 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWorld Action Models are Zero-shot Policies
Feb 17, 2026State-of-the-art Vision-Language-Action (VLA) models excel at semantic generalization but struggle to generalize to unseen physical motions in novel environments. We introduce DreamZero, a World Action Model (WAM) built upon a pretrained video diffusion backbone. Unlike VLAs, WAMs learn physical dynamics by predicting future world states and actions, using video as a dense representation of how the world evolves. By jointly modeling video and action, DreamZero learns diverse skills effectively from heterogeneous robot data without relying on repetitive demonstrations. This results in over 2x improvement in generalization to new tasks and environments compared to state-of-the-art VLAs in real robot experiments. Crucially, through model and system optimizations, we enable a 14B autoregressive video diffusion model to perform real-time closed-loop control at 7Hz. Finally, we demonstrate two forms of cross-embodiment transfer: video-only demonstrations from other robots or humans yield a relative improvement of over 42% on unseen task performance with just 10-20 minutes of data. More surprisingly, DreamZero enables few-shot embodiment adaptation, transferring to a new embodiment with only 30 minutes of play data while retaining zero-shot generalization.
Beyond Next-Token Alignment: Distilling Multimodal Large Language Models via Token Interactions
Feb 10, 2026Multimodal Large Language Models (MLLMs) demonstrate impressive cross-modal capabilities, yet their substantial size poses significant deployment challenges. Knowledge distillation (KD) is a promising solution for compressing these models, but existing methods primarily rely on static next-token alignment, neglecting the dynamic token interactions, which embed essential capabilities for multimodal understanding and generation. To this end, we introduce Align-TI, a novel KD framework designed from the perspective of Token Interactions. Our approach is motivated by the insight that MLLMs rely on two primary interactions: vision-instruction token interactions to extract relevant visual information, and intra-response token interactions for coherent generation. Accordingly, Align-TI introduces two components: IVA enables the student model to imitate the teacher's instruction-relevant visual information extract capability by aligning on salient visual regions. TPA captures the teacher's dynamic generative logic by aligning the sequential token-to-token transition probabilities. Extensive experiments demonstrate Align-TI's superiority. Notably, our approach achieves $2.6\%$ relative improvement over Vanilla KD, and our distilled Align-TI-2B even outperforms LLaVA-1.5-7B (a much larger MLLM) by $7.0\%$, establishing a new state-of-the-art distillation framework for training parameter-efficient MLLMs. Code is available at https://github.com/lchen1019/Align-TI.
DreamDojo: A Generalist Robot World Model from Large-Scale Human Videos
Feb 06, 2026Being able to simulate the outcomes of actions in varied environments will revolutionize the development of generalist agents at scale. However, modeling these world dynamics, especially for dexterous robotics tasks, poses significant challenges due to limited data coverage and scarce action labels. As an endeavor towards this end, we introduce DreamDojo, a foundation world model that learns diverse interactions and dexterous controls from 44k hours of egocentric human videos. Our data mixture represents the largest video dataset to date for world model pretraining, spanning a wide range of daily scenarios with diverse objects and skills. To address the scarcity of action labels, we introduce continuous latent actions as unified proxy actions, enhancing interaction knowledge transfer from unlabeled videos. After post-training on small-scale target robot data, DreamDojo demonstrates a strong understanding of physics and precise action controllability. We also devise a distillation pipeline that accelerates DreamDojo to a real-time speed of 10.81 FPS and further improves context consistency. Our work enables several important applications based on generative world models, including live teleoperation, policy evaluation, and model-based planning. Systematic evaluation on multiple challenging out-of-distribution (OOD) benchmarks verifies the significance of our method for simulating open-world, contact-rich tasks, paving the way for general-purpose robot world models.
DreamGen: Unlocking Generalization in Robot Learning through Neural Trajectories
May 19, 2025We introduce DreamGen, a simple yet highly effective 4-stage pipeline for training robot policies that generalize across behaviors and environments through neural trajectories - synthetic robot data generated from video world models. DreamGen leverages state-of-the-art image-to-video generative models, adapting them to the target robot embodiment to produce photorealistic synthetic videos of familiar or novel tasks in diverse environments. Since these models generate only videos, we recover pseudo-action sequences using either a latent action model or an inverse-dynamics model (IDM). Despite its simplicity, DreamGen unlocks strong behavior and environment generalization: a humanoid robot can perform 22 new behaviors in both seen and unseen environments, while requiring teleoperation data from only a single pick-and-place task in one environment. To evaluate the pipeline systematically, we introduce DreamGen Bench, a video generation benchmark that shows a strong correlation between benchmark performance and downstream policy success. Our work establishes a promising new axis for scaling robot learning well beyond manual data collection.
