 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDesign of a Robot-Assisted Chemical Dialysis System
Mar 10, 2026Scientists perform diverse manual procedures that are tedious and laborious. Such procedures are considered a bottleneck for modern experimental science, as they consume time and increase burdens in fields including material science and medicine. We employ a user-centered approach to designing a robot-assisted system for dialysis, a common multi-day purification method used in polymer and protein synthesis. Through two usability studies, we obtain participant feedback and revise design requirements to develop the final system that satisfies scientists' needs and has the potential for applications in other experimental workflows. We anticipate that integration of this system into real synthesis procedures in a chemical wet lab will decrease workload on scientists during long experimental procedures and provide an effective approach to designing more systems that have the potential to accelerate scientific discovery and liberate scientists from tedious labor.
LiLo-VLA: Compositional Long-Horizon Manipulation via Linked Object-Centric Policies
Feb 25, 2026General-purpose robots must master long-horizon manipulation, defined as tasks involving multiple kinematic structure changes (e.g., attaching or detaching objects) in unstructured environments. While Vision-Language-Action (VLA) models offer the potential to master diverse atomic skills, they struggle with the combinatorial complexity of sequencing them and are prone to cascading failures due to environmental sensitivity. To address these challenges, we propose LiLo-VLA (Linked Local VLA), a modular framework capable of zero-shot generalization to novel long-horizon tasks without ever being trained on them. Our approach decouples transport from interaction: a Reaching Module handles global motion, while an Interaction Module employs an object-centric VLA to process isolated objects of interest, ensuring robustness against irrelevant visual features and invariance to spatial configurations. Crucially, this modularity facilitates robust failure recovery through dynamic replanning and skill reuse, effectively mitigating the cascading errors common in end-to-end approaches. We introduce a 21-task simulation benchmark consisting of two challenging suites: LIBERO-Long++ and Ultra-Long. In these simulations, LiLo-VLA achieves a 69% average success rate, outperforming Pi0.5 by 41% and OpenVLA-OFT by 67%. Furthermore, real-world evaluations across 8 long-horizon tasks demonstrate an average success rate of 85%. Project page: https://yy-gx.github.io/LiLo-VLA/.
When Vision Overrides Language: Evaluating and Mitigating Counterfactual Failures in VLAs
Feb 19, 2026Vision-Language-Action models (VLAs) promise to ground language instructions in robot control, yet in practice often fail to faithfully follow language. When presented with instructions that lack strong scene-specific supervision, VLAs suffer from counterfactual failures: they act based on vision shortcuts induced by dataset biases, repeatedly executing well-learned behaviors and selecting objects frequently seen during training regardless of language intent. To systematically study it, we introduce LIBERO-CF, the first counterfactual benchmark for VLAs that evaluates language following capability by assigning alternative instructions under visually plausible LIBERO layouts. Our evaluation reveals that counterfactual failures are prevalent yet underexplored across state-of-the-art VLAs. We propose Counterfactual Action Guidance (CAG), a simple yet effective dual-branch inference scheme that explicitly regularizes language conditioning in VLAs. CAG combines a standard VLA policy with a language-unconditioned Vision-Action (VA) module, enabling counterfactual comparison during action selection. This design reduces reliance on visual shortcuts, improves robustness on under-observed tasks, and requires neither additional demonstrations nor modifications to existing architectures or pretrained models. Extensive experiments demonstrate its plug-and-play integration across diverse VLAs and consistent improvements. For example, on LIBERO-CF, CAG improves $π_{0.5}$ by 9.7% in language following accuracy and 3.6% in task success on under-observed tasks using a training-free strategy, with further gains of 15.5% and 8.5%, respectively, when paired with a VA model. In real-world evaluations, CAG reduces counterfactual failures of 9.4% and improves task success by 17.2% on average.
Robotic VLA Benefits from Joint Learning with Motion Image Diffusion
Dec 19, 2025Vision-Language-Action (VLA) models have achieved remarkable progress in robotic manipulation by mapping multimodal observations and instructions directly to actions. However, they typically mimic expert trajectories without predictive motion reasoning, which limits their ability to reason about what actions to take. To address this limitation, we propose joint learning with motion image diffusion, a novel strategy that enhances VLA models with motion reasoning capabilities. Our method extends the VLA architecture with a dual-head design: while the action head predicts action chunks as in vanilla VLAs, an additional motion head, implemented as a Diffusion Transformer (DiT), predicts optical-flow-based motion images that capture future dynamics. The two heads are trained jointly, enabling the shared VLM backbone to learn representations that couple robot control with motion knowledge. This joint learning builds temporally coherent and physically grounded representations without modifying the inference pathway of standard VLAs, thereby maintaining test-time latency. Experiments in both simulation and real-world environments demonstrate that joint learning with motion image diffusion improves the success rate of pi-series VLAs to 97.5% on the LIBERO benchmark and 58.0% on the RoboTwin benchmark, yielding a 23% improvement in real-world performance and validating its effectiveness in enhancing the motion reasoning capability of large-scale VLAs.
