 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAffordGen: Generating Diverse Demonstrations for Generalizable Object Manipulation with Afford Correspondence
Apr 12, 2026Despite the recent success of modern imitation learning methods in robot manipulation, their performance is often constrained by geometric variations due to limited data diversity. Leveraging powerful 3D generative models and vision foundation models (VFMs), the proposed AffordGen framework overcomes this limitation by utilizing the semantic correspondence of meaningful keypoints across large-scale 3D meshes to generate new robot manipulation trajectories. This large-scale, affordance-aware dataset is then used to train a robust, closed-loop visuomotor policy, combining the semantic generalizability of affordances with the reactive robustness of end-to-end learning. Experiments in simulation and the real world show that policies trained with AffordGen achieve high success rates and enable zero-shot generalization to truly unseen objects, significantly improving data efficiency in robot learning.
MomaGraph: State-Aware Unified Scene Graphs with Vision-Language Model for Embodied Task Planning
Dec 18, 2025Mobile manipulators in households must both navigate and manipulate. This requires a compact, semantically rich scene representation that captures where objects are, how they function, and which parts are actionable. Scene graphs are a natural choice, yet prior work often separates spatial and functional relations, treats scenes as static snapshots without object states or temporal updates, and overlooks information most relevant for accomplishing the current task. To address these limitations, we introduce MomaGraph, a unified scene representation for embodied agents that integrates spatial-functional relationships and part-level interactive elements. However, advancing such a representation requires both suitable data and rigorous evaluation, which have been largely missing. We thus contribute MomaGraph-Scenes, the first large-scale dataset of richly annotated, task-driven scene graphs in household environments, along with MomaGraph-Bench, a systematic evaluation suite spanning six reasoning capabilities from high-level planning to fine-grained scene understanding. Built upon this foundation, we further develop MomaGraph-R1, a 7B vision-language model trained with reinforcement learning on MomaGraph-Scenes. MomaGraph-R1 predicts task-oriented scene graphs and serves as a zero-shot task planner under a Graph-then-Plan framework. Extensive experiments demonstrate that our model achieves state-of-the-art results among open-source models, reaching 71.6% accuracy on the benchmark (+11.4% over the best baseline), while generalizing across public benchmarks and transferring effectively to real-robot experiments.
Lemon: A Unified and Scalable 3D Multimodal Model for Universal Spatial Understanding
Dec 14, 2025Scaling large multimodal models (LMMs) to 3D understanding poses unique challenges: point cloud data is sparse and irregular, existing models rely on fragmented architectures with modality-specific encoders, and training pipelines often suffer from instability and poor scalability. We introduce Lemon, a unified transformer architecture that addresses these challenges by jointly processing 3D point cloud patches and language tokens as a single sequence. Unlike prior work that relies on modality-specific encoders and cross-modal alignment modules, this design enables early spatial-linguistic fusion, eliminates redundant encoders, improves parameter efficiency, and supports more effective model scaling. To handle the complexity of 3D data, we develop a structured patchification and tokenization scheme that preserves spatial context, and a three-stage training curriculum that progressively builds capabilities from object-level recognition to scene-level spatial reasoning. Lemon establishes new state-of-the-art performance across comprehensive 3D understanding and reasoning tasks, from object recognition and captioning to spatial reasoning in 3D scenes, while demonstrating robust scaling properties as model size and training data increase. Our work provides a unified foundation for advancing 3D spatial intelligence in real-world applications.
Two by Two: Learning Multi-Task Pairwise Objects Assembly for Generalizable Robot Manipulation
Apr 09, 2025



3D assembly tasks, such as furniture assembly and component fitting, play a crucial role in daily life and represent essential capabilities for future home robots. Existing benchmarks and datasets predominantly focus on assembling geometric fragments or factory parts, which fall short in addressing the complexities of everyday object interactions and assemblies. To bridge this gap, we present 2BY2, a large-scale annotated dataset for daily pairwise objects assembly, covering 18 fine-grained tasks that reflect real-life scenarios, such as plugging into sockets, arranging flowers in vases, and inserting bread into toasters. 2BY2 dataset includes 1,034 instances and 517 pairwise objects with pose and symmetry annotations, requiring approaches that align geometric shapes while accounting for functional and spatial relationships between objects. Leveraging the 2BY2 dataset, we propose a two-step SE(3) pose estimation method with equivariant features for assembly constraints. Compared to previous shape assembly methods, our approach achieves state-of-the-art performance across all 18 tasks in the 2BY2 dataset. Additionally, robot experiments further validate the reliability and generalization ability of our method for complex 3D assembly tasks.
GRACE: Generalizing Robot-Assisted Caregiving with User Functionality Embeddings
Jan 29, 2025
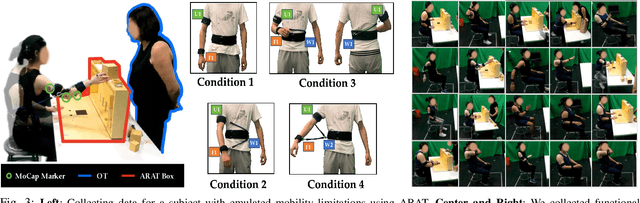