Anyprefer: An Agentic Framework for Preference Data Synthesis
Apr 27, 2025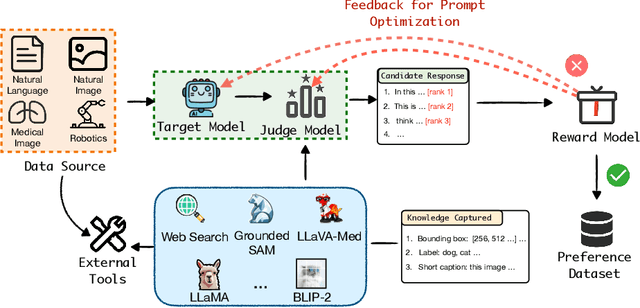
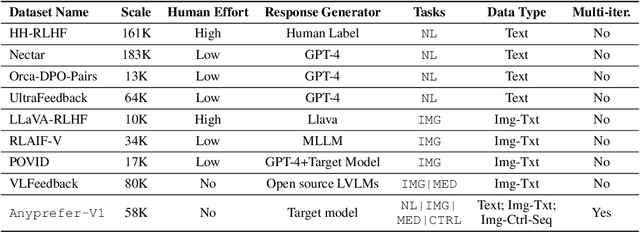
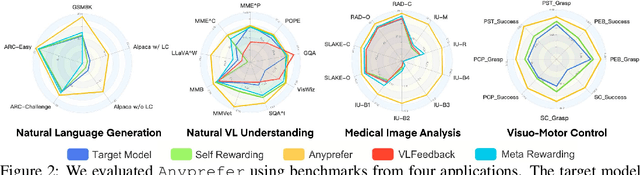
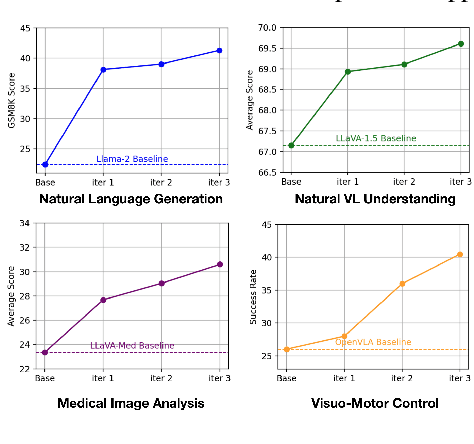
High-quality preference data is essential for aligning foundation models with human values through preference learning. However, manual annotation of such data is often time-consuming and costly. Recent methods often adopt a self-rewarding approach, where the target model generates and annotates its own preference data, but this can lead to inaccuracies since the reward model shares weights with the target model, thereby amplifying inherent biases. To address these issues, we propose Anyprefer, a framework designed to synthesize high-quality preference data for aligning the target model. Anyprefer frames the data synthesis process as a cooperative two-player Markov Game, where the target model and the judge model collaborate together. Here, a series of external tools are introduced to assist the judge model in accurately rewarding the target model's responses, mitigating biases in the rewarding process. In addition, a feedback mechanism is introduced to optimize prompts for both models, enhancing collaboration and improving data quality. The synthesized data is compiled into a new preference dataset, Anyprefer-V1, consisting of 58K high-quality preference pairs. Extensive experiments show that Anyprefer significantly improves model alignment performance across four main applications, covering 21 datasets, achieving average improvements of 18.55% in five natural language generation datasets, 3.66% in nine vision-language understanding datasets, 30.05% in three medical image analysis datasets, and 16.00% in four visuo-motor control tasks.