Practice Makes Perfect: A Study of Digital Twin Technology for Assembly and Problem-solving using Lunar Surface Telerobotics
May 19, 2025Robotic systems that can traverse planetary or lunar surfaces to collect environmental data and perform physical manipulation tasks, such as assembling equipment or conducting mining operations, are envisioned to form the backbone of future human activities in space. However, the environmental conditions in which these robots, or "rovers," operate present challenges toward achieving fully autonomous solutions, meaning that rover missions will require some degree of human teleoperation or supervision for the foreseeable future. As a result, human operators require training to successfully direct rovers and avoid costly errors or mission failures, as well as the ability to recover from any issues that arise on the fly during mission activities. While analog environments, such as JPL's Mars Yard, can help with such training by simulating surface environments in the real world, access to such resources may be rare and expensive. As an alternative or supplement to such physical analogs, we explore the design and evaluation of a virtual reality digital twin system to train human teleoperation of robotic rovers with mechanical arms for space mission activities. We conducted an experiment with 24 human operators to investigate how our digital twin system can support human teleoperation of rovers in both pre-mission training and in real-time problem solving in a mock lunar mission in which users directed a physical rover in the context of deploying dipole radio antennas. We found that operators who first trained with the digital twin showed a 28% decrease in mission completion time, an 85% decrease in unrecoverable errors, as well as improved mental markers, including decreased cognitive load and increased situation awareness.
ReBot: Scaling Robot Learning with Real-to-Sim-to-Real Robotic Video Synthesis
Mar 15, 2025Vision-language-action (VLA) models present a promising paradigm by training policies directly on real robot datasets like Open X-Embodiment. However, the high cost of real-world data collection hinders further data scaling, thereby restricting the generalizability of VLAs. In this paper, we introduce ReBot, a novel real-to-sim-to-real approach for scaling real robot datasets and adapting VLA models to target domains, which is the last-mile deployment challenge in robot manipulation. Specifically, ReBot replays real-world robot trajectories in simulation to diversify manipulated objects (real-to-sim), and integrates the simulated movements with inpainted real-world background to synthesize physically realistic and temporally consistent robot videos (sim-to-real). Our approach has several advantages: 1) it enjoys the benefit of real data to minimize the sim-to-real gap; 2) it leverages the scalability of simulation; and 3) it can generalize a pretrained VLA to a target domain with fully automated data pipelines. Extensive experiments in both simulation and real-world environments show that ReBot significantly enhances the performance and robustness of VLAs. For example, in SimplerEnv with the WidowX robot, ReBot improved the in-domain performance of Octo by 7.2% and OpenVLA by 21.8%, and out-of-domain generalization by 19.9% and 9.4%, respectively. For real-world evaluation with a Franka robot, ReBot increased the success rates of Octo by 17% and OpenVLA by 20%. More information can be found at: https://yuffish.github.io/rebot/
BOSS: Benchmark for Observation Space Shift in Long-Horizon Task
