 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDenseMatcher: Learning 3D Semantic Correspondence for Category-Level Manipulation from a Single Demo
Dec 06, 2024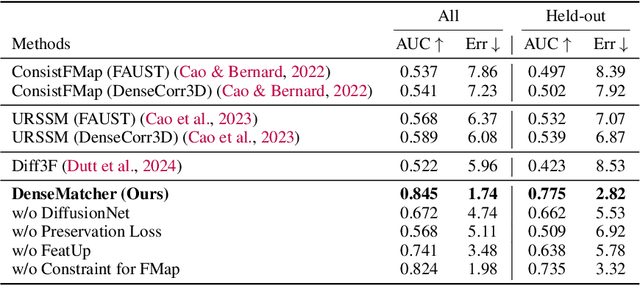

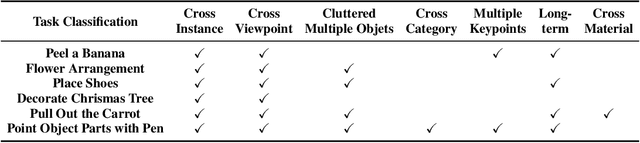

Dense 3D correspondence can enhance robotic manipulation by enabling the generalization of spatial, functional, and dynamic information from one object to an unseen counterpart. Compared to shape correspondence, semantic correspondence is more effective in generalizing across different object categories. To this end, we present DenseMatcher, a method capable of computing 3D correspondences between in-the-wild objects that share similar structures. DenseMatcher first computes vertex features by projecting multiview 2D features onto meshes and refining them with a 3D network, and subsequently finds dense correspondences with the obtained features using functional map. In addition, we craft the first 3D matching dataset that contains colored object meshes across diverse categories. In our experiments, we show that DenseMatcher significantly outperforms prior 3D matching baselines by 43.5%. We demonstrate the downstream effectiveness of DenseMatcher in (i) robotic manipulation, where it achieves cross-instance and cross-category generalization on long-horizon complex manipulation tasks from observing only one demo; (ii) zero-shot color mapping between digital assets, where appearance can be transferred between different objects with relatable geometry.
HiFA: High-fidelity Text-to-3D with Advanced Diffusion Guidance
May 31, 2023



Automatic text-to-3D synthesis has achieved remarkable advancements through the optimization of 3D models. Existing methods commonly rely on pre-trained text-to-image generative models, such as diffusion models, providing scores for 2D renderings of Neural Radiance Fields (NeRFs) and being utilized for optimizing NeRFs. However, these methods often encounter artifacts and inconsistencies across multiple views due to their limited understanding of 3D geometry. To address these limitations, we propose a reformulation of the optimization loss using the diffusion prior. Furthermore, we introduce a novel training approach that unlocks the potential of the diffusion prior. To improve 3D geometry representation, we apply auxiliary depth supervision for NeRF-rendered images and regularize the density field of NeRFs. Extensive experiments demonstrate the superiority of our method over prior works, resulting in advanced photo-realism and improved multi-view consistency.
See, Hear, and Feel: Smart Sensory Fusion for Robotic Manipulation
Dec 08, 2022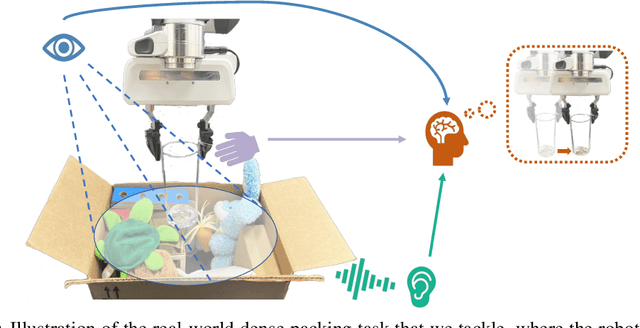
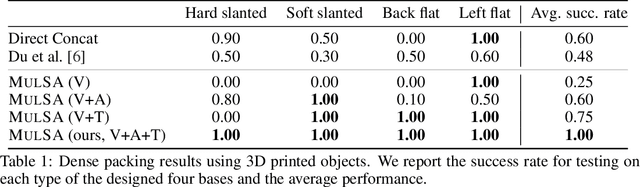
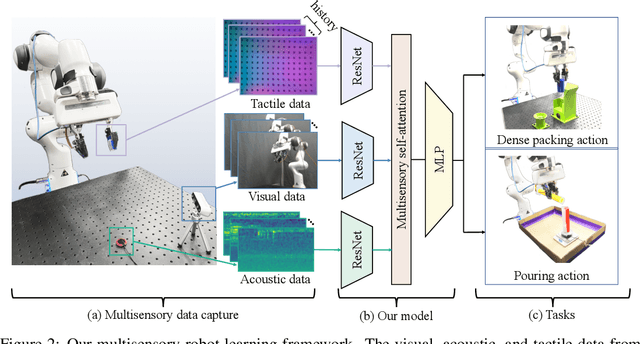

