding approach, where the target model generates and annotates its own preference data, but this can lead to inaccuracies since the reward model shares weights with the target model, thereby amplifying inherent biases. To address these issues, we propose Anyprefer, a framework designed to synthesize high-quality preference data for aligning the target model. Anyprefer frames the data synthesis process as a cooperative two-player Markov Game, where the target model and the judge model collaborate together. Here, a series of external tools are introduced to assist the judge model in accurately rewarding the target model's responses, mitigating biases in the rewarding process. In addition, a feedback mechanism is introduced to optimize prompts for both models, enhancing collaboration and improving data quality. The synthesized data is compiled into a new preference dataset, Anyprefer-V1, consisting of 58K high-quality preference pairs. Extensive experiments show that Anyprefer significantly improves model alignment performance across four main applications, covering 21 datasets, achieving average improvements of 18.55% in five natural language generation datasets, 3.66% in nine vision-language understanding datasets, 30.05% in three medical image analysis datasets, and 16.00% in four visuo-motor control tasks.
MJ-VIDEO: Fine-Grained Benchmarking and Rewarding Video Preferences in Video Generation
Feb 03, 2025


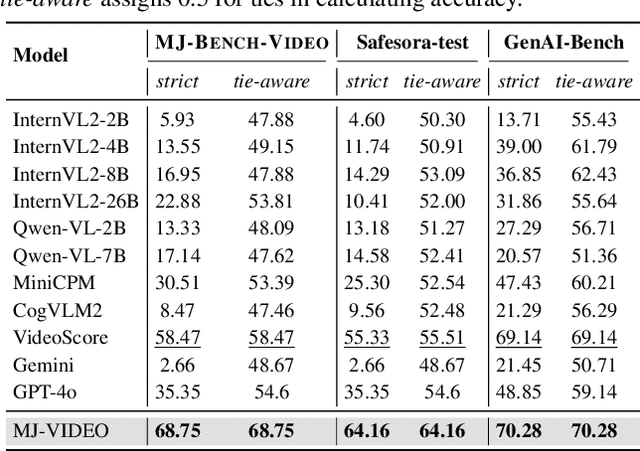
Recent advancements in video generation have significantly improved the ability to synthesize videos from text instructions. However, existing models still struggle with key challenges such as instruction misalignment, content hallucination, safety concerns, and bias. Addressing these limitations, we introduce MJ-BENCH-VIDEO, a large-scale video preference benchmark designed to evaluate video generation across five critical aspects: Alignment, Safety, Fineness, Coherence & Consistency, and Bias & Fairness. This benchmark incorporates 28 fine-grained criteria to provide a comprehensive evaluation of video preference. Building upon this dataset, we propose MJ-VIDEO, a Mixture-of-Experts (MoE)-based video reward model designed to deliver fine-grained reward. MJ-VIDEO can dynamically select relevant experts to accurately judge the preference based on the input text-video pair. This architecture enables more precise and adaptable preference judgments. Through extensive benchmarking on MJ-BENCH-VIDEO, we analyze the limitations of existing video reward models and demonstrate the superior performance of MJ-VIDEO in video preference assessment, achieving 17.58% and 15.87% improvements in overall and fine-grained preference judgments, respectively. Additionally, introducing MJ-VIDEO for preference tuning in video generation enhances the alignment performance.
Fine-Grained Verifiers: Preference Modeling as Next-token Prediction in Vision-Language Alignment
Oct 18, 2024



The recent advancements in large language models (LLMs) and pre-trained vision models have accelerated the development of vision-language large models (VLLMs), enhancing the interaction between visual and linguistic modalities. Despite their notable success across various domains, VLLMs face challenges in modality alignment, which can lead to issues like hallucinations and unsafe content generation. Current alignment techniques often rely on coarse feedback and external datasets, limiting scalability and performance. In this paper, we propose FiSAO (Fine-Grained Self-Alignment Optimization), a novel self-alignment method that utilizes the model's own visual encoder as a fine-grained verifier to improve vision-language alignment without the need for additional data. By leveraging token-level feedback from the vision encoder, FiSAO significantly improves vision-language alignment, even surpassing traditional preference tuning methods that require additional data. Through both theoretical analysis and experimental validation, we demonstrate that FiSAO effectively addresses the misalignment problem in VLLMs, marking the first instance of token-level rewards being applied to such models.
MMIE: Massive Multimodal Interleaved Comprehension Benchmark for Large Vision-Language Models
Oct 14, 2024