Robot caregiving should be personalized to meet the diverse needs of care recipients -- assisting with tasks as needed, while taking user agency in action into account. In physical tasks such as handover, bathing, dressing, and rehabilitation, a key aspect of this diversity is the functional range of motion (fROM), which can vary significantly between individuals. In this work, we learn to predict personalized fROM as a way to generalize robot decision-making in a wide range of caregiving tasks. We propose a novel data-driven method for predicting personalized fROM using functional assessment scores from occupational therapy. We develop a neural model that learns to embed functional assessment scores into a latent representation of the user's physical function. The model is trained using motion capture data collected from users with emulated mobility limitations. After training, the model predicts personalized fROM for new users without motion capture. Through simulated experiments and a real-robot user study, we show that the personalized fROM predictions from our model enable the robot to provide personalized and effective assistance while improving the user's agency in action. See our website for more visualizations: https://emprise.cs.cornell.edu/grace/.
DenseMatcher: Learning 3D Semantic Correspondence for Category-Level Manipulation from a Single Demo
Dec 06, 2024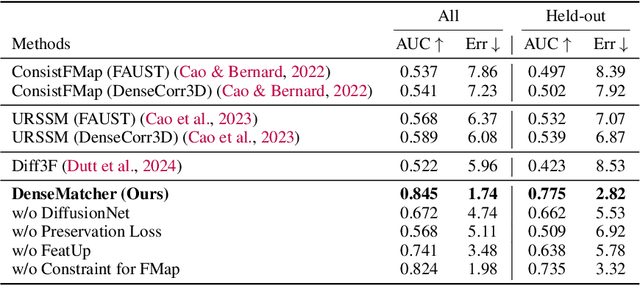


Dense 3D correspondence can enhance robotic manipulation by enabling the generalization of spatial, functional, and dynamic information from one object to an unseen counterpart. Compared to shape correspondence, semantic correspondence is more effective in generalizing across different object categories. To this end, we present DenseMatcher, a method capable of computing 3D correspondences between in-the-wild objects that share similar structures. DenseMatcher first computes vertex features by projecting multiview 2D features onto meshes and refining them with a 3D network, and subsequently finds dense correspondences with the obtained features using functional map. In addition, we craft the first 3D matching dataset that contains colored object meshes across diverse categories. In our experiments, we show that DenseMatcher significantly outperforms prior 3D matching baselines by 43.5%. We demonstrate the downstream effectiveness of DenseMatcher in (i) robotic manipulation, where it achieves cross-instance and cross-category generalization on long-horizon complex manipulation tasks from observing only one demo; (ii) zero-shot color mapping between digital assets, where appearance can be transferred between different objects with relatable geometry.
Robo-ABC: Affordance Generalization Beyond Categories via Semantic Correspondence for Robot Manipulation
Jan 15, 2024



Enabling robotic manipulation that generalizes to out-of-distribution scenes is a crucial step toward open-world embodied intelligence. For human beings, this ability is rooted in the understanding of semantic correspondence among objects, which naturally transfers the interaction experience of familiar objects to novel ones. Although robots lack such a reservoir of interaction experience, the vast availability of human videos on the Internet may serve as a valuable resource, from which we extract an affordance memory including the contact points. Inspired by the natural way humans think, we propose Robo-ABC: when confronted with unfamiliar objects that require generalization, the robot can acquire affordance by retrieving objects that share visual or semantic similarities from the affordance memory. The next step is to map the contact points of the retrieved objects to the new object. While establishing this correspondence may present formidable challenges at first glance, recent research finds it naturally arises from pre-trained diffusion models, enabling affordance mapping even across disparate object categories. Through the Robo-ABC framework, robots may generalize to manipulate out-of-category objects in a zero-shot manner without any manual annotation, additional training, part segmentation, pre-coded knowledge, or viewpoint restrictions. Quantitatively, Robo-ABC significantly enhances the accuracy of visual affordance retrieval by a large margin of 31.6% compared to state-of-the-art (SOTA) end-to-end affordance models. We also conduct real-world experiments of cross-category object-grasping tasks. Robo-ABC achieved a success rate of 85.7%, proving its capacity for real-world tasks.
ArrayBot: Reinforcement Learning for Generalizable Distributed Manipulation through Touch
Jun 29, 2023


We present ArrayBot, a distributed manipulation system consisting of a $16 \times 16$ array of vertically sliding pillars integrated with tactile sensors, which can simultaneously support, perceive, and manipulate the tabletop objects. Towards generalizable distributed manipulation, we leverage reinforcement learning (RL) algorithms for the automatic discovery of control policies. In the face of the massively redundant actions, we propose to reshape the action space by considering the spatially local action patch and the low-frequency actions in the frequency domain. With this reshaped action space, we train RL agents that can relocate diverse objects through tactile observations only. Surprisingly, we find that the discovered policy can not only generalize to unseen object shapes in the simulator but also transfer to the physical robot without any domain randomization. Leveraging the deployed policy, we present abundant real-world manipulation tasks, illustrating the vast potential of RL on ArrayBot for distributed manipulation.
IRRGN: An Implicit Relational Reasoning Graph Network for Multi-turn Response Selection
Dec 01, 2022



The task of response selection in multi-turn dialogue is to find the best option from all candidates. In order to improve the reasoning ability of the model, previous studies pay more attention to using explicit algorithms to model the dependencies between utterances, which are deterministic, limited and inflexible. In addition, few studies consider differences between the options before and after reasoning. In this paper, we propose an Implicit Relational Reasoning Graph Network to address these issues, which consists of the Utterance Relational Reasoner (URR) and the Option Dual Comparator (ODC). URR aims to implicitly extract dependencies between utterances, as well as utterances and options, and make reasoning with relational graph convolutional networks. ODC focuses on perceiving the difference between the options through dual comparison, which can eliminate the interference of the noise options. Experimental results on two multi-turn dialogue reasoning benchmark datasets MuTual and MuTual+ show that our method significantly improves the baseline of four pretrained language models and achieves state-of-the-art performance. The model surpasses human performance for the first time on the MuTual dataset.