 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscovering Lie Groups with Flow Matching
Dec 23, 2025Symmetry is fundamental to understanding physical systems, and at the same time, can improve performance and sample efficiency in machine learning. Both pursuits require knowledge of the underlying symmetries in data. To address this, we propose learning symmetries directly from data via flow matching on Lie groups. We formulate symmetry discovery as learning a distribution over a larger hypothesis group, such that the learned distribution matches the symmetries observed in data. Relative to previous works, our method, \lieflow, is more flexible in terms of the types of groups it can discover and requires fewer assumptions. Experiments on 2D and 3D point clouds demonstrate the successful discovery of discrete groups, including reflections by flow matching over the complex domain. We identify a key challenge where the symmetric arrangement of the target modes causes ``last-minute convergence,'' where samples remain stationary until relatively late in the flow, and introduce a novel interpolation scheme for flow matching for symmetry discovery.
Two by Two: Learning Multi-Task Pairwise Objects Assembly for Generalizable Robot Manipulation
Apr 09, 20253D assembly tasks, such as furniture assembly and component fitting, play a crucial role in daily life and represent essential capabilities for future home robots. Existing benchmarks and datasets predominantly focus on assembling geometric fragments or factory parts, which fall short in addressing the complexities of everyday object interactions and assemblies. To bridge this gap, we present 2BY2, a large-scale annotated dataset for daily pairwise objects assembly, covering 18 fine-grained tasks that reflect real-life scenarios, such as plugging into sockets, arranging flowers in vases, and inserting bread into toasters. 2BY2 dataset includes 1,034 instances and 517 pairwise objects with pose and symmetry annotations, requiring approaches that align geometric shapes while accounting for functional and spatial relationships between objects. Leveraging the 2BY2 dataset, we propose a two-step SE(3) pose estimation method with equivariant features for assembly constraints. Compared to previous shape assembly methods, our approach achieves state-of-the-art performance across all 18 tasks in the 2BY2 dataset. Additionally, robot experiments further validate the reliability and generalization ability of our method for complex 3D assembly tasks.
Seeing is Believing: Belief-Space Planning with Foundation Models as Uncertainty Estimators
Apr 04, 2025Generalizable robotic mobile manipulation in open-world environments poses significant challenges due to long horizons, complex goals, and partial observability. A promising approach to address these challenges involves planning with a library of parameterized skills, where a task planner sequences these skills to achieve goals specified in structured languages, such as logical expressions over symbolic facts. While vision-language models (VLMs) can be used to ground these expressions, they often assume full observability, leading to suboptimal behavior when the agent lacks sufficient information to evaluate facts with certainty. This paper introduces a novel framework that leverages VLMs as a perception module to estimate uncertainty and facilitate symbolic grounding. Our approach constructs a symbolic belief representation and uses a belief-space planner to generate uncertainty-aware plans that incorporate strategic information gathering. This enables the agent to effectively reason about partial observability and property uncertainty. We demonstrate our system on a range of challenging real-world tasks that require reasoning in partially observable environments. Simulated evaluations show that our approach outperforms both vanilla VLM-based end-to-end planning or VLM-based state estimation baselines by planning for and executing strategic information gathering. This work highlights the potential of VLMs to construct belief-space symbolic scene representations, enabling downstream tasks such as uncertainty-aware planning.
Equivariant Action Sampling for Reinforcement Learning and Planning
Dec 16, 2024Reinforcement learning (RL) algorithms for continuous control tasks require accurate sampling-based action selection. Many tasks, such as robotic manipulation, contain inherent problem symmetries. However, correctly incorporating symmetry into sampling-based approaches remains a challenge. This work addresses the challenge of preserving symmetry in sampling-based planning and control, a key component for enhancing decision-making efficiency in RL. We introduce an action sampling approach that enforces the desired symmetry. We apply our proposed method to a coordinate regression problem and show that the symmetry aware sampling method drastically outperforms the naive sampling approach. We furthermore develop a general framework for sampling-based model-based planning with Model Predictive Path Integral (MPPI). We compare our MPPI approach with standard sampling methods on several continuous control tasks. Empirical demonstrations across multiple continuous control environments validate the effectiveness of our approach, showcasing the importance of symmetry preservation in sampling-based action selection.
Learning to Navigate in Mazes with Novel Layouts using Abstract Top-down Maps
Dec 16, 2024Learning navigation capabilities in different environments has long been one of the major challenges in decision-making. In this work, we focus on zero-shot navigation ability using given abstract $2$-D top-down maps. Like human navigation by reading a paper map, the agent reads the map as an image when navigating in a novel layout, after learning to navigate on a set of training maps. We propose a model-based reinforcement learning approach for this multi-task learning problem, where it jointly learns a hypermodel that takes top-down maps as input and predicts the weights of the transition network. We use the DeepMind Lab environment and customize layouts using generated maps. Our method can adapt better to novel environments in zero-shot and is more robust to noise.
* Published at Reinforcement Learning Conference (RLC) 2024. Website: http://lfzhao.com/map-nav/
Approximate Equivariance in Reinforcement Learning
Nov 06, 2024Equivariant neural networks have shown great success in reinforcement learning, improving sample efficiency and generalization when there is symmetry in the task. However, in many problems, only approximate symmetry is present, which makes imposing exact symmetry inappropriate. Recently, approximately equivariant networks have been proposed for supervised classification and modeling physical systems. In this work, we develop approximately equivariant algorithms in reinforcement learning (RL). We define approximately equivariant MDPs and theoretically characterize the effect of approximate equivariance on the optimal Q function. We propose novel RL architectures using relaxed group convolutions and experiment on several continuous control domains and stock trading with real financial data. Our results demonstrate that approximate equivariance matches prior work when exact symmetries are present, and outperforms them when domains exhibit approximate symmetry. As an added byproduct of these techniques, we observe increased robustness to noise at test time.
