 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFailure-Aware RL: Reliable Offline-to-Online Reinforcement Learning with Self-Recovery for Real-World Manipulation
Jan 12, 2026Post-training algorithms based on deep reinforcement learning can push the limits of robotic models for specific objectives, such as generalizability, accuracy, and robustness. However, Intervention-requiring Failures (IR Failures) (e.g., a robot spilling water or breaking fragile glass) during real-world exploration happen inevitably, hindering the practical deployment of such a paradigm. To tackle this, we introduce Failure-Aware Offline-to-Online Reinforcement Learning (FARL), a new paradigm minimizing failures during real-world reinforcement learning. We create FailureBench, a benchmark that incorporates common failure scenarios requiring human intervention, and propose an algorithm that integrates a world-model-based safety critic and a recovery policy trained offline to prevent failures during online exploration. Extensive simulation and real-world experiments demonstrate the effectiveness of FARL in significantly reducing IR Failures while improving performance and generalization during online reinforcement learning post-training. FARL reduces IR Failures by 73.1% while elevating performance by 11.3% on average during real-world RL post-training. Videos and code are available at https://failure-aware-rl.github.io.
Robot Trains Robot: Automatic Real-World Policy Adaptation and Learning for Humanoids
Aug 17, 2025Simulation-based reinforcement learning (RL) has significantly advanced humanoid locomotion tasks, yet direct real-world RL from scratch or adapting from pretrained policies remains rare, limiting the full potential of humanoid robots. Real-world learning, despite being crucial for overcoming the sim-to-real gap, faces substantial challenges related to safety, reward design, and learning efficiency. To address these limitations, we propose Robot-Trains-Robot (RTR), a novel framework where a robotic arm teacher actively supports and guides a humanoid robot student. The RTR system provides protection, learning schedule, reward, perturbation, failure detection, and automatic resets. It enables efficient long-term real-world humanoid training with minimal human intervention. Furthermore, we propose a novel RL pipeline that facilitates and stabilizes sim-to-real transfer by optimizing a single dynamics-encoded latent variable in the real world. We validate our method through two challenging real-world humanoid tasks: fine-tuning a walking policy for precise speed tracking and learning a humanoid swing-up task from scratch, illustrating the promising capabilities of real-world humanoid learning realized by RTR-style systems. See https://robot-trains-robot.github.io/ for more info.
DenseMatcher: Learning 3D Semantic Correspondence for Category-Level Manipulation from a Single Demo
Dec 06, 2024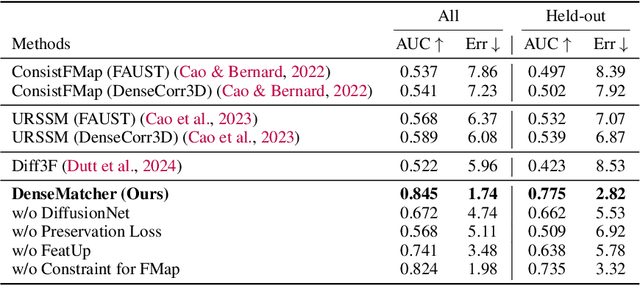


Dense 3D correspondence can enhance robotic manipulation by enabling the generalization of spatial, functional, and dynamic information from one object to an unseen counterpart. Compared to shape correspondence, semantic correspondence is more effective in generalizing across different object categories. To this end, we present DenseMatcher, a method capable of computing 3D correspondences between in-the-wild objects that share similar structures. DenseMatcher first computes vertex features by projecting multiview 2D features onto meshes and refining them with a 3D network, and subsequently finds dense correspondences with the obtained features using functional map. In addition, we craft the first 3D matching dataset that contains colored object meshes across diverse categories. In our experiments, we show that DenseMatcher significantly outperforms prior 3D matching baselines by 43.5%. We demonstrate the downstream effectiveness of DenseMatcher in (i) robotic manipulation, where it achieves cross-instance and cross-category generalization on long-horizon complex manipulation tasks from observing only one demo; (ii) zero-shot color mapping between digital assets, where appearance can be transferred between different objects with relatable geometry.
Stem-OB: Generalizable Visual Imitation Learning with Stem-Like Convergent Observation through Diffusion Inversion
Nov 07, 2024