Feb 21, 2025Robotics has long sought to develop visual-servoing robots capable of completing previously unseen long-horizon tasks. Hierarchical approaches offer a pathway for achieving this goal by executing skill combinations arranged by a task planner, with each visuomotor skill pre-trained using a specific imitation learning (IL) algorithm. However, even in simple long-horizon tasks like skill chaining, hierarchical approaches often struggle due to a problem we identify as Observation Space Shift (OSS), where the sequential execution of preceding skills causes shifts in the observation space, disrupting the performance of subsequent individually trained skill policies. To validate OSS and evaluate its impact on long-horizon tasks, we introduce BOSS (a Benchmark for Observation Space Shift). BOSS comprises three distinct challenges: "Single Predicate Shift", "Accumulated Predicate Shift", and "Skill Chaining", each designed to assess a different aspect of OSS's negative effect. We evaluated several recent popular IL algorithms on BOSS, including three Behavioral Cloning methods and the Visual Language Action model OpenVLA. Even on the simplest challenge, we observed average performance drops of 67%, 35%, 34%, and 54%, respectively, when comparing skill performance with and without OSS. Additionally, we investigate a potential solution to OSS that scales up the training data for each skill with a larger and more visually diverse set of demonstrations, with our results showing it is not sufficient to resolve OSS. The project page is: https://boss-benchmark.github.io/
ARCADE: Scalable Demonstration Collection and Generation via Augmented Reality for Imitation Learning
Oct 21, 2024



Robot Imitation Learning (IL) is a crucial technique in robot learning, where agents learn by mimicking human demonstrations. However, IL encounters scalability challenges stemming from both non-user-friendly demonstration collection methods and the extensive time required to amass a sufficient number of demonstrations for effective training. In response, we introduce the Augmented Reality for Collection and generAtion of DEmonstrations (ARCADE) framework, designed to scale up demonstration collection for robot manipulation tasks. Our framework combines two key capabilities: 1) it leverages AR to make demonstration collection as simple as users performing daily tasks using their hands, and 2) it enables the automatic generation of additional synthetic demonstrations from a single human-derived demonstration, significantly reducing user effort and time. We assess ARCADE's performance on a real Fetch robot across three robotics tasks: 3-Waypoints-Reach, Push, and Pick-And-Place. Using our framework, we were able to rapidly train a policy using vanilla Behavioral Cloning (BC), a classic IL algorithm, which excelled across these three tasks. We also deploy ARCADE on a real household task, Pouring-Water, achieving an 80% success rate.
Augmented Reality Demonstrations for Scalable Robot Imitation Learning
Mar 20, 2024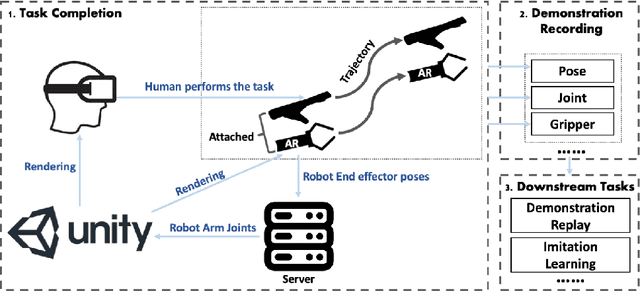

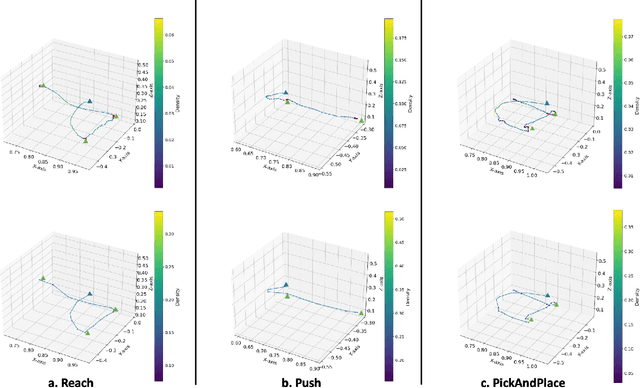

Robot Imitation Learning (IL) is a widely used method for training robots to perform manipulation tasks that involve mimicking human demonstrations to acquire skills. However, its practicality has been limited due to its requirement that users be trained in operating real robot arms to provide demonstrations. This paper presents an innovative solution: an Augmented Reality (AR)-assisted framework for demonstration collection, empowering non-roboticist users to produce demonstrations for robot IL using devices like the HoloLens 2. Our framework facilitates scalable and diverse demonstration collection for real-world tasks. We validate our approach with experiments on three classical robotics tasks: reach, push, and pick-and-place. The real robot performs each task successfully while replaying demonstrations collected via AR.
Paper index: Designing an introductory HRI course (workshop at HRI 2024)
Mar 04, 2024Human-robot interaction is now an established discipline. Dozens of HRI courses exist at universities worldwide, and some institutions even offer degrees in HRI. However, although many students are being taught HRI, there is no agreed-upon curriculum for an introductory HRI course. In this workshop, we aimed to reach community consensus on what should be covered in such a course. Through interactive activities like panels, breakout discussions, and syllabus design, workshop participants explored the many topics and pedagogical approaches for teaching HRI. This collection of articles submitted to the workshop provides examples of HRI courses being offered worldwide.