Interleaved multimodal comprehension and generation, enabling models to produce and interpret both images and text in arbitrary sequences, have become a pivotal area in multimodal learning. Despite significant advancements, the evaluation of this capability remains insufficient. Existing benchmarks suffer from limitations in data scale, scope, and evaluation depth, while current evaluation metrics are often costly or biased, lacking in reliability for practical applications. To address these challenges, we introduce MMIE, a large-scale knowledge-intensive benchmark for evaluating interleaved multimodal comprehension and generation in Large Vision-Language Models (LVLMs). MMIE comprises 20K meticulously curated multimodal queries, spanning 3 categories, 12 fields, and 102 subfields, including mathematics, coding, physics, literature, health, and arts. It supports both interleaved inputs and outputs, offering a mix of multiple-choice and open-ended question formats to evaluate diverse competencies. Moreover, we propose a reliable automated evaluation metric, leveraging a scoring model fine-tuned with human-annotated data and systematic evaluation criteria, aimed at reducing bias and improving evaluation accuracy. Extensive experiments demonstrate the effectiveness of our benchmark and metrics in providing a comprehensive evaluation of interleaved LVLMs. Specifically, we evaluate eight LVLMs, revealing that even the best models show significant room for improvement, with most achieving only moderate results. We believe MMIE will drive further advancements in the development of interleaved LVLMs. We publicly release our benchmark and code in https://mmie-bench.github.io/.
VHELM: A Holistic Evaluation of Vision Language Models
Oct 09, 2024



Current benchmarks for assessing vision-language models (VLMs) often focus on their perception or problem-solving capabilities and neglect other critical aspects such as fairness, multilinguality, or toxicity. Furthermore, they differ in their evaluation procedures and the scope of the evaluation, making it difficult to compare models. To address these issues, we extend the HELM framework to VLMs to present the Holistic Evaluation of Vision Language Models (VHELM). VHELM aggregates various datasets to cover one or more of the 9 aspects: visual perception, knowledge, reasoning, bias, fairness, multilinguality, robustness, toxicity, and safety. In doing so, we produce a comprehensive, multi-dimensional view of the capabilities of the VLMs across these important factors. In addition, we standardize the standard inference parameters, methods of prompting, and evaluation metrics to enable fair comparisons across models. Our framework is designed to be lightweight and automatic so that evaluation runs are cheap and fast. Our initial run evaluates 22 VLMs on 21 existing datasets to provide a holistic snapshot of the models. We uncover new key findings, such as the fact that efficiency-focused models (e.g., Claude 3 Haiku or Gemini 1.5 Flash) perform significantly worse than their full models (e.g., Claude 3 Opus or Gemini 1.5 Pro) on the bias benchmark but not when evaluated on the other aspects. For transparency, we release the raw model generations and complete results on our website (https://crfm.stanford.edu/helm/vhelm/v2.0.1). VHELM is intended to be a living benchmark, and we hope to continue adding new datasets and models over time.
MJ-Bench: Is Your Multimodal Reward Model Really a Good Judge for Text-to-Image Generation?
Jul 05, 2024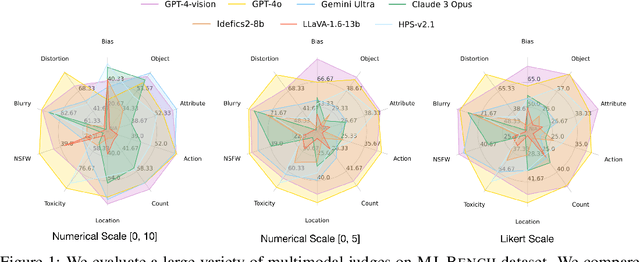
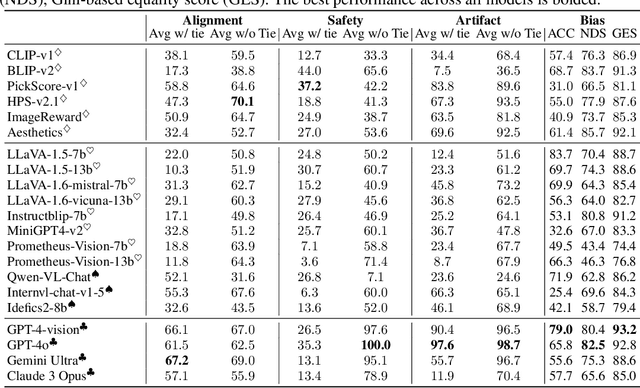