On-Robot Reinforcement Learning with Goal-Contrastive Rewards
Oct 25, 2024Reinforcement Learning (RL) has the potential to enable robots to learn from their own actions in the real world. Unfortunately, RL can be prohibitively expensive, in terms of on-robot runtime, due to inefficient exploration when learning from a sparse reward signal. Designing dense reward functions is labour-intensive and requires domain expertise. In our work, we propose GCR (Goal-Contrastive Rewards), a dense reward function learning method that can be trained on passive video demonstrations. By using videos without actions, our method is easier to scale, as we can use arbitrary videos. GCR combines two loss functions, an implicit value loss function that models how the reward increases when traversing a successful trajectory, and a goal-contrastive loss that discriminates between successful and failed trajectories. We perform experiments in simulated manipulation environments across RoboMimic and MimicGen tasks, as well as in the real world using a Franka arm and a Spot quadruped. We find that GCR leads to a more-sample efficient RL, enabling model-free RL to solve about twice as many tasks as our baseline reward learning methods. We also demonstrate positive cross-embodiment transfer from videos of people and of other robots performing a task. Appendix: \url{https://tinyurl.com/gcr-appendix-2}.
The Wallpaper is Ugly: Indoor Localization using Vision and Language
Oct 04, 2024We study the task of locating a user in a mapped indoor environment using natural language queries and images from the environment. Building on recent pretrained vision-language models, we learn a similarity score between text descriptions and images of locations in the environment. This score allows us to identify locations that best match the language query, estimating the user's location. Our approach is capable of localizing on environments, text, and images that were not seen during training. One model, finetuned CLIP, outperformed humans in our evaluation.
Modeling Dynamics over Meshes with Gauge Equivariant Nonlinear Message Passing
Nov 03, 2023



Data over non-Euclidean manifolds, often discretized as surface meshes, naturally arise in computer graphics and biological and physical systems. In particular, solutions to partial differential equations (PDEs) over manifolds depend critically on the underlying geometry. While graph neural networks have been successfully applied to PDEs, they do not incorporate surface geometry and do not consider local gauge symmetries of the manifold. Alternatively, recent works on gauge equivariant convolutional and attentional architectures on meshes leverage the underlying geometry but underperform in modeling surface PDEs with complex nonlinear dynamics. To address these issues, we introduce a new gauge equivariant architecture using nonlinear message passing. Our novel architecture achieves higher performance than either convolutional or attentional networks on domains with highly complex and nonlinear dynamics. However, similar to the non-mesh case, design trade-offs favor convolutional, attentional, or message passing networks for different tasks; we investigate in which circumstances our message passing method provides the most benefit.
Vision and Language Navigation in the Real World via Online Visual Language Mapping
Oct 16, 2023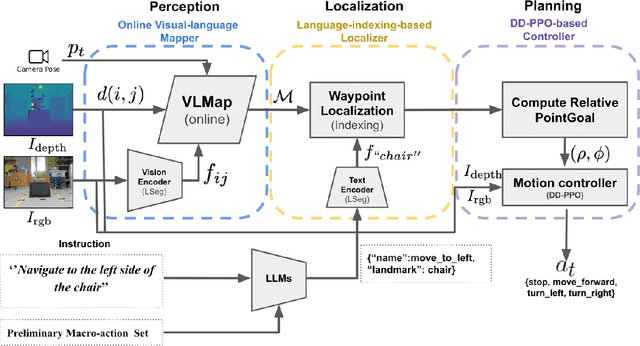


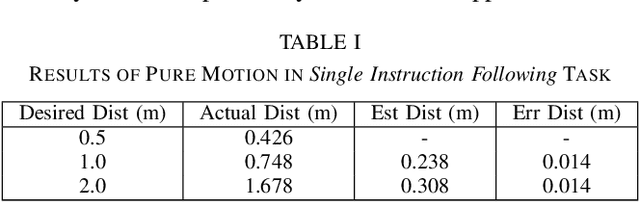
Navigating in unseen environments is crucial for mobile robots. Enhancing them with the ability to follow instructions in natural language will further improve navigation efficiency in unseen cases. However, state-of-the-art (SOTA) vision-and-language navigation (VLN) methods are mainly evaluated in simulation, neglecting the complex and noisy real world. Directly transferring SOTA navigation policies trained in simulation to the real world is challenging due to the visual domain gap and the absence of prior knowledge about unseen environments. In this work, we propose a novel navigation framework to address the VLN task in the real world. Utilizing the powerful foundation models, the proposed framework includes four key components: (1) an LLMs-based instruction parser that converts the language instruction into a sequence of pre-defined macro-action descriptions, (2) an online visual-language mapper that builds a real-time visual-language map to maintain a spatial and semantic understanding of the unseen environment, (3) a language indexing-based localizer that grounds each macro-action description into a waypoint location on the map, and (4) a DD-PPO-based local controller that predicts the action. We evaluate the proposed pipeline on an Interbotix LoCoBot WX250 in an unseen lab environment. Without any fine-tuning, our pipeline significantly outperforms the SOTA VLN baseline in the real world.