ReBot: Scaling Robot Learning with Real-to-Sim-to-Real Robotic Video Synthesis
Mar 15, 2025Vision-language-action (VLA) models present a promising paradigm by training policies directly on real robot datasets like Open X-Embodiment. However, the high cost of real-world data collection hinders further data scaling, thereby restricting the generalizability of VLAs. In this paper, we introduce ReBot, a novel real-to-sim-to-real approach for scaling real robot datasets and adapting VLA models to target domains, which is the last-mile deployment challenge in robot manipulation. Specifically, ReBot replays real-world robot trajectories in simulation to diversify manipulated objects (real-to-sim), and integrates the simulated movements with inpainted real-world background to synthesize physically realistic and temporally consistent robot videos (sim-to-real). Our approach has several advantages: 1) it enjoys the benefit of real data to minimize the sim-to-real gap; 2) it leverages the scalability of simulation; and 3) it can generalize a pretrained VLA to a target domain with fully automated data pipelines. Extensive experiments in both simulation and real-world environments show that ReBot significantly enhances the performance and robustness of VLAs. For example, in SimplerEnv with the WidowX robot, ReBot improved the in-domain performance of Octo by 7.2% and OpenVLA by 21.8%, and out-of-domain generalization by 19.9% and 9.4%, respectively. For real-world evaluation with a Franka robot, ReBot increased the success rates of Octo by 17% and OpenVLA by 20%. More information can be found at: https://yuffish.github.io/rebot/
Reassessing the Role of Chain-of-Thought in Sentiment Analysis: Insights and Limitations
Jan 15, 2025



The relationship between language and thought remains an unresolved philosophical issue. Existing viewpoints can be broadly categorized into two schools: one asserting their independence, and another arguing that language constrains thought. In the context of large language models, this debate raises a crucial question: Does a language model's grasp of semantic meaning depend on thought processes? To explore this issue, we investigate whether reasoning techniques can facilitate semantic understanding. Specifically, we conceptualize thought as reasoning, employ chain-of-thought prompting as a reasoning technique, and examine its impact on sentiment analysis tasks. The experiments show that chain-of-thought has a minimal impact on sentiment analysis tasks. Both the standard and chain-of-thought prompts focus on aspect terms rather than sentiment in the generated content. Furthermore, counterfactual experiments reveal that the model's handling of sentiment tasks primarily depends on information from demonstrations. The experimental results support the first viewpoint.
GRAPE: Generalizing Robot Policy via Preference Alignment
Nov 28, 2024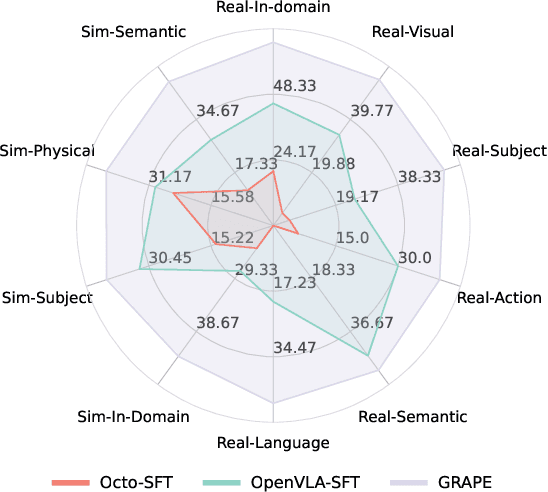

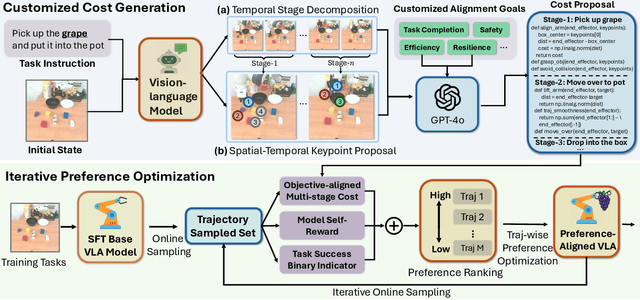
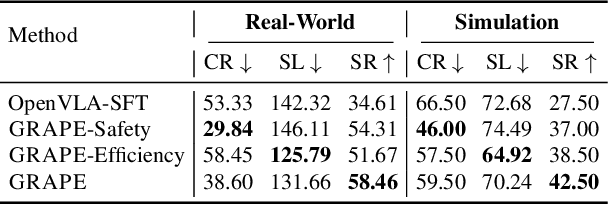
Despite the recent advancements of vision-language-action (VLA) models on a variety of robotics tasks, they suffer from critical issues such as poor generalizability to unseen tasks, due to their reliance on behavior cloning exclusively from successful rollouts. Furthermore, they are typically fine-tuned to replicate demonstrations collected by experts under different settings, thus introducing distribution bias and limiting their adaptability to diverse manipulation objectives, such as efficiency, safety, and task completion. To bridge this gap, we introduce GRAPE: Generalizing Robot Policy via Preference Alignment. Specifically, GRAPE aligns VLAs on a trajectory level and implicitly models reward from both successful and failure trials to boost generalizability to diverse tasks. Moreover, GRAPE breaks down complex manipulation tasks to independent stages and automatically guides preference modeling through customized spatiotemporal constraints with keypoints proposed by a large vision-language model. Notably, these constraints are flexible and can be customized to align the model with varying objectives, such as safety, efficiency, or task success. We evaluate GRAPE across a diverse array of tasks in both real-world and simulated environments. Experimental results demonstrate that GRAPE enhances the performance of state-of-the-art VLA models, increasing success rates on in-domain and unseen manipulation tasks by 51.79% and 60.36%, respectively. Additionally, GRAPE can be aligned with various objectives, such as safety and efficiency, reducing collision rates by 44.31% and rollout step-length by 11.15%, respectively. All code, models, and data are available at https://grape-vla.github.io/