Humans use all of their senses to accomplish different tasks in everyday activities. In contrast, existing work on robotic manipulation mostly relies on one, or occasionally two modalities, such as vision and touch. In this work, we systematically study how visual, auditory, and tactile perception can jointly help robots to solve complex manipulation tasks. We build a robot system that can see with a camera, hear with a contact microphone, and feel with a vision-based tactile sensor, with all three sensory modalities fused with a self-attention model. Results on two challenging tasks, dense packing and pouring, demonstrate the necessity and power of multisensory perception for robotic manipulation: vision displays the global status of the robot but can often suffer from occlusion, audio provides immediate feedback of key moments that are even invisible, and touch offers precise local geometry for decision making. Leveraging all three modalities, our robotic system significantly outperforms prior methods.
Multi-Decoder DPRNN: High Accuracy Source Counting and Separation
Nov 30, 2020
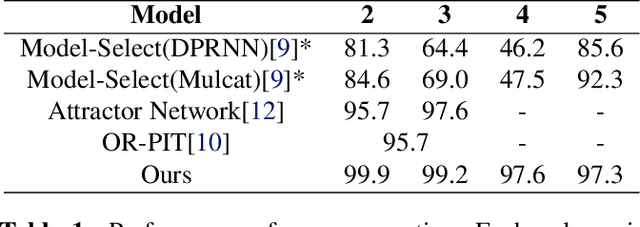
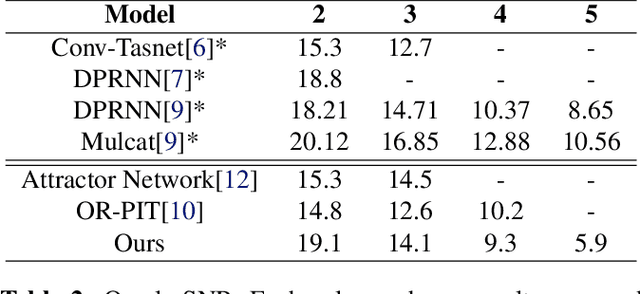

We propose an end-to-end trainable approach to single-channel speech separation with unknown number of speakers. Our approach extends the MulCat source separation backbone with additional output heads: a count-head to infer the number of speakers, and decoder-heads for reconstructing the original signals. Beyond the model, we also propose a metric on how to evaluate source separation with variable number of speakers. Specifically, we cleared up the issue on how to evaluate the quality when the ground-truth hasmore or less speakers than the ones predicted by the model. We evaluate our approach on the WSJ0-mix datasets, with mixtures up to five speakers. We demonstrate that our approach outperforms state-of-the-art in counting the number of speakers and remains competitive in quality of reconstructed signals.
Identify Speakers in Cocktail Parties with End-to-End Attention
May 22, 2020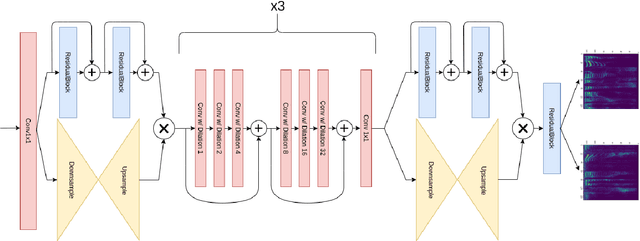
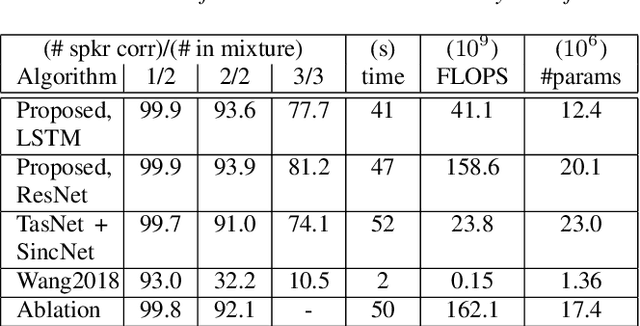
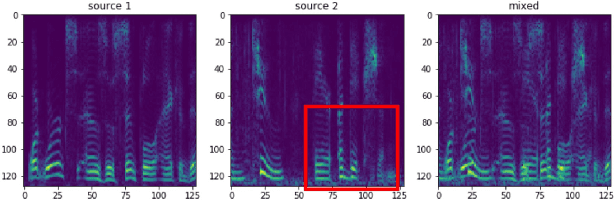
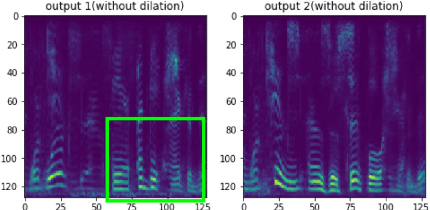
In scenarios where multiple speakers talk at the same time, it is important to be able to identify the talkers accurately. This paper presents an end-to-end system that integrates speech source extraction and speaker identification, and proposes a new way to jointly optimize these two parts by max-pooling the speaker predictions along the channel dimension. Residual attention permits us to learn spectrogram masks that are optimized for the purpose of speaker identification, while residual forward connections permit dilated convolution with a sufficiently large context window to guarantee correct streaming across syllable boundaries. End-to-end training results in a system that recognizes one speaker in a two-speaker broadcast speech mixture with 99.9% accuracy and both speakers with 93.9% accuracy, and that recognizes all speakers in three-speaker scenarios with 81.2% accuracy.