Visual imitation learning methods demonstrate strong performance, yet they lack generalization when faced with visual input perturbations, including variations in lighting and textures, impeding their real-world application. We propose Stem-OB that utilizes pretrained image diffusion models to suppress low-level visual differences while maintaining high-level scene structures. This image inversion process is akin to transforming the observation into a shared representation, from which other observations stem, with extraneous details removed. Stem-OB contrasts with data-augmentation approaches as it is robust to various unspecified appearance changes without the need for additional training. Our method is a simple yet highly effective plug-and-play solution. Empirical results confirm the effectiveness of our approach in simulated tasks and show an exceptionally significant improvement in real-world applications, with an average increase of 22.2% in success rates compared to the best baseline. See https://hukz18.github.io/Stem-Ob/ for more info.
Make-An-Agent: A Generalizable Policy Network Generator with Behavior-Prompted Diffusion
Jul 15, 2024Can we generate a control policy for an agent using just one demonstration of desired behaviors as a prompt, as effortlessly as creating an image from a textual description? In this paper, we present Make-An-Agent, a novel policy parameter generator that leverages the power of conditional diffusion models for behavior-to-policy generation. Guided by behavior embeddings that encode trajectory information, our policy generator synthesizes latent parameter representations, which can then be decoded into policy networks. Trained on policy network checkpoints and their corresponding trajectories, our generation model demonstrates remarkable versatility and scalability on multiple tasks and has a strong generalization ability on unseen tasks to output well-performed policies with only few-shot demonstrations as inputs. We showcase its efficacy and efficiency on various domains and tasks, including varying objectives, behaviors, and even across different robot manipulators. Beyond simulation, we directly deploy policies generated by Make-An-Agent onto real-world robots on locomotion tasks.
Rethinking Transformers in Solving POMDPs
May 30, 2024



Sequential decision-making algorithms such as reinforcement learning (RL) in real-world scenarios inevitably face environments with partial observability. This paper scrutinizes the effectiveness of a popular architecture, namely Transformers, in Partially Observable Markov Decision Processes (POMDPs) and reveals its theoretical limitations. We establish that regular languages, which Transformers struggle to model, are reducible to POMDPs. This poses a significant challenge for Transformers in learning POMDP-specific inductive biases, due to their lack of inherent recurrence found in other models like RNNs. This paper casts doubt on the prevalent belief in Transformers as sequence models for RL and proposes to introduce a point-wise recurrent structure. The Deep Linear Recurrent Unit (LRU) emerges as a well-suited alternative for Partially Observable RL, with empirical results highlighting the sub-optimal performance of the Transformer and considerable strength of LRU.
Robo-ABC: Affordance Generalization Beyond Categories via Semantic Correspondence for Robot Manipulation
Jan 15, 2024



