 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeeing is Believing: Belief-Space Planning with Foundation Models as Uncertainty Estimators
Apr 04, 2025Generalizable robotic mobile manipulation in open-world environments poses significant challenges due to long horizons, complex goals, and partial observability. A promising approach to address these challenges involves planning with a library of parameterized skills, where a task planner sequences these skills to achieve goals specified in structured languages, such as logical expressions over symbolic facts. While vision-language models (VLMs) can be used to ground these expressions, they often assume full observability, leading to suboptimal behavior when the agent lacks sufficient information to evaluate facts with certainty. This paper introduces a novel framework that leverages VLMs as a perception module to estimate uncertainty and facilitate symbolic grounding. Our approach constructs a symbolic belief representation and uses a belief-space planner to generate uncertainty-aware plans that incorporate strategic information gathering. This enables the agent to effectively reason about partial observability and property uncertainty. We demonstrate our system on a range of challenging real-world tasks that require reasoning in partially observable environments. Simulated evaluations show that our approach outperforms both vanilla VLM-based end-to-end planning or VLM-based state estimation baselines by planning for and executing strategic information gathering. This work highlights the potential of VLMs to construct belief-space symbolic scene representations, enabling downstream tasks such as uncertainty-aware planning.
BOSS: Benchmark for Observation Space Shift in Long-Horizon Task
Feb 21, 2025Robotics has long sought to develop visual-servoing robots capable of completing previously unseen long-horizon tasks. Hierarchical approaches offer a pathway for achieving this goal by executing skill combinations arranged by a task planner, with each visuomotor skill pre-trained using a specific imitation learning (IL) algorithm. However, even in simple long-horizon tasks like skill chaining, hierarchical approaches often struggle due to a problem we identify as Observation Space Shift (OSS), where the sequential execution of preceding skills causes shifts in the observation space, disrupting the performance of subsequent individually trained skill policies. To validate OSS and evaluate its impact on long-horizon tasks, we introduce BOSS (a Benchmark for Observation Space Shift). BOSS comprises three distinct challenges: "Single Predicate Shift", "Accumulated Predicate Shift", and "Skill Chaining", each designed to assess a different aspect of OSS's negative effect. We evaluated several recent popular IL algorithms on BOSS, including three Behavioral Cloning methods and the Visual Language Action model OpenVLA. Even on the simplest challenge, we observed average performance drops of 67%, 35%, 34%, and 54%, respectively, when comparing skill performance with and without OSS. Additionally, we investigate a potential solution to OSS that scales up the training data for each skill with a larger and more visually diverse set of demonstrations, with our results showing it is not sufficient to resolve OSS. The project page is: https://boss-benchmark.github.io/
Hierarchical Equivariant Policy via Frame Transf
Feb 09, 2025Recent advances in hierarchical policy learning highlight the advantages of decomposing systems into high-level and low-level agents, enabling efficient long-horizon reasoning and precise fine-grained control. However, the interface between these hierarchy levels remains underexplored, and existing hierarchical methods often ignore domain symmetry, resulting in the need for extensive demonstrations to achieve robust performance. To address these issues, we propose Hierarchical Equivariant Policy (HEP), a novel hierarchical policy framework. We propose a frame transfer interface for hierarchical policy learning, which uses the high-level agent's output as a coordinate frame for the low-level agent, providing a strong inductive bias while retaining flexibility. Additionally, we integrate domain symmetries into both levels and theoretically demonstrate the system's overall equivariance. HEP achieves state-of-the-art performance in complex robotic manipulation tasks, demonstrating significant improvements in both simulation and real-world settings.