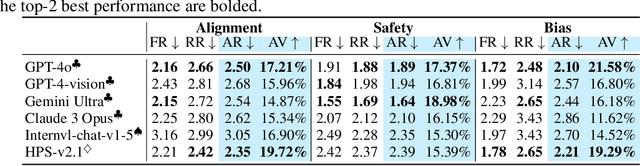
While text-to-image models like DALLE-3 and Stable Diffusion are rapidly proliferating, they often encounter challenges such as hallucination, bias, and the production of unsafe, low-quality output. To effectively address these issues, it is crucial to align these models with desired behaviors based on feedback from a multimodal judge. Despite their significance, current multimodal judges frequently undergo inadequate evaluation of their capabilities and limitations, potentially leading to misalignment and unsafe fine-tuning outcomes. To address this issue, we introduce MJ-Bench, a novel benchmark which incorporates a comprehensive preference dataset to evaluate multimodal judges in providing feedback for image generation models across four key perspectives: alignment, safety, image quality, and bias. Specifically, we evaluate a large variety of multimodal judges including smaller-sized CLIP-based scoring models, open-source VLMs (e.g. LLaVA family), and close-source VLMs (e.g. GPT-4o, Claude 3) on each decomposed subcategory of our preference dataset. Experiments reveal that close-source VLMs generally provide better feedback, with GPT-4o outperforming other judges in average. Compared with open-source VLMs, smaller-sized scoring models can provide better feedback regarding text-image alignment and image quality, while VLMs provide more accurate feedback regarding safety and generation bias due to their stronger reasoning capabilities. Further studies in feedback scale reveal that VLM judges can generally provide more accurate and stable feedback in natural language (Likert-scale) than numerical scales. Notably, human evaluations on end-to-end fine-tuned models using separate feedback from these multimodal judges provide similar conclusions, further confirming the effectiveness of MJ-Bench. All data, code, models are available at https://huggingface.co/MJ-Bench.
CARES: A Comprehensive Benchmark of Trustworthiness in Medical Vision Language Models
Jun 10, 2024
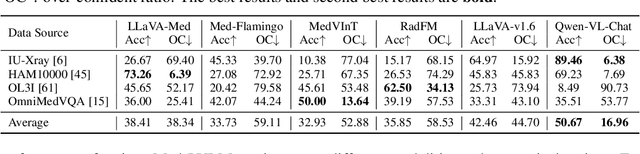
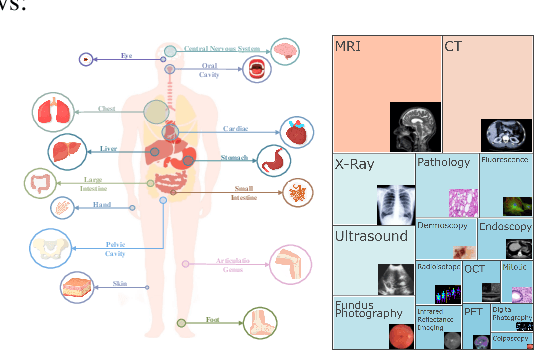
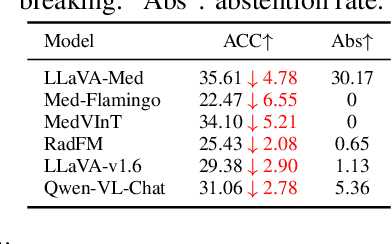
Artificial intelligence has significantly impacted medical applications, particularly with the advent of Medical Large Vision Language Models (Med-LVLMs), sparking optimism for the future of automated and personalized healthcare. However, the trustworthiness of Med-LVLMs remains unverified, posing significant risks for future model deployment. In this paper, we introduce CARES and aim to comprehensively evaluate the Trustworthiness of Med-LVLMs across the medical domain. We assess the trustworthiness of Med-LVLMs across five dimensions, including trustfulness, fairness, safety, privacy, and robustness. CARES comprises about 41K question-answer pairs in both closed and open-ended formats, covering 16 medical image modalities and 27 anatomical regions. Our analysis reveals that the models consistently exhibit concerns regarding trustworthiness, often displaying factual inaccuracies and failing to maintain fairness across different demographic groups. Furthermore, they are vulnerable to attacks and demonstrate a lack of privacy awareness. We publicly release our benchmark and code in https://github.com/richard-peng-xia/CARES.
Enhancing Visual-Language Modality Alignment in Large Vision Language Models via Self-Improvement
May 29, 2024



Large vision-language models (LVLMs) have achieved impressive results in various visual question-answering and reasoning tasks through vision instruction tuning on specific datasets. However, there is still significant room for improvement in the alignment between visual and language modalities. Previous methods to enhance this alignment typically require external models or data, heavily depending on their capabilities and quality, which inevitably sets an upper bound on performance. In this paper, we propose SIMA, a framework that enhances visual and language modality alignment through self-improvement, eliminating the needs for external models or data. SIMA leverages prompts from existing vision instruction tuning datasets to self-generate responses and employs an in-context self-critic mechanism to select response pairs for preference tuning. The key innovation is the introduction of three vision metrics during the in-context self-critic process, which can guide the LVLM in selecting responses that enhance image comprehension. Through experiments across 14 hallucination and comprehensive benchmarks, we demonstrate that SIMA not only improves model performance across all benchmarks but also achieves superior modality alignment, outperforming previous approaches.