Enabling robotic manipulation that generalizes to out-of-distribution scenes is a crucial step toward open-world embodied intelligence. For human beings, this ability is rooted in the understanding of semantic correspondence among objects, which naturally transfers the interaction experience of familiar objects to novel ones. Although robots lack such a reservoir of interaction experience, the vast availability of human videos on the Internet may serve as a valuable resource, from which we extract an affordance memory including the contact points. Inspired by the natural way humans think, we propose Robo-ABC: when confronted with unfamiliar objects that require generalization, the robot can acquire affordance by retrieving objects that share visual or semantic similarities from the affordance memory. The next step is to map the contact points of the retrieved objects to the new object. While establishing this correspondence may present formidable challenges at first glance, recent research finds it naturally arises from pre-trained diffusion models, enabling affordance mapping even across disparate object categories. Through the Robo-ABC framework, robots may generalize to manipulate out-of-category objects in a zero-shot manner without any manual annotation, additional training, part segmentation, pre-coded knowledge, or viewpoint restrictions. Quantitatively, Robo-ABC significantly enhances the accuracy of visual affordance retrieval by a large margin of 31.6% compared to state-of-the-art (SOTA) end-to-end affordance models. We also conduct real-world experiments of cross-category object-grasping tasks. Robo-ABC achieved a success rate of 85.7%, proving its capacity for real-world tasks.
Uni-O4: Unifying Online and Offline Deep Reinforcement Learning with Multi-Step On-Policy Optimization
Nov 06, 2023Combining offline and online reinforcement learning (RL) is crucial for efficient and safe learning. However, previous approaches treat offline and online learning as separate procedures, resulting in redundant designs and limited performance. We ask: Can we achieve straightforward yet effective offline and online learning without introducing extra conservatism or regularization? In this study, we propose Uni-o4, which utilizes an on-policy objective for both offline and online learning. Owning to the alignment of objectives in two phases, the RL agent can transfer between offline and online learning seamlessly. This property enhances the flexibility of the learning paradigm, allowing for arbitrary combinations of pretraining, fine-tuning, offline, and online learning. In the offline phase, specifically, Uni-o4 leverages diverse ensemble policies to address the mismatch issues between the estimated behavior policy and the offline dataset. Through a simple offline policy evaluation (OPE) approach, Uni-o4 can achieve multi-step policy improvement safely. We demonstrate that by employing the method above, the fusion of these two paradigms can yield superior offline initialization as well as stable and rapid online fine-tuning capabilities. Through real-world robot tasks, we highlight the benefits of this paradigm for rapid deployment in challenging, previously unseen real-world environments. Additionally, through comprehensive evaluations using numerous simulated benchmarks, we substantiate that our method achieves state-of-the-art performance in both offline and offline-to-online fine-tuning learning. Our website: https://lei-kun.github.io/uni-o4/ .
RL-ViGen: A Reinforcement Learning Benchmark for Visual Generalization
Jul 15, 2023Visual Reinforcement Learning (Visual RL), coupled with high-dimensional observations, has consistently confronted the long-standing challenge of generalization. Despite the focus on algorithms aimed at resolving visual generalization problems, we argue that the devil is in the existing benchmarks as they are restricted to isolated tasks and generalization categories, undermining a comprehensive evaluation of agents' visual generalization capabilities. To bridge this gap, we introduce RL-ViGen: a novel Reinforcement Learning Benchmark for Visual Generalization, which contains diverse tasks and a wide spectrum of generalization types, thereby facilitating the derivation of more reliable conclusions. Furthermore, RL-ViGen incorporates the latest generalization visual RL algorithms into a unified framework, under which the experiment results indicate that no single existing algorithm has prevailed universally across tasks. Our aspiration is that RL-ViGen will serve as a catalyst in this area, and lay a foundation for the future creation of universal visual generalization RL agents suitable for real-world scenarios. Access to our code and implemented algorithms is provided at https://gemcollector.github.io/RL-ViGen/.
Can Pre-Trained Text-to-Image Models Generate Visual Goals for Reinforcement Learning?
Jul 15, 2023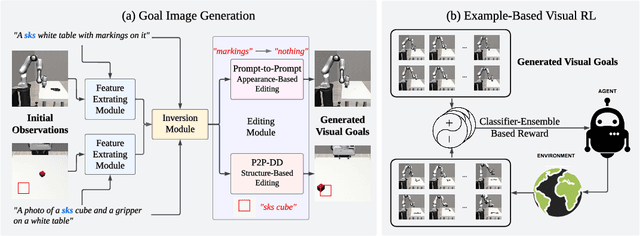



Pre-trained text-to-image generative models can produce diverse, semantically rich, and realistic images from natural language descriptions. Compared with language, images usually convey information with more details and less ambiguity. In this study, we propose Learning from the Void (LfVoid), a method that leverages the power of pre-trained text-to-image models and advanced image editing techniques to guide robot learning. Given natural language instructions, LfVoid can edit the original observations to obtain goal images, such as "wiping" a stain off a table. Subsequently, LfVoid trains an ensembled goal discriminator on the generated image to provide reward signals for a reinforcement learning agent, guiding it to achieve the goal. The ability of LfVoid to learn with zero in-domain training on expert demonstrations or true goal observations (the void) is attributed to the utilization of knowledge from web-scale generative models. We evaluate LfVoid across three simulated tasks and validate its feasibility in the corresponding real-world scenarios. In addition, we offer insights into the key considerations for the effective integration of visual generative models into robot learning workflows. We posit that our work represents an initial step towards the broader application of pre-trained visual generative models in the robotics field. Our project page: https://lfvoid-rl.github.io/.