Equivariant Action Sampling for Reinforcement Learning and Planning
Dec 16, 2024Reinforcement learning (RL) algorithms for continuous control tasks require accurate sampling-based action selection. Many tasks, such as robotic manipulation, contain inherent problem symmetries. However, correctly incorporating symmetry into sampling-based approaches remains a challenge. This work addresses the challenge of preserving symmetry in sampling-based planning and control, a key component for enhancing decision-making efficiency in RL. We introduce an action sampling approach that enforces the desired symmetry. We apply our proposed method to a coordinate regression problem and show that the symmetry aware sampling method drastically outperforms the naive sampling approach. We furthermore develop a general framework for sampling-based model-based planning with Model Predictive Path Integral (MPPI). We compare our MPPI approach with standard sampling methods on several continuous control tasks. Empirical demonstrations across multiple continuous control environments validate the effectiveness of our approach, showcasing the importance of symmetry preservation in sampling-based action selection.
Learning to Navigate in Mazes with Novel Layouts using Abstract Top-down Maps
Dec 16, 2024Learning navigation capabilities in different environments has long been one of the major challenges in decision-making. In this work, we focus on zero-shot navigation ability using given abstract $2$-D top-down maps. Like human navigation by reading a paper map, the agent reads the map as an image when navigating in a novel layout, after learning to navigate on a set of training maps. We propose a model-based reinforcement learning approach for this multi-task learning problem, where it jointly learns a hypermodel that takes top-down maps as input and predicts the weights of the transition network. We use the DeepMind Lab environment and customize layouts using generated maps. Our method can adapt better to novel environments in zero-shot and is more robust to noise.
* Published at Reinforcement Learning Conference (RLC) 2024. Website: http://lfzhao.com/map-nav/
ThinkGrasp: A Vision-Language System for Strategic Part Grasping in Clutter
Jul 16, 2024



Robotic grasping in cluttered environments remains a significant challenge due to occlusions and complex object arrangements. We have developed ThinkGrasp, a plug-and-play vision-language grasping system that makes use of GPT-4o's advanced contextual reasoning for heavy clutter environment grasping strategies. ThinkGrasp can effectively identify and generate grasp poses for target objects, even when they are heavily obstructed or nearly invisible, by using goal-oriented language to guide the removal of obstructing objects. This approach progressively uncovers the target object and ultimately grasps it with a few steps and a high success rate. In both simulated and real experiments, ThinkGrasp achieved a high success rate and significantly outperformed state-of-the-art methods in heavily cluttered environments or with diverse unseen objects, demonstrating strong generalization capabilities.
Open-vocabulary Pick and Place via Patch-level Semantic Maps
Jun 21, 2024Controlling robots through natural language instructions in open-vocabulary scenarios is pivotal for enhancing human-robot collaboration and complex robot behavior synthesis. However, achieving this capability poses significant challenges due to the need for a system that can generalize from limited data to a wide range of tasks and environments. Existing methods rely on large, costly datasets and struggle with generalization. This paper introduces Grounded Equivariant Manipulation (GEM), a novel approach that leverages the generative capabilities of pre-trained vision-language models and geometric symmetries to facilitate few-shot and zero-shot learning for open-vocabulary robot manipulation tasks. Our experiments demonstrate GEM's high sample efficiency and superior generalization across diverse pick-and-place tasks in both simulation and real-world experiments, showcasing its ability to adapt to novel instructions and unseen objects with minimal data requirements. GEM advances a significant step forward in the domain of language-conditioned robot control, bridging the gap between semantic understanding and action generation in robotic systems.
Practice Makes Perfect: Planning to Learn Skill Parameter Policies
Feb 22, 2024One promising approach towards effective robot decision making in complex, long-horizon tasks is to sequence together parameterized skills. We consider a setting where a robot is initially equipped with (1) a library of parameterized skills, (2) an AI planner for sequencing together the skills given a goal, and (3) a very general prior distribution for selecting skill parameters. Once deployed, the robot should rapidly and autonomously learn to improve its performance by specializing its skill parameter selection policy to the particular objects, goals, and constraints in its environment. In this work, we focus on the active learning problem of choosing which skills to practice to maximize expected future task success. We propose that the robot should estimate the competence of each skill, extrapolate the competence (asking: "how much would the competence improve through practice?"), and situate the skill in the task distribution through competence-aware planning. This approach is implemented within a fully autonomous system where the robot repeatedly plans, practices, and learns without any environment resets. Through experiments in simulation, we find that our approach learns effective parameter policies more sample-efficiently than several baselines. Experiments in the real-world demonstrate our approach's ability to handle noise from perception and control and improve the robot's ability to solve two long-horizon mobile-manipulation tasks after a few hours of autonomous practice.
E(2)-Equivariant Graph Planning for Navigation
Sep 22, 2023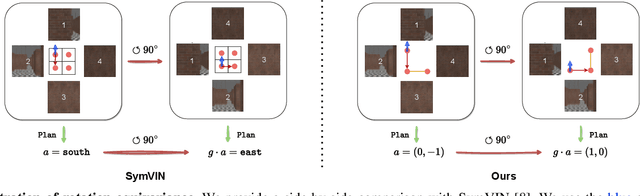
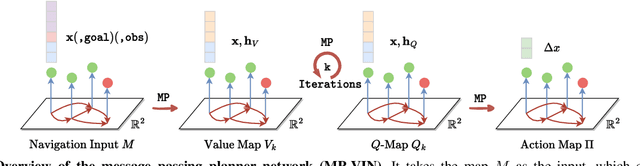
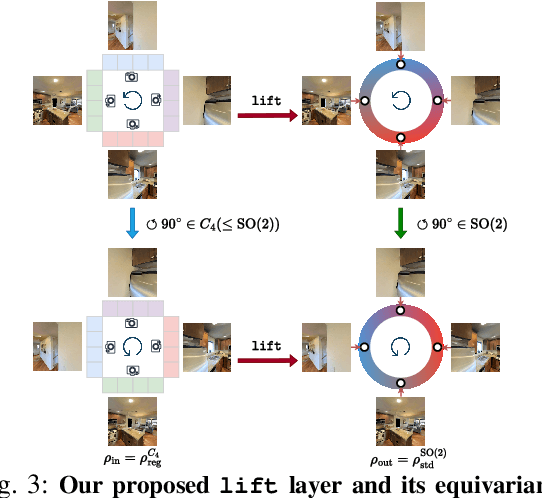

Learning for robot navigation presents a critical and challenging task. The scarcity and costliness of real-world datasets necessitate efficient learning approaches. In this letter, we exploit Euclidean symmetry in planning for 2D navigation, which originates from Euclidean transformations between reference frames and enables parameter sharing. To address the challenges of unstructured environments, we formulate the navigation problem as planning on a geometric graph and develop an equivariant message passing network to perform value iteration. Furthermore, to handle multi-camera input, we propose a learnable equivariant layer to lift features to a desired space. We conduct comprehensive evaluations across five diverse tasks encompassing structured and unstructured environments, along with maps of known and unknown, given point goals or semantic goals. Our experiments confirm the substantial benefits on training efficiency, stability, and generalization.
Can Euclidean Symmetry be Leveraged in Reinforcement Learning and Planning?
Jul 17, 2023In robotic tasks, changes in reference frames typically do not influence the underlying physical properties of the system, which has been known as invariance of physical laws.These changes, which preserve distance, encompass isometric transformations such as translations, rotations, and reflections, collectively known as the Euclidean group. In this work, we delve into the design of improved learning algorithms for reinforcement learning and planning tasks that possess Euclidean group symmetry. We put forth a theory on that unify prior work on discrete and continuous symmetry in reinforcement learning, planning, and optimal control. Algorithm side, we further extend the 2D path planning with value-based planning to continuous MDPs and propose a pipeline for constructing equivariant sampling-based planning algorithms. Our work is substantiated with empirical evidence and illustrated through examples that explain the benefits of equivariance to Euclidean symmetry in tackling natural control problems.